 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning a Skilled Soccer Team for RoboCup: Exploring Skill-Set-Primitives through Reinforcement Learning
Dec 22, 2023The RoboCup 3D Soccer Simulation League serves as a competitive platform for showcasing innovation in autonomous humanoid robot agents through simulated soccer matches. Our team, FC Portugal, developed a new codebase from scratch in Python after RoboCup 2021. The team's performance is based on a set of skills centered around novel unifying primitives and a custom, symmetry-extended version of the Proximal Policy Optimization algorithm. Our methods have been thoroughly tested in official RoboCup matches, where FC Portugal has won the last two main competitions, in 2022 and 2023. This paper presents our training framework, as well as a timeline of skills developed using our skill-set-primitives, which considerably improve the sample efficiency and stability of skills, and motivate seamless transitions. We start with a significantly fast sprint-kick developed in 2021 and progress to the most recent skill set, which includes a multi-purpose omnidirectional walk, a dribble with unprecedented ball control, a solid kick, and a push skill. The push tackles both low-level collision-prone scenarios and high-level strategies to increase ball possession. We address the resource-intensive nature of this task through an innovative multi-agent learning approach. Finally, we release the codebase of our team to the RoboCup community, enabling other teams to transition to Python more easily and providing new teams with a robust and modern foundation upon which they can build new features.
Addressing Imperfect Symmetry: a Novel Symmetry-Learning Actor-Critic Extension
Sep 06, 2023Symmetry, a fundamental concept to understand our environment, often oversimplifies reality from a mathematical perspective. Humans are a prime example, deviating from perfect symmetry in terms of appearance and cognitive biases (e.g. having a dominant hand). Nevertheless, our brain can easily overcome these imperfections and efficiently adapt to symmetrical tasks. The driving motivation behind this work lies in capturing this ability through reinforcement learning. To this end, we introduce Adaptive Symmetry Learning (ASL) $\unicode{x2013}$ a model-minimization actor-critic extension that addresses incomplete or inexact symmetry descriptions by adapting itself during the learning process. ASL consists of a symmetry fitting component and a modular loss function that enforces a common symmetric relation across all states while adapting to the learned policy. The performance of ASL is compared to existing symmetry-enhanced methods in a case study involving a four-legged ant model for multidirectional locomotion tasks. The results demonstrate that ASL is capable of recovering from large perturbations and generalizing knowledge to hidden symmetric states. It achieves comparable or better performance than alternative methods in most scenarios, making it a valuable approach for leveraging model symmetry while compensating for inherent perturbations.
Q-learning Based System for Path Planning with UAV Swarms in Obstacle Environments
Mar 30, 2023Path Planning methods for autonomous control of Unmanned Aerial Vehicle (UAV) swarms are on the rise because of all the advantages they bring. There are more and more scenarios where autonomous control of multiple UAVs is required. Most of these scenarios present a large number of obstacles, such as power lines or trees. If all UAVs can be operated autonomously, personnel expenses can be decreased. In addition, if their flight paths are optimal, energy consumption is reduced. This ensures that more battery time is left for other operations. In this paper, a Reinforcement Learning based system is proposed for solving this problem in environments with obstacles by making use of Q-Learning. This method allows a model, in this particular case an Artificial Neural Network, to self-adjust by learning from its mistakes and achievements. Regardless of the size of the map or the number of UAVs in the swarm, the goal of these paths is to ensure complete coverage of an area with fixed obstacles for tasks, like field prospecting. Setting goals or having any prior information aside from the provided map is not required. For experimentation, five maps of different sizes with different obstacles were used. The experiments were performed with different number of UAVs. For the calculation of the results, the number of actions taken by all UAVs to complete the task in each experiment is taken into account. The lower the number of actions, the shorter the path and the lower the energy consumption. The results are satisfactory, showing that the system obtains solutions in fewer movements the more UAVs there are. For a better presentation, these results have been compared to another state-of-the-art approach.
