 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallelizable memory recurrent units
Jan 14, 2026With the emergence of massively parallel processing units, parallelization has become a desirable property for new sequence models. The ability to parallelize the processing of sequences with respect to the sequence length during training is one of the main factors behind the uprising of the Transformer architecture. However, Transformers lack efficiency at sequence generation, as they need to reprocess all past timesteps at every generation step. Recently, state-space models (SSMs) emerged as a more efficient alternative. These new kinds of recurrent neural networks (RNNs) keep the efficient update of the RNNs while gaining parallelization by getting rid of nonlinear dynamics (or recurrence). SSMs can reach state-of-the art performance through the efficient training of potentially very large networks, but still suffer from limited representation capabilities. In particular, SSMs cannot exhibit persistent memory, or the capacity of retaining information for an infinite duration, because of their monostability. In this paper, we introduce a new family of RNNs, the memory recurrent units (MRUs), that combine the persistent memory capabilities of nonlinear RNNs with the parallelizable computations of SSMs. These units leverage multistability as a source of persistent memory, while getting rid of transient dynamics for efficient computations. We then derive a specific implementation as proof-of-concept: the bistable memory recurrent unit (BMRU). This new RNN is compatible with the parallel scan algorithm. We show that BMRU achieves good results in tasks with long-term dependencies, and can be combined with state-space models to create hybrid networks that are parallelizable and have transient dynamics as well as persistent memory.
A Theoretical Justification for Asymmetric Actor-Critic Algorithms
Jan 31, 2025In reinforcement learning for partially observable environments, many successful algorithms were developed within the asymmetric learning paradigm. This paradigm leverages additional state information available at training time for faster learning. Although the proposed learning objectives are usually theoretically sound, these methods still lack a theoretical justification for their potential benefits. We propose such a justification for asymmetric actor-critic algorithms with linear function approximators by adapting a finite-time convergence analysis to this setting. The resulting finite-time bound reveals that the asymmetric critic eliminates an error term arising from aliasing in the agent state.
Off-Policy Maximum Entropy RL with Future State and Action Visitation Measures
Dec 09, 2024We introduce a new maximum entropy reinforcement learning framework based on the distribution of states and actions visited by a policy. More precisely, an intrinsic reward function is added to the reward function of the Markov decision process that shall be controlled. For each state and action, this intrinsic reward is the relative entropy of the discounted distribution of states and actions (or features from these states and actions) visited during the next time steps. We first prove that an optimal exploration policy, which maximizes the expected discounted sum of intrinsic rewards, is also a policy that maximizes a lower bound on the state-action value function of the decision process under some assumptions. We also prove that the visitation distribution used in the intrinsic reward definition is the fixed point of a contraction operator. Following, we describe how to adapt existing algorithms to learn this fixed point and compute the intrinsic rewards to enhance exploration. A new practical off-policy maximum entropy reinforcement learning algorithm is finally introduced. Empirically, exploration policies have good state-action space coverage, and high-performing control policies are computed efficiently.
Parallelizing Autoregressive Generation with Variational State Space Models
Jul 11, 2024Attention-based models such as Transformers and recurrent models like state space models (SSMs) have emerged as successful methods for autoregressive sequence modeling. Although both enable parallel training, none enable parallel generation due to their autoregressiveness. We propose the variational SSM (VSSM), a variational autoencoder (VAE) where both the encoder and decoder are SSMs. Since sampling the latent variables and decoding them with the SSM can be parallelized, both training and generation can be conducted in parallel. Moreover, the decoder recurrence allows generation to be resumed without reprocessing the whole sequence. Finally, we propose the autoregressive VSSM that can be conditioned on a partial realization of the sequence, as is common in language generation tasks. Interestingly, the autoregressive VSSM still enables parallel generation. We highlight on toy problems (MNIST, CIFAR) the empirical gains in speed-up and show that it competes with traditional models in terms of generation quality (Transformer, Mamba SSM).
* 4 pages, 11 pages total, 3 figures
Reinforcement Learning to improve delta robot throws for sorting scrap metal
Jun 19, 2024



