 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMP-MARL: a Suite of Environments for Large-scale Infrastructure Management Planning via MARL
Jun 20, 2023



We introduce IMP-MARL, an open-source suite of multi-agent reinforcement learning (MARL) environments for large-scale Infrastructure Management Planning (IMP), offering a platform for benchmarking the scalability of cooperative MARL methods in real-world engineering applications. In IMP, a multi-component engineering system is subject to a risk of failure due to its components' damage condition. Specifically, each agent plans inspections and repairs for a specific system component, aiming to minimise maintenance costs while cooperating to minimise system failure risk. With IMP-MARL, we release several environments including one related to offshore wind structural systems, in an effort to meet today's needs to improve management strategies to support sustainable and reliable energy systems. Supported by IMP practical engineering environments featuring up to 100 agents, we conduct a benchmark campaign, where the scalability and performance of state-of-the-art cooperative MARL methods are compared against expert-based heuristic policies. The results reveal that centralised training with decentralised execution methods scale better with the number of agents than fully centralised or decentralised RL approaches, while also outperforming expert-based heuristic policies in most IMP environments. Based on our findings, we additionally outline remaining cooperation and scalability challenges that future MARL methods should still address. Through IMP-MARL, we encourage the implementation of new environments and the further development of MARL methods.
Value-based CTDE Methods in Symmetric Two-team Markov Game: from Cooperation to Team Competition
Nov 30, 2022



In this paper, we identify the best learning scenario to train a team of agents to compete against multiple possible strategies of opposing teams. We evaluate cooperative value-based methods in a mixed cooperative-competitive environment. We restrict ourselves to the case of a symmetric, partially observable, two-team Markov game. We selected three training methods based on the centralised training and decentralised execution (CTDE) paradigm: QMIX, MAVEN and QVMix. For each method, we considered three learning scenarios differentiated by the variety of team policies encountered during training. For our experiments, we modified the StarCraft Multi-Agent Challenge environment to create competitive environments where both teams could learn and compete simultaneously. Our results suggest that training against multiple evolving strategies achieves the best results when, for scoring their performances, teams are faced with several strategies.
QVMix and QVMix-Max: Extending the Deep Quality-Value Family of Algorithms to Cooperative Multi-Agent Reinforcement Learning
Dec 22, 2020
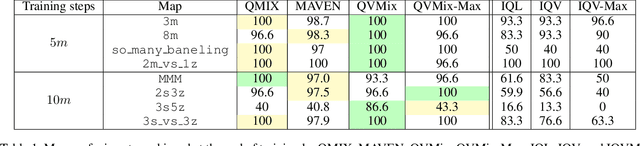
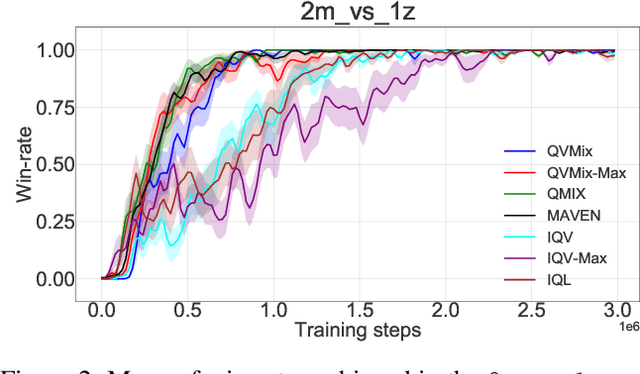
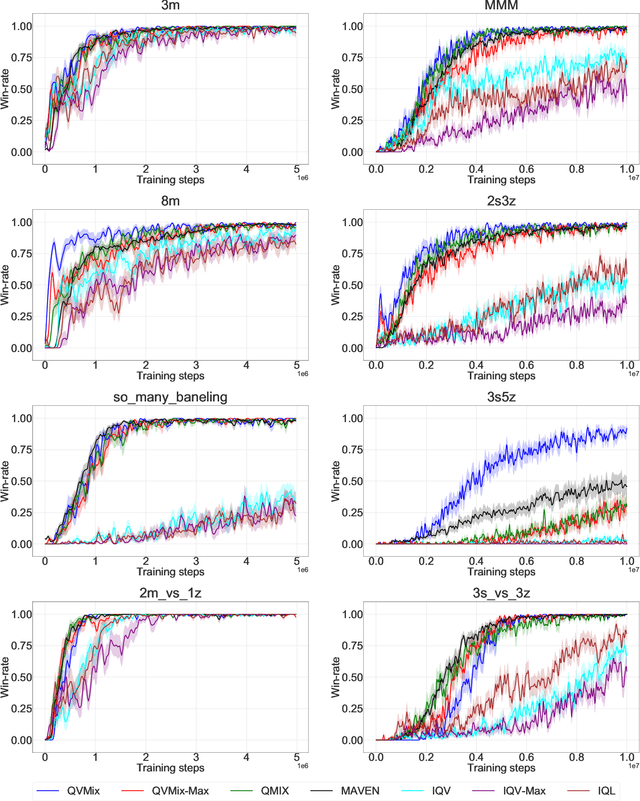
This paper introduces four new algorithms that can be used for tackling multi-agent reinforcement learning (MARL) problems occurring in cooperative settings. All algorithms are based on the Deep Quality-Value (DQV) family of algorithms, a set of techniques that have proven to be successful when dealing with single-agent reinforcement learning problems (SARL). The key idea of DQV algorithms is to jointly learn an approximation of the state-value function $V$, alongside an approximation of the state-action value function $Q$. We follow this principle and generalise these algorithms by introducing two fully decentralised MARL algorithms (IQV and IQV-Max) and two algorithms that are based on the centralised training with decentralised execution training paradigm (QVMix and QVMix-Max). We compare our algorithms with state-of-the-art MARL techniques on the popular StarCraft Multi-Agent Challenge (SMAC) environment. We show competitive results when QVMix and QVMix-Max are compared to well-known MARL techniques such as QMIX and MAVEN and show that QVMix can even outperform them on some of the tested environments, being the algorithm which performs best overall. We hypothesise that this is due to the fact that QVMix suffers less from the overestimation bias of the $Q$ function.