 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA study of data and label shift in the LIME framework
Paper and Code
Oct 31, 2019
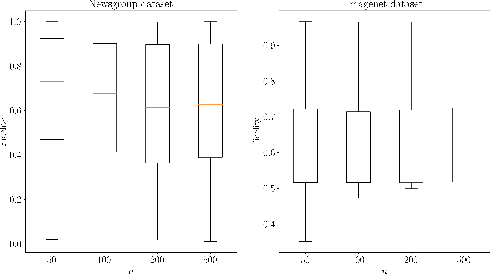

LIME is a popular approach for explaining a black-box prediction through an interpretable model that is trained on instances in the vicinity of the predicted instance. To generate these instances, LIME randomly selects a subset of the non-zero features of the predicted instance. After that, the perturbed instances are fed into the black-box model to obtain labels for these, which are then used for training the interpretable model. In this study, we present a systematic evaluation of the interpretable models that are output by LIME on the two use-cases that were considered in the original paper introducing the approach; text classification and object detection. The investigation shows that the perturbation and labeling phases result in both data and label shift. In addition, we study the correlation between the shift and the fidelity of the interpretable model and show that in certain cases the shift negatively correlates with the fidelity. Based on these findings, it is argued that there is a need for a new sampling approach that mitigates the shift in the LIME's framework.