 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordination and Machine Learning in Multi-Robot Systems: Applications in Robotic Soccer
Dec 26, 2023This paper presents the concepts of Artificial Intelligence, Multi-Agent-Systems, Coordination, Intelligent Robotics and Deep Reinforcement Learning. Emphasis is given on and how AI and DRL, may be efficiently used to create efficient robot skills and coordinated robotic teams, capable of performing very complex actions and tasks, such as playing a game of soccer. The paper also presents the concept of robotic soccer and the vision and structure of the RoboCup initiative with emphasis on the Humanoid Simulation 3D league and the new challenges this competition, poses. The final topics presented at the paper are based on the research developed/coordinated by the author throughout the last 22 years in the context of the FCPortugal project. The paper presents a short description of the coordination methodologies developed, such as: Strategy, Tactics, Formations, Setplays, and Coaching Languages and the use of Machine Learning to optimize the use of this concepts. The topics presented also include novel stochastic search algorithms for black box optimization and their use in the optimization of omnidirectional walking skills, robotic multi-agent learning and the creation of a humanoid kick with controlled distance. Finally, new applications using variations of the Proximal Policy Optimization algorithm and advanced modelling for robot and multi-robot learning are briefly explained with emphasis for our new humanoid sprinting and running skills and an amazing humanoid robot soccer dribbling skill. FCPortugal project enabled us to publish more than 100 papers and win several competitions in different leagues and many scientific awards at RoboCup. In total, our team won more than 40 awards in international competitions including a clear victory at the Simulation 3D League at RoboCup 2022 competition, scoring 84 goals and conceding only 2.
Designing a Skilled Soccer Team for RoboCup: Exploring Skill-Set-Primitives through Reinforcement Learning
Dec 22, 2023The RoboCup 3D Soccer Simulation League serves as a competitive platform for showcasing innovation in autonomous humanoid robot agents through simulated soccer matches. Our team, FC Portugal, developed a new codebase from scratch in Python after RoboCup 2021. The team's performance is based on a set of skills centered around novel unifying primitives and a custom, symmetry-extended version of the Proximal Policy Optimization algorithm. Our methods have been thoroughly tested in official RoboCup matches, where FC Portugal has won the last two main competitions, in 2022 and 2023. This paper presents our training framework, as well as a timeline of skills developed using our skill-set-primitives, which considerably improve the sample efficiency and stability of skills, and motivate seamless transitions. We start with a significantly fast sprint-kick developed in 2021 and progress to the most recent skill set, which includes a multi-purpose omnidirectional walk, a dribble with unprecedented ball control, a solid kick, and a push skill. The push tackles both low-level collision-prone scenarios and high-level strategies to increase ball possession. We address the resource-intensive nature of this task through an innovative multi-agent learning approach. Finally, we release the codebase of our team to the RoboCup community, enabling other teams to transition to Python more easily and providing new teams with a robust and modern foundation upon which they can build new features.
Addressing Imperfect Symmetry: a Novel Symmetry-Learning Actor-Critic Extension
Sep 06, 2023



Symmetry, a fundamental concept to understand our environment, often oversimplifies reality from a mathematical perspective. Humans are a prime example, deviating from perfect symmetry in terms of appearance and cognitive biases (e.g. having a dominant hand). Nevertheless, our brain can easily overcome these imperfections and efficiently adapt to symmetrical tasks. The driving motivation behind this work lies in capturing this ability through reinforcement learning. To this end, we introduce Adaptive Symmetry Learning (ASL) $\unicode{x2013}$ a model-minimization actor-critic extension that addresses incomplete or inexact symmetry descriptions by adapting itself during the learning process. ASL consists of a symmetry fitting component and a modular loss function that enforces a common symmetric relation across all states while adapting to the learned policy. The performance of ASL is compared to existing symmetry-enhanced methods in a case study involving a four-legged ant model for multidirectional locomotion tasks. The results demonstrate that ASL is capable of recovering from large perturbations and generalizing knowledge to hidden symmetric states. It achieves comparable or better performance than alternative methods in most scenarios, making it a valuable approach for leveraging model symmetry while compensating for inherent perturbations.
FC Portugal 3D Simulation Team: Team Description Paper 2020
Mar 28, 2023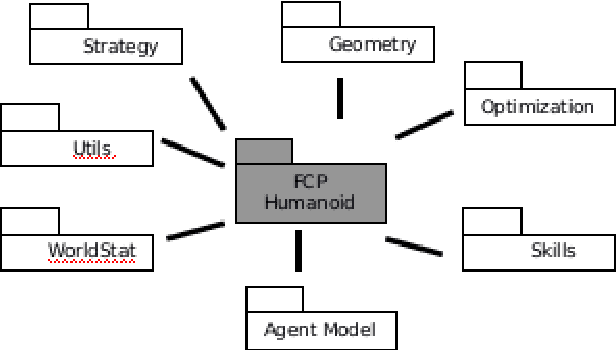



