 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous-action Reinforcement Learning for Playing Racing Games: Comparing SPG to PPO
Paper and Code
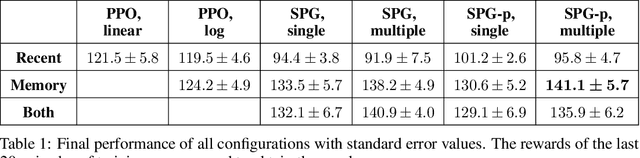

In this paper, a novel racing environment for OpenAI Gym is introduced. This environment operates with continuous action- and state-spaces and requires agents to learn to control the acceleration and steering of a car while navigating a randomly generated racetrack. Different versions of two actor-critic learning algorithms are tested on this environment: Sampled Policy Gradient (SPG) and Proximal Policy Optimization (PPO). An extension of SPG is introduced that aims to improve learning performance by weighting action samples during the policy update step. The effect of using experience replay (ER) is also investigated. To this end, a modification to PPO is introduced that allows for training using old action samples by optimizing the actor in log space. Finally, a new technique for performing ER is tested that aims to improve learning speed without sacrificing performance by splitting the training into two parts, whereby networks are first trained using state transitions from the replay buffer, and then using only recent experiences. The results indicate that experience replay is not beneficial to PPO in continuous action spaces. The training of SPG seems to be more stable when actions are weighted. All versions of SPG outperform PPO when ER is used. The ER trick is effective at improving training speed on a computationally less intensive version of SPG.