 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Blame Problem in Evaluating Local Explanations, and How to Tackle it
Oct 05, 2023The number of local model-agnostic explanation techniques proposed has grown rapidly recently. One main reason is that the bar for developing new explainability techniques is low due to the lack of optimal evaluation measures. Without rigorous measures, it is hard to have concrete evidence of whether the new explanation techniques can significantly outperform their predecessors. Our study proposes a new taxonomy for evaluating local explanations: robustness, evaluation using ground truth from synthetic datasets and interpretable models, model randomization, and human-grounded evaluation. Using this proposed taxonomy, we highlight that all categories of evaluation methods, except those based on the ground truth from interpretable models, suffer from a problem we call the "blame problem." In our study, we argue that this category of evaluation measure is a more reasonable method for evaluating local model-agnostic explanations. However, we show that even this category of evaluation measures has further limitations. The evaluation of local explanations remains an open research problem.
Evaluating Local Model-Agnostic Explanations of Learning to Rank Models with Decision Paths
Mar 16, 2022



Local explanations of learning-to-rank (LTR) models are thought to extract the most important features that contribute to the ranking predicted by the LTR model for a single data point. Evaluating the accuracy of such explanations is challenging since the ground truth feature importance scores are not available for most modern LTR models. In this work, we propose a systematic evaluation technique for explanations of LTR models. Instead of using black-box models, such as neural networks, we propose to focus on tree-based LTR models, from which we can extract the ground truth feature importance scores using decision paths. Once extracted, we can directly compare the ground truth feature importance scores to the feature importance scores generated with explanation techniques. We compare two recently proposed explanation techniques for LTR models when using decision trees and gradient boosting models on the MQ2008 dataset. We show that the explanation accuracy in these techniques can largely vary depending on the explained model and even which data point is explained.
Evaluation of Local Model-Agnostic Explanations Using Ground Truth
Jun 04, 2021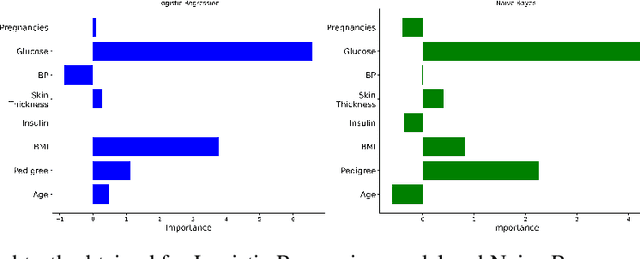

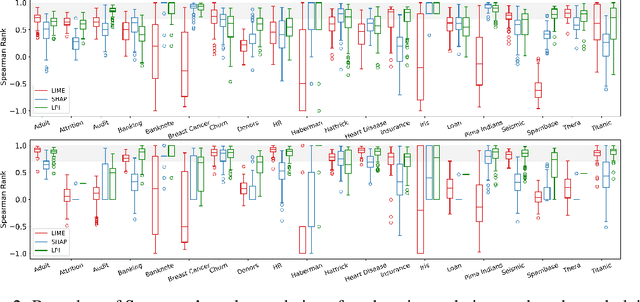
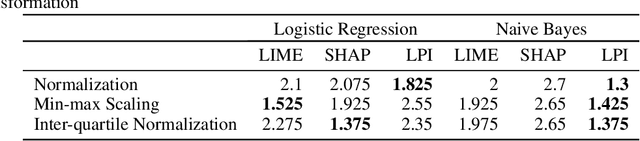
Explanation techniques are commonly evaluated using human-grounded methods, limiting the possibilities for large-scale evaluations and rapid progress in the development of new techniques. We propose a functionally-grounded evaluation procedure for local model-agnostic explanation techniques. In our approach, we generate ground truth for explanations when the black-box model is Logistic Regression and Gaussian Naive Bayes and compare how similar each explanation is to the extracted ground truth. In our empirical study, explanations of Local Interpretable Model-agnostic Explanations (LIME), SHapley Additive exPlanations (SHAP), and Local Permutation Importance (LPI) are compared in terms of how similar they are to the extracted ground truth. In the case of Logistic Regression, we find that the performance of the explanation techniques is highly dependent on the normalization of the data. In contrast, Local Permutation Importance outperforms the other techniques on Naive Bayes, irrespective of normalization. We hope that this work lays the foundation for further research into functionally-grounded evaluation methods for explanation techniques.
