 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Orthopox Image Classification Using Hybrid Machine Learning and Deep Learning Models
Jun 06, 2025



Orthopoxvirus infections must be accurately classified from medical pictures for an easy and early diagnosis and epidemic prevention. The necessity for automated and scalable solutions is highlighted by the fact that traditional diagnostic techniques can be time-consuming and require expert interpretation and there are few and biased data sets of the different types of Orthopox. In order to improve classification performance and lower computational costs, a hybrid strategy is put forth in this paper that uses Machine Learning models combined with pretrained Deep Learning models to extract deep feature representations without the need for augmented data. The findings show that this feature extraction method, when paired with other methods in the state-of-the-art, produces excellent classification outcomes while preserving training and inference efficiency. The proposed approach demonstrates strong generalization and robustness across multiple evaluation settings, offering a scalable and interpretable solution for real-world clinical deployment.
Genetic Algorithm Based System for Path Planning with Unmanned Aerial Vehicles Swarms in Cell-Grid Environments
Dec 04, 2024



Path Planning methods for autonomously controlling swarms of unmanned aerial vehicles (UAVs) are gaining momentum due to their operational advantages. An increasing number of scenarios now require autonomous control of multiple UAVs, as autonomous operation can significantly reduce labor costs. Additionally, obtaining optimal flight paths can lower energy consumption, thereby extending battery life for other critical operations. Many of these scenarios, however, involve obstacles such as power lines and trees, which complicate Path Planning. This paper presents an evolutionary computation-based system employing genetic algorithms to address this problem in environments with obstacles. The proposed approach aims to ensure complete coverage of areas with fixed obstacles, such as in field exploration tasks, while minimizing flight time regardless of map size or the number of UAVs in the swarm. No specific goal points or prior information beyond the provided map is required. The experiments conducted in this study used five maps of varying sizes and obstacle densities, as well as a control map without obstacles, with different numbers of UAVs. The results demonstrate that this method can determine optimal paths for all UAVs during full map traversal, thus minimizing resource consumption. A comparative analysis with other state-of-the-art approach is presented to highlight the advantages and potential limitations of the proposed method.
Harmful algal bloom forecasting. A comparison between stream and batch learning
Feb 20, 2024



Diarrhetic Shellfish Poisoning (DSP) is a global health threat arising from shellfish contaminated with toxins produced by dinoflagellates. The condition, with its widespread incidence, high morbidity rate, and persistent shellfish toxicity, poses risks to public health and the shellfish industry. High biomass of toxin-producing algae such as DSP are known as Harmful Algal Blooms (HABs). Monitoring and forecasting systems are crucial for mitigating HABs impact. Predicting harmful algal blooms involves a time-series-based problem with a strong historical seasonal component, however, recent anomalies due to changes in meteorological and oceanographic events have been observed. Stream Learning stands out as one of the most promising approaches for addressing time-series-based problems with concept drifts. However, its efficacy in predicting HABs remains unproven and needs to be tested in comparison with Batch Learning. Historical data availability is a critical point in developing predictive systems. In oceanography, the available data collection can have some constrains and limitations, which has led to exploring new tools to obtain more exhaustive time series. In this study, a machine learning workflow for predicting the number of cells of a toxic dinoflagellate, Dinophysis acuminata, was developed with several key advancements. Seven machine learning algorithms were compared within two learning paradigms. Notably, the output data from CROCO, the ocean hydrodynamic model, was employed as the primary dataset, palliating the limitation of time-continuous historical data. This study highlights the value of models interpretability, fair models comparison methodology, and the incorporation of Stream Learning models. The model DoME, with an average R2 of 0.77 in the 3-day-ahead prediction, emerged as the most effective and interpretable predictor, outperforming the other algorithms.
Machine Learning in management of precautionary closures caused by lipophilic biotoxins
Feb 14, 2024



Mussel farming is one of the most important aquaculture industries. The main risk to mussel farming is harmful algal blooms (HABs), which pose a risk to human consumption. In Galicia, the Spanish main producer of cultivated mussels, the opening and closing of the production areas is controlled by a monitoring program. In addition to the closures resulting from the presence of toxicity exceeding the legal threshold, in the absence of a confirmatory sampling and the existence of risk factors, precautionary closures may be applied. These decisions are made by experts without the support or formalisation of the experience on which they are based. Therefore, this work proposes a predictive model capable of supporting the application of precautionary closures. Achieving sensitivity, accuracy and kappa index values of 97.34%, 91.83% and 0.75 respectively, the kNN algorithm has provided the best results. This allows the creation of a system capable of helping in complex situations where forecast errors are more common.