FC Portugal 3D Simulation Team: Team Description Paper 2020
Mar 28, 2023The FC Portugal 3D team is developed upon the structure of our previous Simulation league 2D/3D teams and our standard platform league team. Our research concerning the robot low-level skills is focused on developing behaviors that may be applied on real robots with minimal adaptation using model-based approaches. Our research on high-level soccer coordination methodologies and team playing is mainly focused on the adaptation of previously developed methodologies from our 2D soccer teams to the 3D humanoid environment and on creating new coordination methodologies based on the previously developed ones. The research-oriented development of our team has been pushing it to be one of the most competitive over the years (World champion in 2000 and Coach Champion in 2002, European champion in 2000 and 2001, Coach 2nd place in 2003 and 2004, European champion in Rescue Simulation and Simulation 3D in 2006, World Champion in Simulation 3D in Bremen 2006 and European champion in 2007, 2012, 2013, 2014 and 2015). This paper describes some of the main innovations of our 3D simulation league team during the last years. A new generic framework for reinforcement learning tasks has also been developed. The current research is focused on improving the above-mentioned framework by developing new learning algorithms to optimize low-level skills, such as running and sprinting. We are also trying to increase student contact by providing reinforcement learning assignments to be completed using our new framework, which exposes a simple interface without sharing low-level implementation details.
Robust Biped Locomotion Using Deep Reinforcement Learning on Top of an Analytical Control Approach
Apr 21, 2021

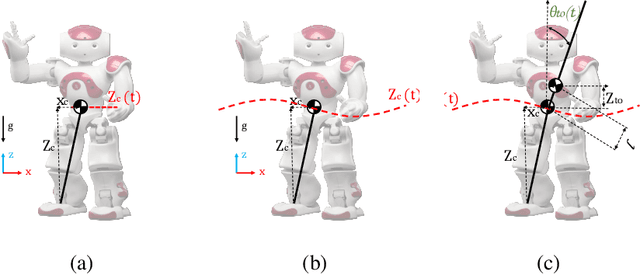

This paper proposes a modular framework to generate robust biped locomotion using a tight coupling between an analytical walking approach and deep reinforcement learning. This framework is composed of six main modules which are hierarchically connected to reduce the overall complexity and increase its flexibility. The core of this framework is a specific dynamics model which abstracts a humanoid's dynamics model into two masses for modeling upper and lower body. This dynamics model is used to design an adaptive reference trajectories planner and an optimal controller which are fully parametric. Furthermore, a learning framework is developed based on Genetic Algorithm (GA) and Proximal Policy Optimization (PPO) to find the optimum parameters and to learn how to improve the stability of the robot by moving the arms and changing its center of mass (COM) height. A set of simulations are performed to validate the performance of the framework using the official RoboCup 3D League simulation environment. The results validate the performance of the framework, not only in creating a fast and stable gait but also in learning to improve the upper body efficiency.
A CPG-Based Agile and Versatile Locomotion Framework Using Proximal Symmetry Loss
Mar 01, 2021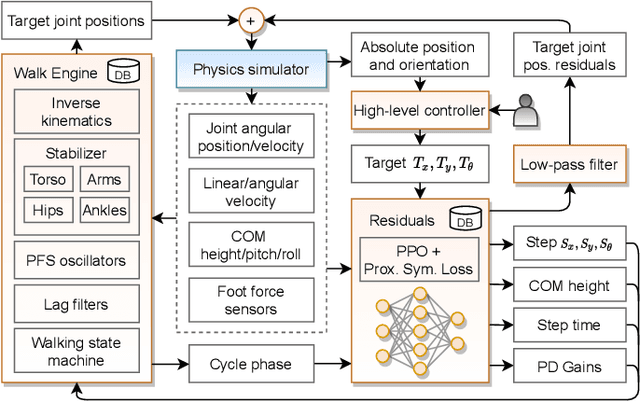
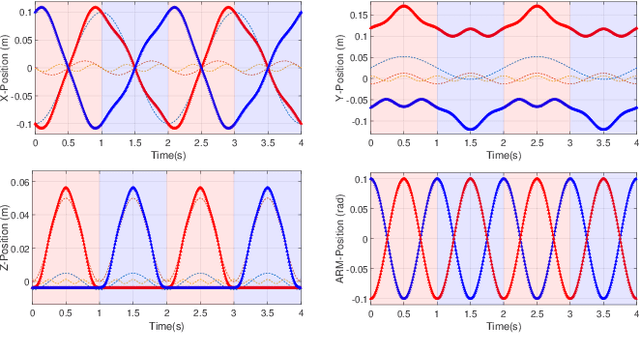


Humanoid robots are made to resemble humans but their locomotion abilities are far from ours in terms of agility and versatility. When humans walk on complex terrains, or face external disturbances, they combine a set of strategies, unconsciously and efficiently, to regain stability. This paper tackles the problem of developing a robust omnidirectional walking framework, which is able to generate versatile and agile locomotion on complex terrains. The Linear Inverted Pendulum Model and Central Pattern Generator concepts are used to develop a closed-loop walk engine that is combined with a reinforcement learning module. This module learns to regulate the walk engine parameters adaptively and generates residuals to adjust the robot's target joint positions (residual physics). Additionally, we propose a proximal symmetry loss to increase the sample efficiency of the Proximal Policy Optimization algorithm by leveraging model symmetries. The effectiveness of the proposed framework was demonstrated and evaluated across a set of challenging simulation scenarios. The robot was able to generalize what it learned in one scenario, by displaying human-like locomotion skills in unforeseen circumstances, even in the presence of noise and external pushes.