The FC Portugal 3D team is developed upon the structure of our previous Simulation league 2D/3D teams and our standard platform league team. Our research concerning the robot low-level skills is focused on developing behaviors that may be applied on real robots with minimal adaptation using model-based approaches. Our research on high-level soccer coordination methodologies and team playing is mainly focused on the adaptation of previously developed methodologies from our 2D soccer teams to the 3D humanoid environment and on creating new coordination methodologies based on the previously developed ones. The research-oriented development of our team has been pushing it to be one of the most competitive over the years (World champion in 2000 and Coach Champion in 2002, European champion in 2000 and 2001, Coach 2nd place in 2003 and 2004, European champion in Rescue Simulation and Simulation 3D in 2006, World Champion in Simulation 3D in Bremen 2006 and European champion in 2007, 2012, 2013, 2014 and 2015). This paper describes some of the main innovations of our 3D simulation league team during the last years. A new generic framework for reinforcement learning tasks has also been developed. The current research is focused on improving the above-mentioned framework by developing new learning algorithms to optimize low-level skills, such as running and sprinting. We are also trying to increase student contact by providing reinforcement learning assignments to be completed using our new framework, which exposes a simple interface without sharing low-level implementation details.
Robust Biped Locomotion Using Deep Reinforcement Learning on Top of an Analytical Control Approach
Apr 21, 2021

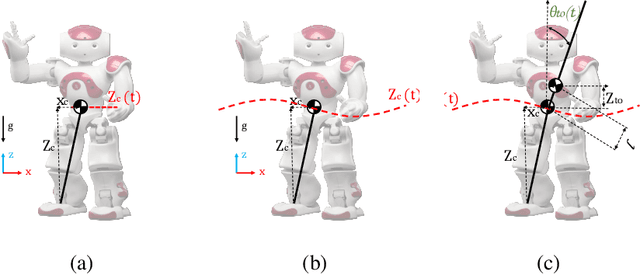

This paper proposes a modular framework to generate robust biped locomotion using a tight coupling between an analytical walking approach and deep reinforcement learning. This framework is composed of six main modules which are hierarchically connected to reduce the overall complexity and increase its flexibility. The core of this framework is a specific dynamics model which abstracts a humanoid's dynamics model into two masses for modeling upper and lower body. This dynamics model is used to design an adaptive reference trajectories planner and an optimal controller which are fully parametric. Furthermore, a learning framework is developed based on Genetic Algorithm (GA) and Proximal Policy Optimization (PPO) to find the optimum parameters and to learn how to improve the stability of the robot by moving the arms and changing its center of mass (COM) height. A set of simulations are performed to validate the performance of the framework using the official RoboCup 3D League simulation environment. The results validate the performance of the framework, not only in creating a fast and stable gait but also in learning to improve the upper body efficiency.
A CPG-Based Agile and Versatile Locomotion Framework Using Proximal Symmetry Loss
Mar 01, 2021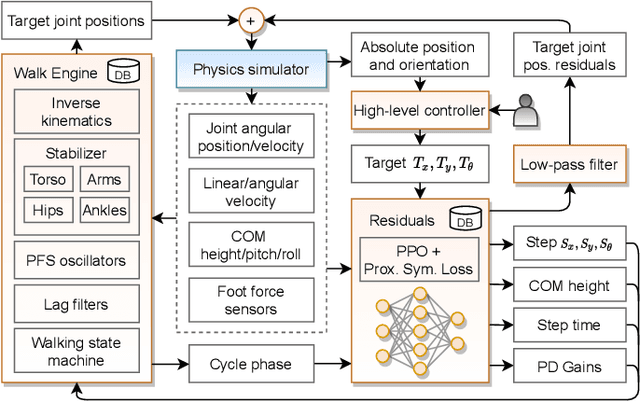
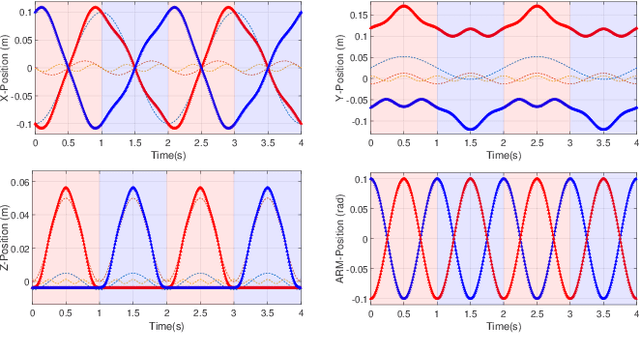


