 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-contrast MRI Super-resolution via Implicit Neural Representations
Mar 27, 2023Clinical routine and retrospective cohorts commonly include multi-parametric Magnetic Resonance Imaging; however, they are mostly acquired in different anisotropic 2D views due to signal-to-noise-ratio and scan-time constraints. Thus acquired views suffer from poor out-of-plane resolution and affect downstream volumetric image analysis that typically requires isotropic 3D scans. Combining different views of multi-contrast scans into high-resolution isotropic 3D scans is challenging due to the lack of a large training cohort, which calls for a subject-specific framework.This work proposes a novel solution to this problem leveraging Implicit Neural Representations (INR). Our proposed INR jointly learns two different contrasts of complementary views in a continuous spatial function and benefits from exchanging anatomical information between them. Trained within minutes on a single commodity GPU, our model provides realistic super-resolution across different pairs of contrasts in our experiments with three datasets. Using Mutual Information (MI) as a metric, we find that our model converges to an optimum MI amongst sequences, achieving anatomically faithful reconstruction. Code is available at: https://github.com/jqmcginnis/multi_contrast_inr.
Synthetic vascular structure generation for unsupervised pre-training in CTA segmentation tasks
Jan 02, 2020



Large enough computed tomography (CT) data sets to train supervised deep models are often hard to come by. One contributing issue is the amount of manual labor that goes into creating ground truth labels, specially for volumetric data. In this research, we train a U-net architecture at a vessel segmentation task that can be used to provide insights when treating stroke patients. We create a computational model that generates synthetic vascular structures which can be blended into unlabeled CT scans of the head. This unsupervised approached to labelling is used to pre-train deep segmentation models, which are later fine-tuned on real examples to achieve an increase in accuracy compared to models trained exclusively on a hand-labeled data set.
Investigation on the generalization of the Sampled Policy Gradient algorithm
Oct 09, 2019

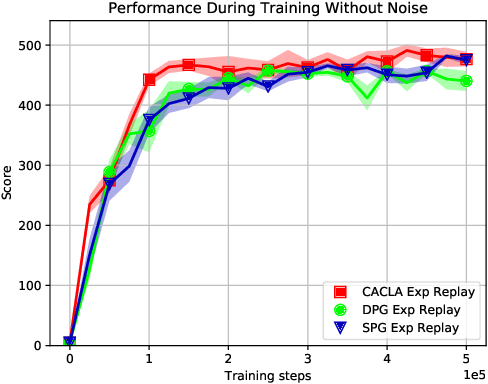
The Sampled Policy Gradient (SPG) algorithm is a new offline actor-critic variant that samples in the action space to approximate the policy gradient. It does so by using the critic to evaluate the sampled actions. SPG offers theoretical promise over similar algorithms such as DPG as it searches the action-Q-value space independently of the local gradient, enabling it to avoid local minima. This paper aims to compare SPG to two similar actor-critic algorithms, CACLA and DPG. The comparison is made across two different environments, two different network architectures, as well as training on on-policy transitions in contrast to using an experience buffer. Results seem to show that although SPG does often not perform the worst, it doesn't always match the performance of the best performing algorithm at a particular task. Further experiments are required to get a better estimate of the qualities of SPG.
Sampled Policy Gradient for Learning to Play the Game Agar.io
Sep 15, 2018

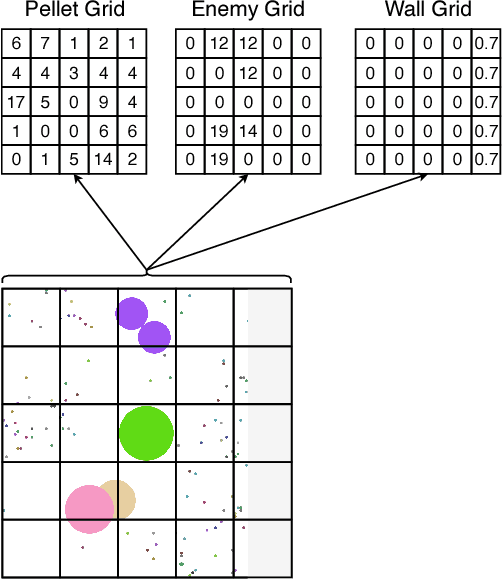
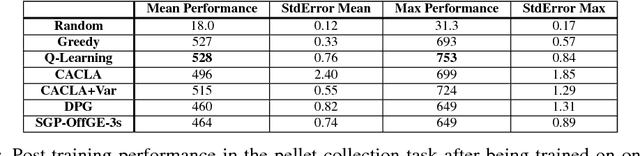
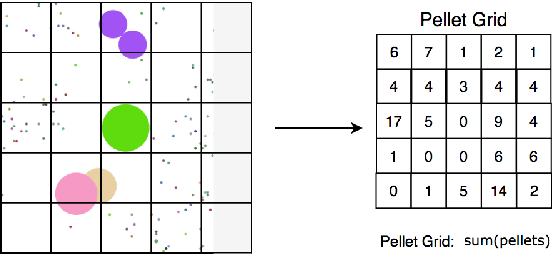
In this paper, a new offline actor-critic learning algorithm is introduced: Sampled Policy Gradient (SPG). SPG samples in the action space to calculate an approximated policy gradient by using the critic to evaluate the samples. This sampling allows SPG to search the action-Q-value space more globally than deterministic policy gradient (DPG), enabling it to theoretically avoid more local optima. SPG is compared to Q-learning and the actor-critic algorithms CACLA and DPG in a pellet collection task and a self play environment in the game Agar.io. The online game Agar.io has become massively popular on the internet due to intuitive game design and the ability to instantly compete against players around the world. From the point of view of artificial intelligence this game is also very intriguing: The game has a continuous input and action space and allows to have diverse agents with complex strategies compete against each other. The experimental results show that Q-Learning and CACLA outperform a pre-programmed greedy bot in the pellet collection task, but all algorithms fail to outperform this bot in a fighting scenario. The SPG algorithm is analyzed to have great extendability through offline exploration and it matches DPG in performance even in its basic form without extensive sampling.