Hybrid Machine Learning techniques in the management of harmful algal blooms impact
Feb 14, 2024



Harmful algal blooms (HABs) are episodes of high concentrations of algae that are potentially toxic for human consumption. Mollusc farming can be affected by HABs because, as filter feeders, they can accumulate high concentrations of marine biotoxins in their tissues. To avoid the risk to human consumption, harvesting is prohibited when toxicity is detected. At present, the closure of production areas is based on expert knowledge and the existence of a predictive model would help when conditions are complex and sampling is not possible. Although the concentration of toxin in meat is the method most commonly used by experts in the control of shellfish production areas, it is rarely used as a target by automatic prediction models. This is largely due to the irregularity of the data due to the established sampling programs. As an alternative, the activity status of production areas has been proposed as a target variable based on whether mollusc meat has a toxicity level below or above the legal limit. This new option is the most similar to the actual functioning of the control of shellfish production areas. For this purpose, we have made a comparison between hybrid machine learning models like Neural-Network-Adding Bootstrap (BAGNET) and Discriminative Nearest Neighbor Classification (SVM-KNN) when estimating the state of production areas. The study has been carried out in several estuaries with different levels of complexity in the episodes of algal blooms to demonstrate the generalization capacity of the models in bloom detection. As a result, we could observe that, with an average recall value of 93.41% and without dropping below 90% in any of the estuaries, BAGNET outperforms the other models both in terms of results and robustness.
Q-learning Based System for Path Planning with UAV Swarms in Obstacle Environments
Mar 30, 2023


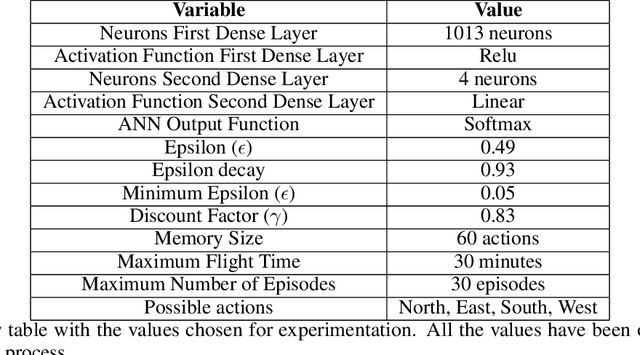
Path Planning methods for autonomous control of Unmanned Aerial Vehicle (UAV) swarms are on the rise because of all the advantages they bring. There are more and more scenarios where autonomous control of multiple UAVs is required. Most of these scenarios present a large number of obstacles, such as power lines or trees. If all UAVs can be operated autonomously, personnel expenses can be decreased. In addition, if their flight paths are optimal, energy consumption is reduced. This ensures that more battery time is left for other operations. In this paper, a Reinforcement Learning based system is proposed for solving this problem in environments with obstacles by making use of Q-Learning. This method allows a model, in this particular case an Artificial Neural Network, to self-adjust by learning from its mistakes and achievements. Regardless of the size of the map or the number of UAVs in the swarm, the goal of these paths is to ensure complete coverage of an area with fixed obstacles for tasks, like field prospecting. Setting goals or having any prior information aside from the provided map is not required. For experimentation, five maps of different sizes with different obstacles were used. The experiments were performed with different number of UAVs. For the calculation of the results, the number of actions taken by all UAVs to complete the task in each experiment is taken into account. The lower the number of actions, the shorter the path and the lower the energy consumption. The results are satisfactory, showing that the system obtains solutions in fewer movements the more UAVs there are. For a better presentation, these results have been compared to another state-of-the-art approach.
