 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning RoboCup-Keepaway with Kernels
Paper and Code
Jan 31, 2012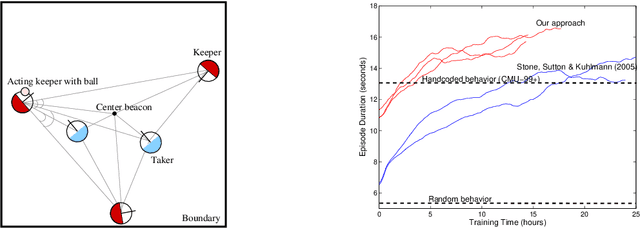
We apply kernel-based methods to solve the difficult reinforcement learning problem of 3vs2 keepaway in RoboCup simulated soccer. Key challenges in keepaway are the high-dimensionality of the state space (rendering conventional discretization-based function approximation like tilecoding infeasible), the stochasticity due to noise and multiple learning agents needing to cooperate (meaning that the exact dynamics of the environment are unknown) and real-time learning (meaning that an efficient online implementation is required). We employ the general framework of approximate policy iteration with least-squares-based policy evaluation. As underlying function approximator we consider the family of regularization networks with subset of regressors approximation. The core of our proposed solution is an efficient recursive implementation with automatic supervised selection of relevant basis functions. Simulation results indicate that the behavior learned through our approach clearly outperforms the best results obtained earlier with tilecoding by Stone et al. (2005).