This study proposes a novel approach based on reinforcement learning (RL) to enhance the sorting efficiency of scrap metal using delta robots and a Pick-and-Place (PaP) process, widely used in the industry. We use three classical model-free RL algorithms (TD3, SAC and PPO) to reduce the time to sort metal scraps. We learn the release position and speed needed to throw an object in a bin instead of moving to the exact bin location, as with the classical PaP technique. Our contribution is threefold. First, we provide a new simulation environment for learning RL-based Pick-and-Throw (PaT) strategies for parallel grippers. Second, we use RL algorithms for learning this task in this environment resulting in 89% accuracy while speeding up the throughput by 51% in simulation. Third, we evaluate the performances of RL algorithms and compare them to a PaP and a state-of-the-art PaT method both in simulation and reality, learning only from simulation with domain randomisation and without fine tuning in reality to transfer our policies. This work shows the benefits of RL-based PaT compared to PaP or classical optimization PaT techniques used in the industry.
Behind the Myth of Exploration in Policy Gradients
Jan 31, 2024



Policy-gradient algorithms are effective reinforcement learning methods for solving control problems with continuous state and action spaces. To compute near-optimal policies, it is essential in practice to include exploration terms in the learning objective. Although the effectiveness of these terms is usually justified by an intrinsic need to explore environments, we propose a novel analysis and distinguish two different implications of these techniques. First, they make it possible to smooth the learning objective and to eliminate local optima while preserving the global maximum. Second, they modify the gradient estimates, increasing the probability that the stochastic parameter update eventually provides an optimal policy. In light of these effects, we discuss and illustrate empirically exploration strategies based on entropy bonuses, highlighting their limitations and opening avenues for future works in the design and analysis of such strategies.
Informed POMDP: Leveraging Additional Information in Model-Based RL
Jun 24, 2023



In this work, we generalize the problem of learning through interaction in a POMDP by accounting for eventual additional information available at training time. First, we introduce the informed POMDP, a new learning paradigm offering a clear distinction between the training information and the execution observation. Next, we propose an objective for learning a sufficient statistic from the history for the optimal control that leverages this information. We then show that this informed objective consists of learning an environment model from which we can sample latent trajectories. Finally, we show for the Dreamer algorithm that the convergence speed of the policies is sometimes greatly improved on several environments by using this informed environment model. Those results and the simplicity of the proposed adaptation advocate for a systematic consideration of eventual additional information when learning in a POMDP using model-based RL.
Recurrent networks, hidden states and beliefs in partially observable environments
Aug 06, 2022

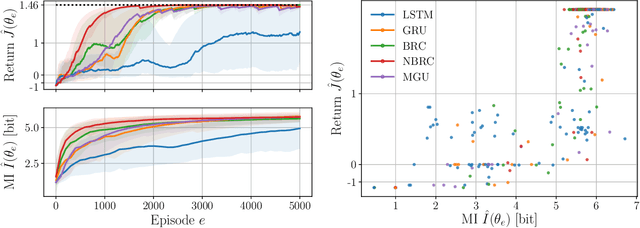

Reinforcement learning aims to learn optimal policies from interaction with environments whose dynamics are unknown. Many methods rely on the approximation of a value function to derive near-optimal policies. In partially observable environments, these functions depend on the complete sequence of observations and past actions, called the history. In this work, we show empirically that recurrent neural networks trained to approximate such value functions internally filter the posterior probability distribution of the current state given the history, called the belief. More precisely, we show that, as a recurrent neural network learns the Q-function, its hidden states become more and more correlated with the beliefs of state variables that are relevant to optimal control. This correlation is measured through their mutual information. In addition, we show that the expected return of an agent increases with the ability of its recurrent architecture to reach a high mutual information between its hidden states and the beliefs. Finally, we show that the mutual information between the hidden states and the beliefs of variables that are irrelevant for optimal control decreases through the learning process. In summary, this work shows that in its hidden states, a recurrent neural network approximating the Q-function of a partially observable environment reproduces a sufficient statistic from the history that is correlated to the relevant part of the belief for taking optimal actions.