A study of data and label shift in the LIME framework
Oct 31, 2019
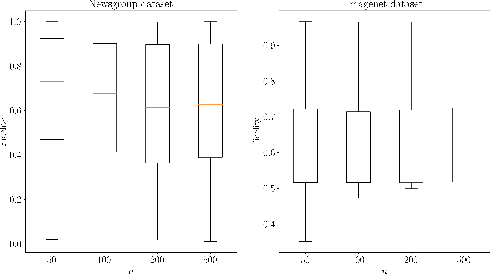

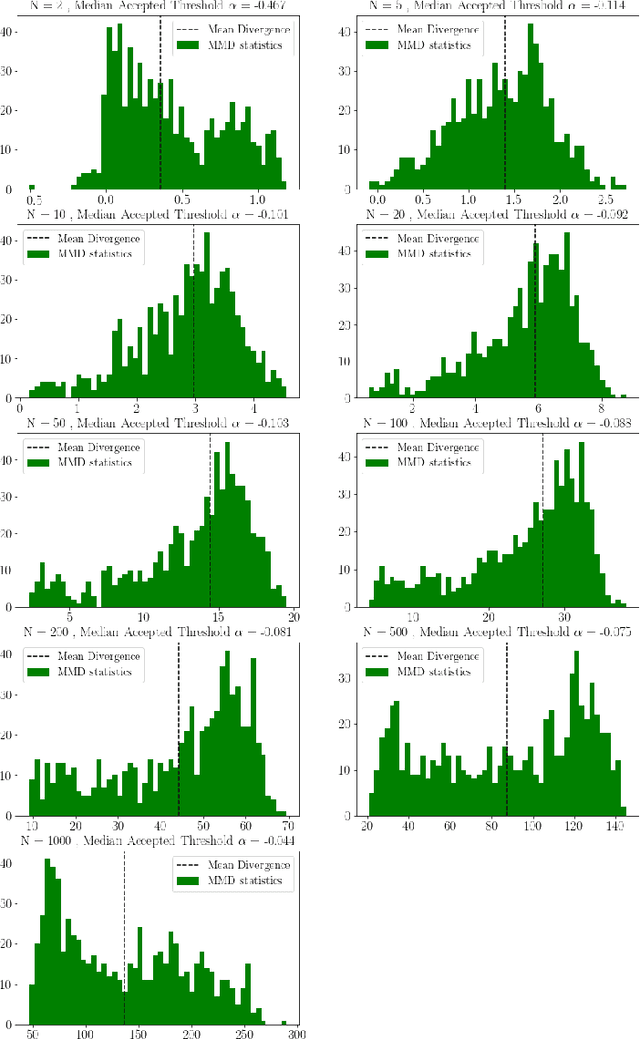
LIME is a popular approach for explaining a black-box prediction through an interpretable model that is trained on instances in the vicinity of the predicted instance. To generate these instances, LIME randomly selects a subset of the non-zero features of the predicted instance. After that, the perturbed instances are fed into the black-box model to obtain labels for these, which are then used for training the interpretable model. In this study, we present a systematic evaluation of the interpretable models that are output by LIME on the two use-cases that were considered in the original paper introducing the approach; text classification and object detection. The investigation shows that the perturbation and labeling phases result in both data and label shift. In addition, we study the correlation between the shift and the fidelity of the interpretable model and show that in certain cases the shift negatively correlates with the fidelity. Based on these findings, it is argued that there is a need for a new sampling approach that mitigates the shift in the LIME's framework.
An LP-based hyperparameter optimization model for language modeling
Mar 29, 2018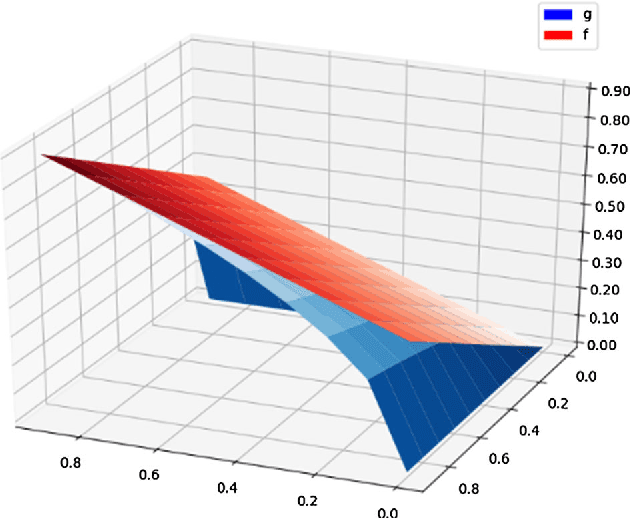


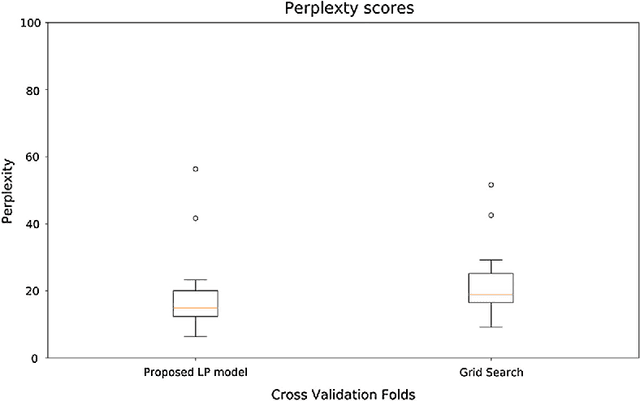
In order to find hyperparameters for a machine learning model, algorithms such as grid search or random search are used over the space of possible values of the models hyperparameters. These search algorithms opt the solution that minimizes a specific cost function. In language models, perplexity is one of the most popular cost functions. In this study, we propose a fractional nonlinear programming model that finds the optimal perplexity value. The special structure of the model allows us to approximate it by a linear programming model that can be solved using the well-known simplex algorithm. To the best of our knowledge, this is the first attempt to use optimization techniques to find perplexity values in the language modeling literature. We apply our model to find hyperparameters of a language model and compare it to the grid search algorithm. Furthermore, we illustrating that it results in lower perplexity values. We perform this experiment on a real-world dataset from SwiftKey to validate our proposed approach.
