 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampled Policy Gradient for Learning to Play the Game Agar.io
Paper and Code


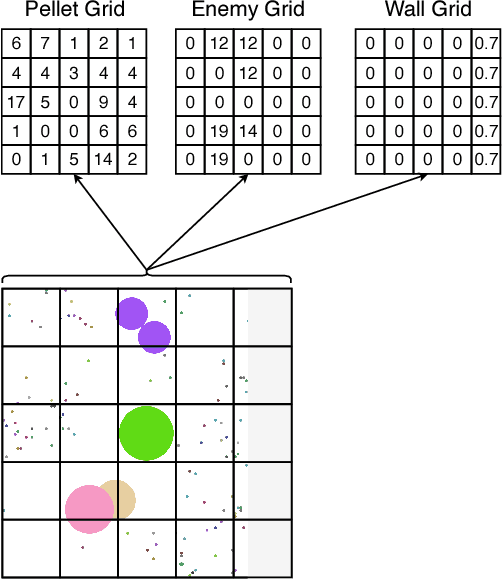
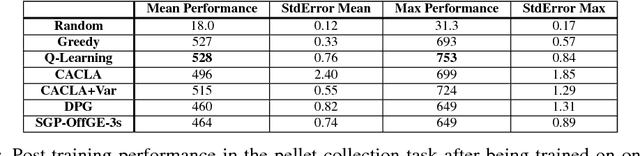
In this paper, a new offline actor-critic learning algorithm is introduced: Sampled Policy Gradient (SPG). SPG samples in the action space to calculate an approximated policy gradient by using the critic to evaluate the samples. This sampling allows SPG to search the action-Q-value space more globally than deterministic policy gradient (DPG), enabling it to theoretically avoid more local optima. SPG is compared to Q-learning and the actor-critic algorithms CACLA and DPG in a pellet collection task and a self play environment in the game Agar.io. The online game Agar.io has become massively popular on the internet due to intuitive game design and the ability to instantly compete against players around the world. From the point of view of artificial intelligence this game is also very intriguing: The game has a continuous input and action space and allows to have diverse agents with complex strategies compete against each other. The experimental results show that Q-Learning and CACLA outperform a pre-programmed greedy bot in the pellet collection task, but all algorithms fail to outperform this bot in a fighting scenario. The SPG algorithm is analyzed to have great extendability through offline exploration and it matches DPG in performance even in its basic form without extensive sampling.