Humanoid robots are made to resemble humans but their locomotion abilities are far from ours in terms of agility and versatility. When humans walk on complex terrains, or face external disturbances, they combine a set of strategies, unconsciously and efficiently, to regain stability. This paper tackles the problem of developing a robust omnidirectional walking framework, which is able to generate versatile and agile locomotion on complex terrains. The Linear Inverted Pendulum Model and Central Pattern Generator concepts are used to develop a closed-loop walk engine that is combined with a reinforcement learning module. This module learns to regulate the walk engine parameters adaptively and generates residuals to adjust the robot's target joint positions (residual physics). Additionally, we propose a proximal symmetry loss to increase the sample efficiency of the Proximal Policy Optimization algorithm by leveraging model symmetries. The effectiveness of the proposed framework was demonstrated and evaluated across a set of challenging simulation scenarios. The robot was able to generalize what it learned in one scenario, by displaying human-like locomotion skills in unforeseen circumstances, even in the presence of noise and external pushes.
A Hybrid Biped Stabilizer System Based on Analytical Control and Learning of Symmetrical Residual Physics
Nov 27, 2020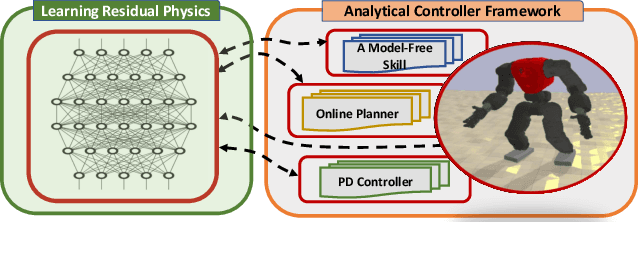
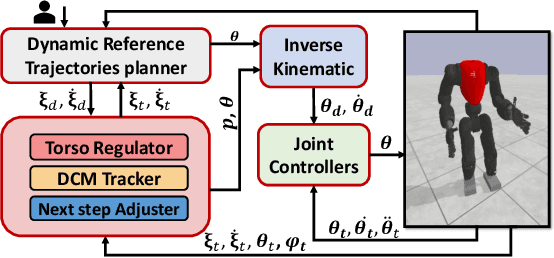