A Hybrid Biped Stabilizer System Based on Analytical Control and Learning of Symmetrical Residual Physics
Nov 27, 2020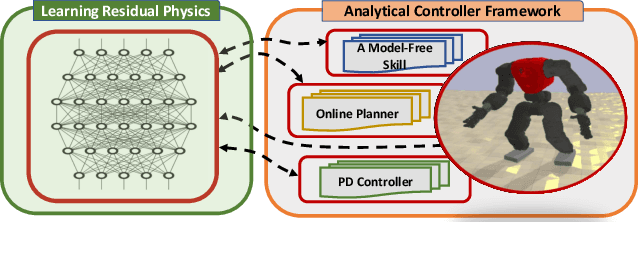
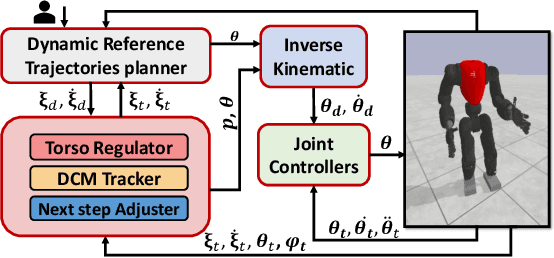

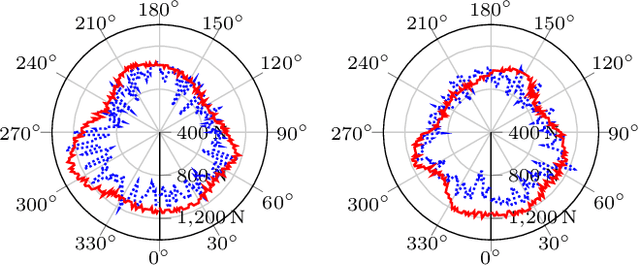
Although humanoid robots are made to resemble humans, their stability is not yet comparable to ours. When facing external disturbances, humans efficiently and unconsciously combine a set of strategies to regain stability. This work deals with the problem of developing a robust hybrid stabilizer system for biped robots. The Linear Inverted Pendulum (LIP) and Divergent Component of Motion (DCM) concepts are used to formulate the biped locomotion and stabilization as an analytical control framework. On top of that, a neural network with symmetric partial data augmentation learns residuals to adjust the joint's position, and thus improving the robot's stability when facing external perturbations. The performance of the proposed framework was evaluated across a set of challenging simulation scenarios. The results show a considerable improvement over the baseline in recovering from large external forces. Moreover, the produced behaviors are human-like and robust to considerably noisy environments.