Ensemble of Convolution Neural Networks on Heterogeneous Signals for Sleep Stage Scoring
Jul 23, 2021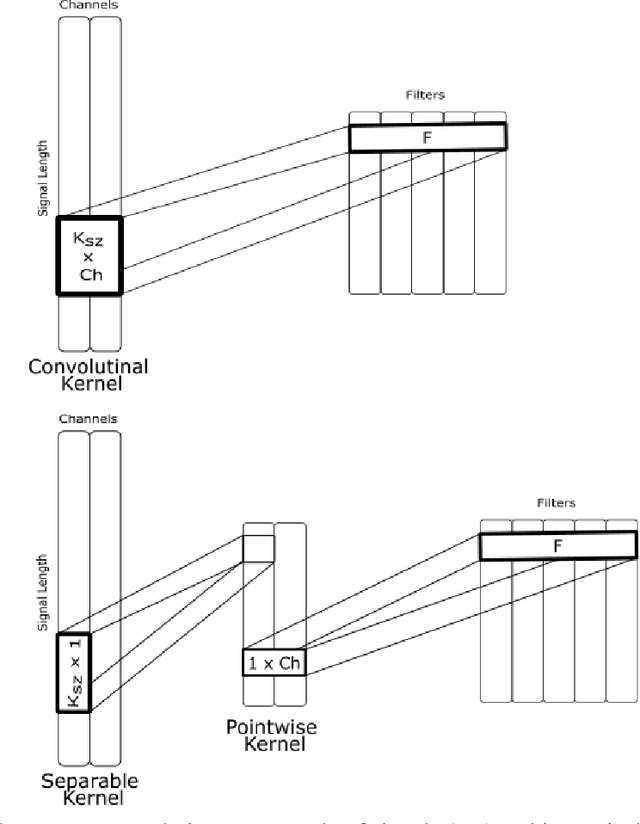

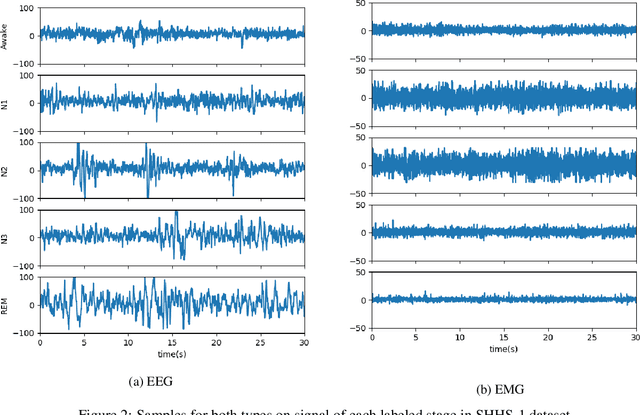
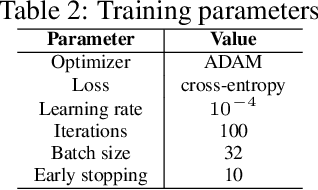
Over the years, several approaches have tried to tackle the problem of performing an automatic scoring of the sleeping stages. Although any polysomnography usually collects over a dozen of different signals, this particular problem has been mainly tackled by using only the Electroencephalograms presented in those records. On the other hand, the other recorded signals have been mainly ignored by most works. This paper explores and compares the convenience of using additional signals apart from electroencephalograms. More specifically, this work uses the SHHS-1 dataset with 5,804 patients containing an electromyogram recorded simultaneously as two electroencephalograms. To compare the results, first, the same architecture has been evaluated with different input signals and all their possible combinations. These tests show how, using more than one signal especially if they are from different sources, improves the results of the classification. Additionally, the best models obtained for each combination of one or more signals have been used in ensemble models and, its performance has been compared showing the convenience of using these multi-signal models to improve the classification. The best overall model, an ensemble of Depth-wise Separational Convolutional Neural Networks, has achieved an accuracy of 86.06\% with a Cohen's Kappa of 0.80 and a $F_{1}$ of 0.77. Up to date, those are the best results on the complete dataset and it shows a significant improvement in the precision and recall for the most uncommon class in the dataset.