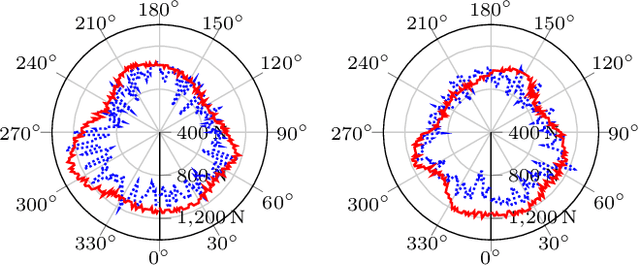
Although humanoid robots are made to resemble humans, their stability is not yet comparable to ours. When facing external disturbances, humans efficiently and unconsciously combine a set of strategies to regain stability. This work deals with the problem of developing a robust hybrid stabilizer system for biped robots. The Linear Inverted Pendulum (LIP) and Divergent Component of Motion (DCM) concepts are used to formulate the biped locomotion and stabilization as an analytical control framework. On top of that, a neural network with symmetric partial data augmentation learns residuals to adjust the joint's position, and thus improving the robot's stability when facing external perturbations. The performance of the proposed framework was evaluated across a set of challenging simulation scenarios. The results show a considerable improvement over the baseline in recovering from large external forces. Moreover, the produced behaviors are human-like and robust to considerably noisy environments.
Identifying Playerś Strategies in No Limit Texas Holdém Poker through the Analysis of Individual Moves
Jan 25, 2013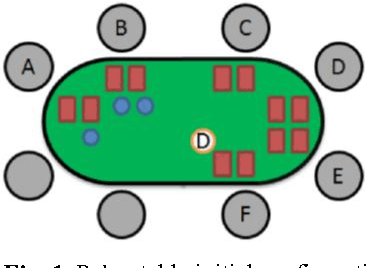
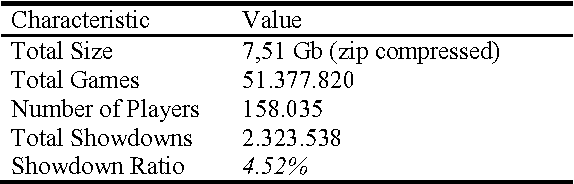
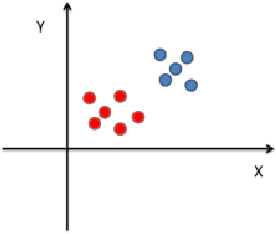
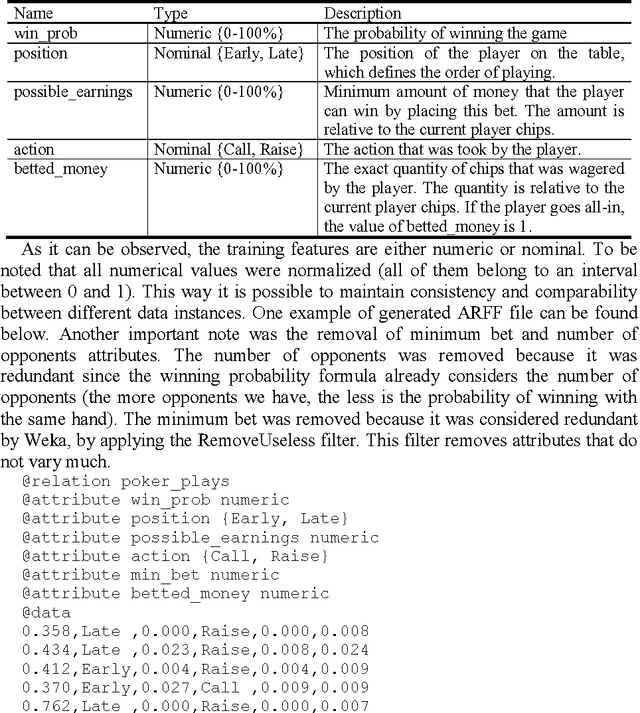
The development of competitive artificial Poker playing agents has proven to be a challenge, because agents must deal with unreliable information and deception which make it essential to model the opponents in order to achieve good results. This paper presents a methodology to develop opponent modeling techniques for Poker agents. The approach is based on applying clustering algorithms to a Poker game database in order to identify player types based on their actions. First, common game moves were identified by clustering all players\' moves. Then, player types were defined by calculating the frequency with which the players perform each type of movement. With the given dataset, 7 different types of players were identified with each one having at least one tactic that characterizes him. The identification of player types may improve the overall performance of Poker agents, because it helps the agents to predict the opponent\'s moves, by associating each opponent to a distinct cluster.
A Computational Study on Emotions and Temperament in Multi-Agent Systems
Sep 27, 2008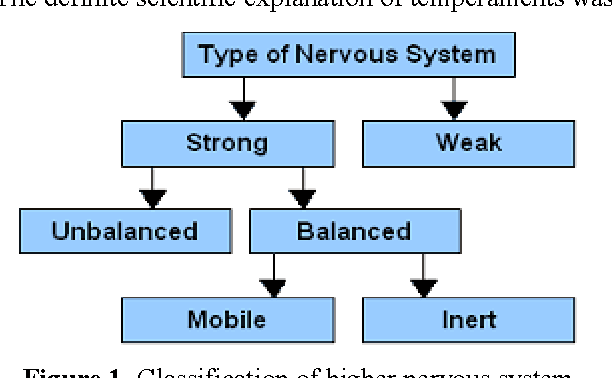



Recent advances in neurosciences and psychology have provided evidence that affective phenomena pervade intelligence at many levels, being inseparable from the cognitionaction loop. Perception, attention, memory, learning, decisionmaking, adaptation, communication and social interaction are some of the aspects influenced by them. This work draws its inspirations from neurobiology, psychophysics and sociology to approach the problem of building autonomous robots capable of interacting with each other and building strategies based on temperamental decision mechanism. Modelling emotions is a relatively recent focus in artificial intelligence and cognitive modelling. Such models can ideally inform our understanding of human behavior. We may see the development of computational models of emotion as a core research focus that will facilitate advances in the large array of computational systems that model, interpret or influence human behavior. We propose a model based on a scalable, flexible and modular approach to emotion which allows runtime evaluation between emotional quality and performance. The results achieved showed that the strategies based on temperamental decision mechanism strongly influence the system performance and there are evident dependency between emotional state of the agents and their temperamental type, as well as the dependency between the team performance and the temperamental configuration of the team members, and this enable us to conclude that the modular approach to emotional programming based on temperamental theory is the good choice to develop computational mind models for emotional behavioral Multi-Agent systems.
Agent-based Ecological Model Calibration - on the Edge of a New Approach
Sep 09, 2008



The purpose of this paper is to present a new approach to ecological model calibration -- an agent-based software. This agent works on three stages: 1- It builds a matrix that synthesizes the inter-variable relationships; 2- It analyses the steady-state sensitivity of different variables to different parameters; 3- It runs the model iteratively and measures model lack of fit, adequacy and reliability. Stage 3 continues until some convergence criteria are attained. At each iteration, the agent knows from stages 1 and 2, which parameters are most likely to produce the desired shift on predicted results.