A Robust Model-Based Biped Locomotion Framework Based on Three-Mass Model: From Planning to Control
Feb 17, 2020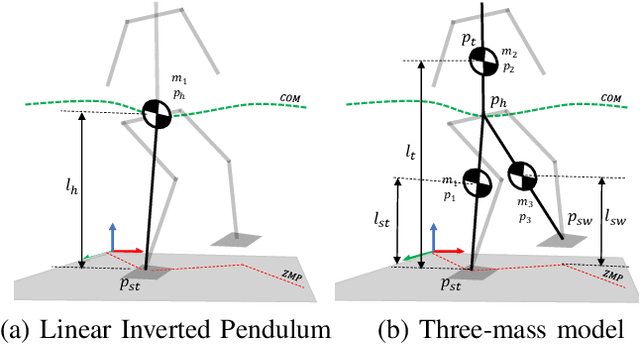
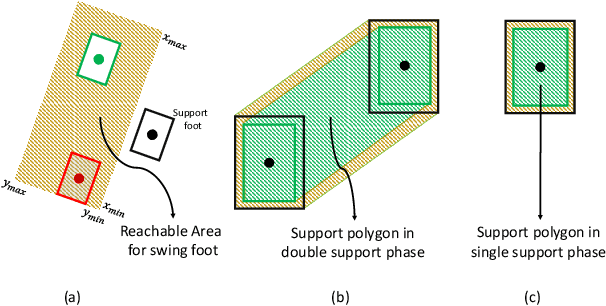
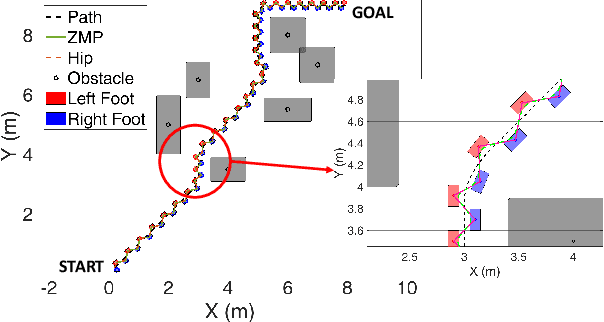
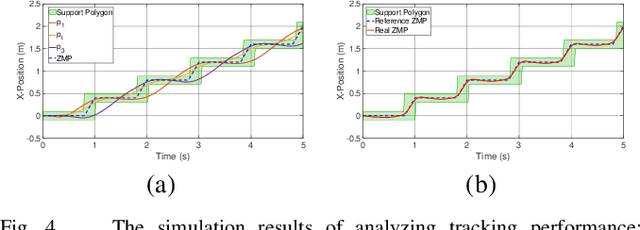
Biped robots are inherently unstable because of their complex kinematics as well as dynamics. Despite types of research in developing biped locomotion, the performance of biped locomotion is still far from the expectations. This paper proposes a model-based framework to generate stable biped locomotion. The core of this framework is an abstract dynamics model which is composed of three masses to consider the dynamics of stance leg, torso and swing leg for minimizing the tracking problems. According to this dynamics model, we propose a modular walking reference trajectories planner which takes into account obstacles to plan all the references. Moreover, this dynamics model is used to formulate the low-level controller as a Model Predictive Control~(MPC) scheme which can consider some constraints in the states of the system, inputs, outputs and also mixed input-output. The performance and the robustness of the proposed framework are validated by performing several simulations using~\mbox{MATLAB}. The simulation results show that the proposed framework is capable of generating the biped locomotion robustly.