Automatic Assessment of Alzheimer's Disease Diagnosis Based on Deep Learning Techniques
May 18, 2021
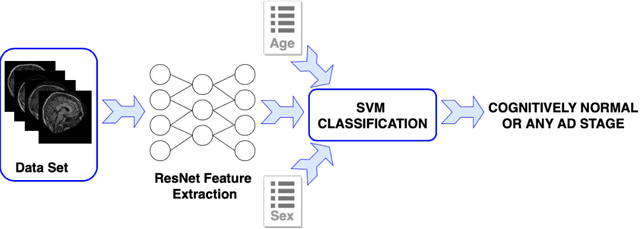
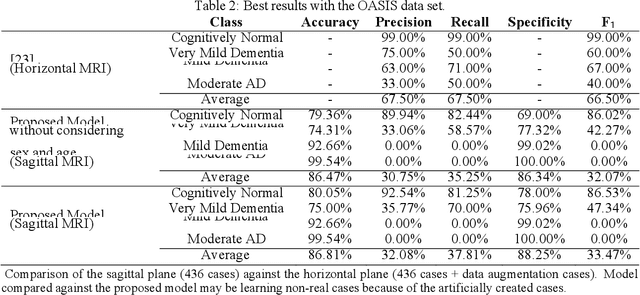
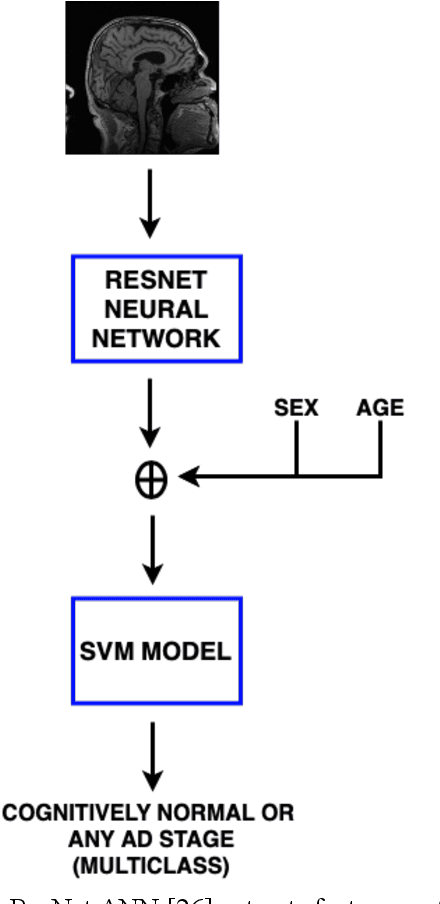
Early detection is crucial to prevent the progression of Alzheimer's disease (AD). Thus, specialists can begin preventive treatment as soon as possible. They demand fast and precise assessment in the diagnosis of AD in the earliest and hardest to detect stages. The main objective of this work is to develop a system that automatically detects the presence of the disease in sagittal magnetic resonance images (MRI), which are not generally used. Sagittal MRIs from ADNI and OASIS data sets were employed. Experiments were conducted using Transfer Learning (TL) techniques in order to achieve more accurate results. There are two main conclusions to be drawn from this work: first, the damages related to AD and its stages can be distinguished in sagittal MRI and, second, the results obtained using DL models with sagittal MRIs are similar to the state-of-the-art, which uses the horizontal-plane MRI. Although sagittal-plane MRIs are not commonly used, this work proved that they were, at least, as effective as MRI from other planes at identifying AD in early stages. This could pave the way for further research. Finally, one should bear in mind that in certain fields, obtaining the examples for a data set can be very expensive. This study proved that DL models could be built in these fields, whereas TL is an essential tool for completing the task with fewer examples.
Convolutional Neural Networks for Sleep Stage Scoring on a Two-Channel EEG Signal
Mar 30, 2021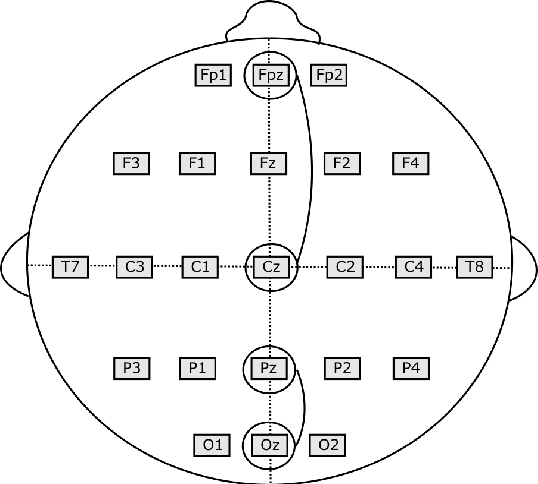

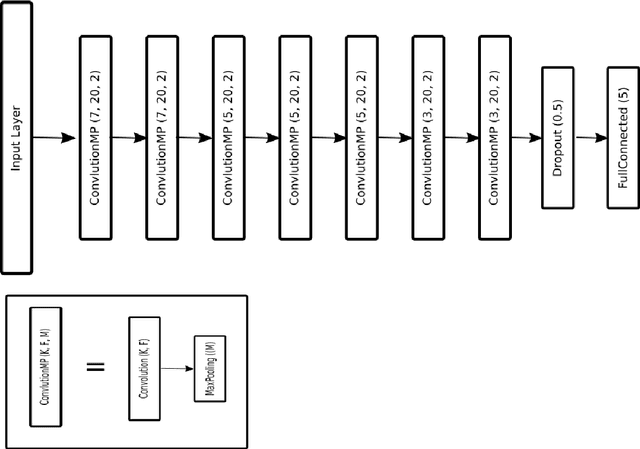
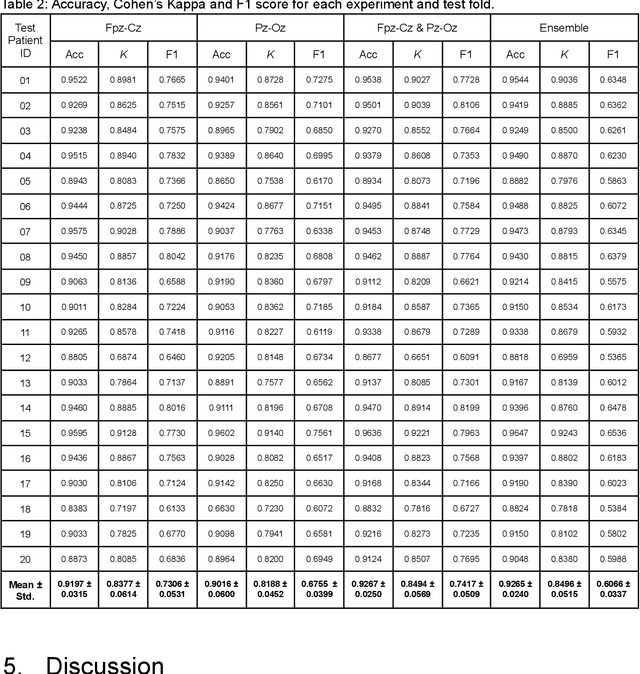
Sleeping problems have become one of the major diseases all over the world. To tackle this issue, the basic tool used by specialists is the Polysomnogram, which is a collection of different signals recorded during sleep. After its recording, the specialists have to score the different signals according to one of the standard guidelines. This process