 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Imitation Learning by Planning
Paper and Code
Mar 26, 2021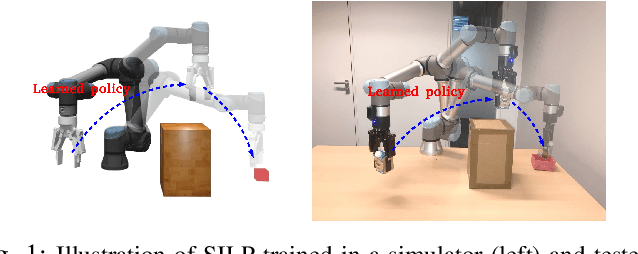
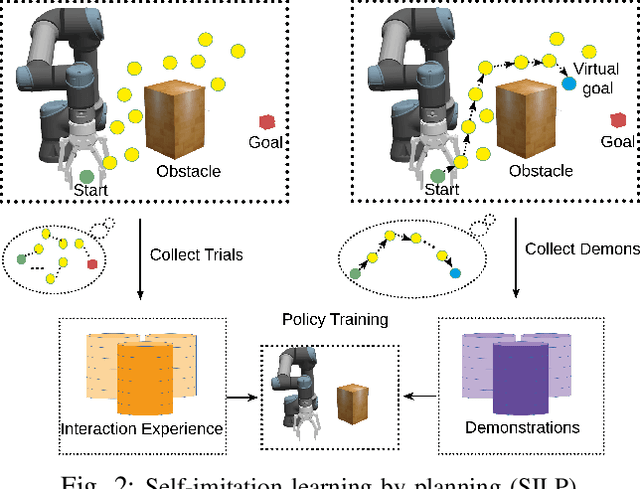
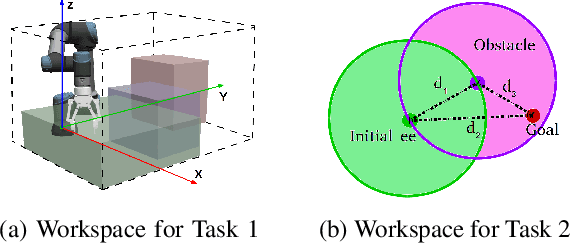
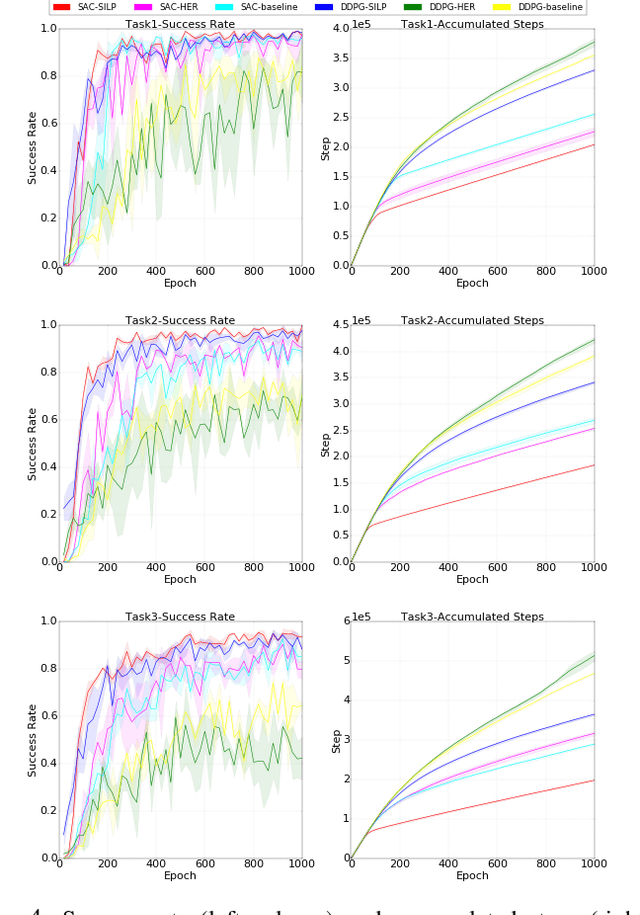
Imitation learning (IL) enables robots to acquire skills quickly by transferring expert knowledge, which is widely adopted in reinforcement learning (RL) to initialize exploration. However, in long-horizon motion planning tasks, a challenging problem in deploying IL and RL methods is how to generate and collect massive, broadly distributed data such that these methods can generalize effectively. In this work, we solve this problem using our proposed approach called {self-imitation learning by planning (SILP)}, where demonstration data are collected automatically by planning on the visited states from the current policy. SILP is inspired by the observation that successfully visited states in the early reinforcement learning stage are collision-free nodes in the graph-search based motion planner, so we can plan and relabel robot's own trials as demonstrations for policy learning. Due to these self-generated demonstrations, we relieve the human operator from the laborious data preparation process required by IL and RL methods in solving complex motion planning tasks. The evaluation results show that our SILP method achieves higher success rates and enhances sample efficiency compared to selected baselines, and the policy learned in simulation performs well in a real-world placement task with changing goals and obstacles.