A Hierarchical Framework to Generate Robust Biped Locomotion Based on Divergent Component of Motion
Nov 18, 2019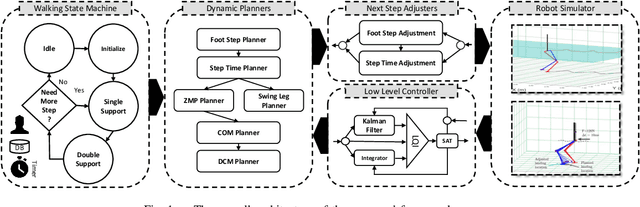

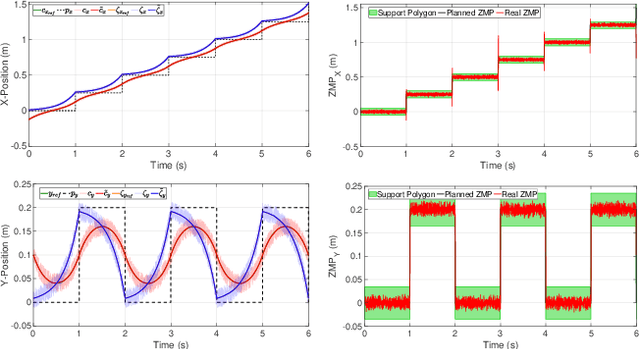
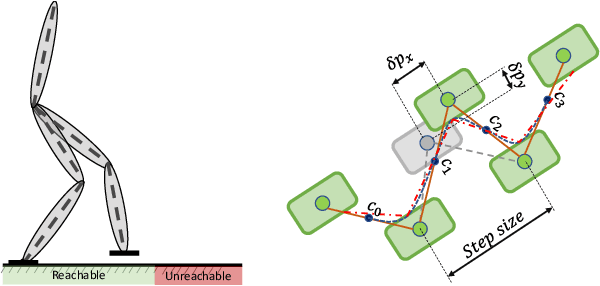
Keeping the stability can be counted as the essential ability of a humanoid robot to step out of the laboratory to work in our real environment. Since humanoid robots have similar kinematic to a human, humans expect these robots to be robustly capable of stabilizing even in a challenging situation like while a severe push is applied. This paper presents a robust walking framework which not only takes into account the traditional push recovery approaches (e.g., ankle, hip and step strategies) but also uses the concept of Divergent Component of the Motion (DCM) to adjust next step timing and location. The control core of the proposed framework is composed of a Linear-Quadratic-Gaussian (LQG) controller and two proportional controllers. In this framework, the LQG controller tries to track the reference trajectories and the proportional controllers are designed to adjust the next step timing and location that allow the robot to recover from a severe push. The robustness and the performance of the proposed framework have been validated by performing a set of simulations, including walking and push recovery using MATLAB. The simulation results verified that the proposed framework is capable of providing a robust walking even in very challenging situations.
A Robust Closed-Loop Biped Locomotion Planner Based on Time Varying Model Predictive Control
Sep 15, 2019
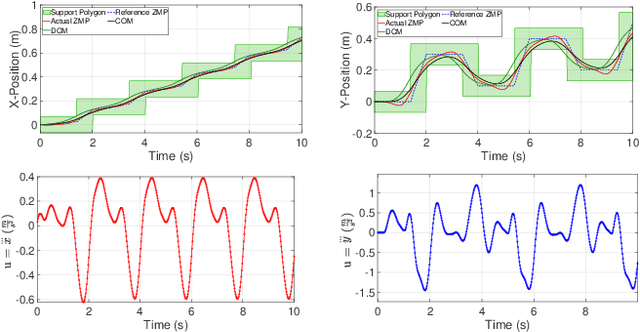

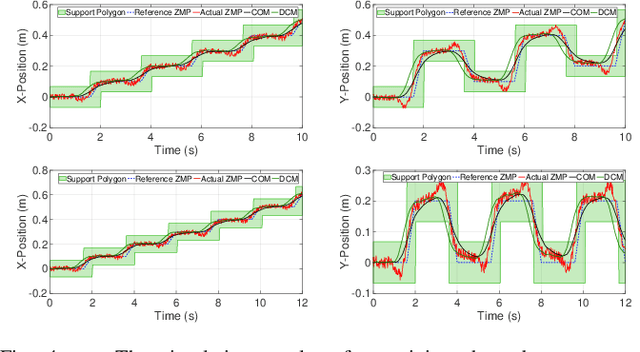
Developing robust locomotion for humanoid robots is a complex task due to the unstable nature of these robots and also to the unpredictability of the terrain. A robust locomotion planner is one of the fundamental components for generating stable biped locomotion. This paper presents an optimal closed-loop biped locomotion planner which can plan reference trajectories even in challenging conditions. The proposed planner is designed based on a Time-Varying Model Predictive Control~(TVMPC) scheme to be able to consider some constraints in the states, inputs and outputs of the system and also mixed input-output. Moreover, the proposed planner takes into account the vertical motion of the Center of Mass~(COM) to generate walking with mostly stretched knees which is more human-like. Additionally, the planner uses the concept of Divergent Component of Motion~(DCM) to modify the reference ZMP online to improve the withstanding level of the robot in the presence of severe disturbances. The performance and also the robustness of the proposed planner are validated by performing several simulations using~\mbox{MATLAB}. The simulation results show that the proposed planner is capable of generating the biped locomotion robustly.