 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection for Value Function Approximation Using Bayesian Model Selection
Paper and Code
Jan 31, 2012


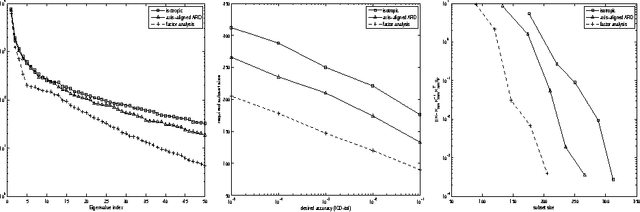
Feature selection in reinforcement learning (RL), i.e. choosing basis functions such that useful approximations of the unkown value function can be obtained, is one of the main challenges in scaling RL to real-world applications. Here we consider the Gaussian process based framework GPTD for approximate policy evaluation, and propose feature selection through marginal likelihood optimization of the associated hyperparameters. Our approach has two appealing benefits: (1) given just sample transitions, we can solve the policy evaluation problem fully automatically (without looking at the learning task, and, in theory, independent of the dimensionality of the state space), and (2) model selection allows us to consider more sophisticated kernels, which in turn enable us to identify relevant subspaces and eliminate irrelevant state variables such that we can achieve substantial computational savings and improved prediction performance.