Distributed Real-Time Sentiment Analysis for Big Data Social Streams
Dec 27, 2016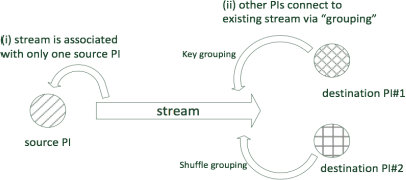
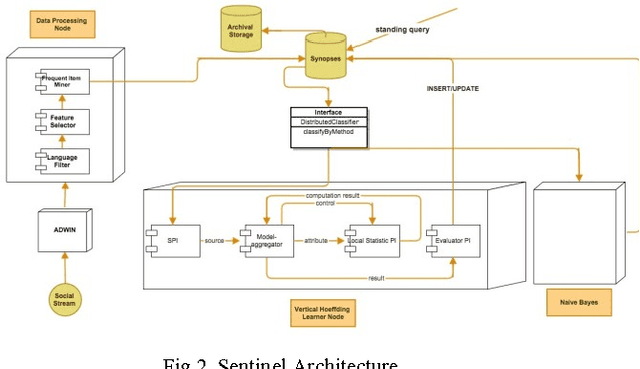
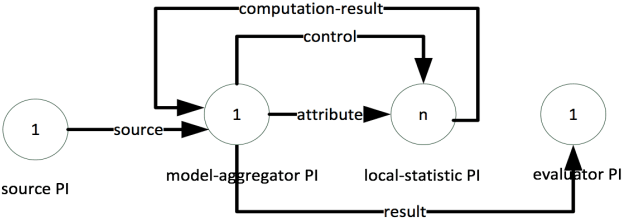
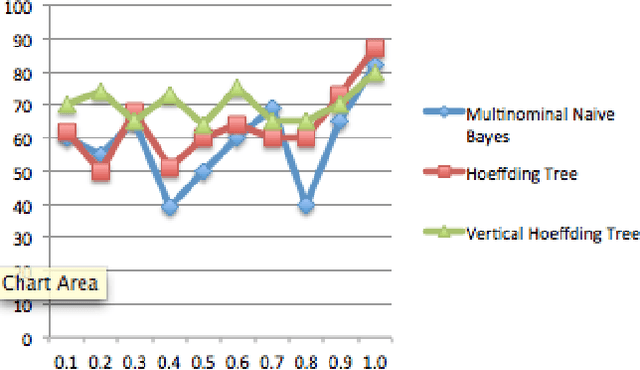
Big data trend has enforced the data-centric systems to have continuous fast data streams. In recent years, real-time analytics on stream data has formed into a new research field, which aims to answer queries about what-is-happening-now with a negligible delay. The real challenge with real-time stream data processing is that it is impossible to store instances of data, and therefore online analytical algorithms are utilized. To perform real-time analytics, pre-processing of data should be performed in a way that only a short summary of stream is stored in main memory. In addition, due to high speed of arrival, average processing time for each instance of data should be in such a way that incoming instances are not lost without being captured. Lastly, the learner needs to provide high analytical accuracy measures. Sentinel is a distributed system written in Java that aims to solve this challenge by enforcing both the processing and learning process to be done in distributed form. Sentinel is built on top of Apache Storm, a distributed computing platform. Sentinels learner, Vertical Hoeffding Tree, is a parallel decision tree-learning algorithm based on the VFDT, with ability of enabling parallel classification in distributed environments. Sentinel also uses SpaceSaving to keep a summary of the data stream and stores its summary in a synopsis data structure. Application of Sentinel on Twitter Public Stream API is shown and the results are discussed.