is carried out manually, which can be highly time-consuming and very prone to annotation errors. Therefore, over the years, many approaches have been explored in an attempt to support the specialists in this task. In this paper, an approach based on convolutional neural networks is presented, where an in-depth comparison is performed in order to determine the convenience of using more than one signal simultaneously as input. Additionally, the models were also used as parts of an ensemble model to check whether any useful information can be extracted from signal processing a single signal at a time which the dual-signal model cannot identify. Tests have been performed by using a well-known dataset called expanded sleep-EDF, which is the most commonly used dataset as the benchmark for this problem. The tests were carried out with a leave-one-out cross-validation over the patients, which ensures that there is no possible contamination between training and testing. The resulting proposal is a network smaller than previously published ones, but which overcomes the results of any previous models on the same dataset. The best result shows an accuracy of 92.67\% and a Cohen's Kappa value over 0.84 compared to human experts.
* 20 pages, 4 figures, 4 tables
A New Deterministic Technique for Symbolic Regression
Sep 17, 2019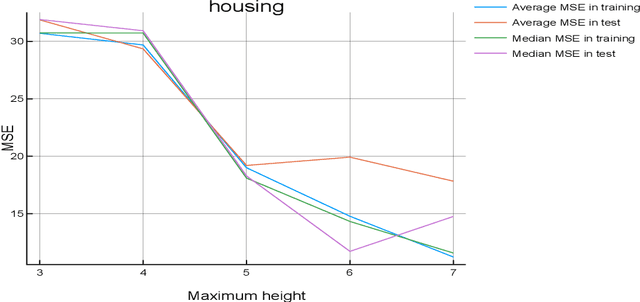
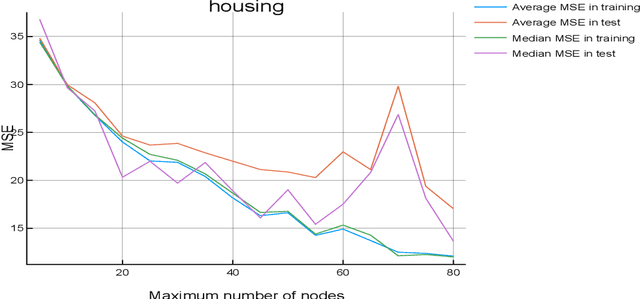
This paper describes a new method for Symbolic Regression that allows to find mathematical expressions from a dataset. This method has a strong mathematical basis. As opposed to other methods such as Genetic Programming, this method is deterministic, and does not involve the creation of a population of initial solutions. Instead of it, a simple expression is being grown until it fits the data. The experiments performed show that the results are as good as other Machine Learning methods, in a very low computational time. Another advantage of this technique is that the complexity of the expressions can be limited, so the system can return mathematical expressions that can be easily analysed by the user, in opposition to other techniques like GSGP.