 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search for GPUs
Aug 29, 2023



Approximate Nearest Neighbor Search (ANNS) plays a critical role in various disciplines spanning data mining and artificial intelligence, from information retrieval and computer vision to natural language processing and recommender systems. Data volumes have soared in recent years and the computational cost of an exhaustive exact nearest neighbor search is often prohibitive, necessitating the adoption of approximate techniques. The balanced performance and recall of graph-based approaches have more recently garnered significant attention in ANNS algorithms, however, only a few studies have explored harnessing the power of GPUs and multi-core processors despite the widespread use of massively parallel and general-purpose computing. To bridge this gap, we introduce a novel parallel computing hardware-based proximity graph and search algorithm. By leveraging the high-performance capabilities of modern hardware, our approach achieves remarkable efficiency gains. In particular, our method surpasses existing CPU and GPU-based methods in constructing the proximity graph, demonstrating higher throughput in both large- and small-batch searches while maintaining compatible accuracy. In graph construction time, our method, CAGRA, is 2.2~27x faster than HNSW, which is one of the CPU SOTA implementations. In large-batch query throughput in the 90% to 95% recall range, our method is 33~77x faster than HNSW, and is 3.8~8.8x faster than the SOTA implementations for GPU. For a single query, our method is 3.4~53x faster than HNSW at 95% recall.
Machine Learning in Python: Main developments and technology trends in data science, machine learning, and artificial intelligence
Feb 12, 2020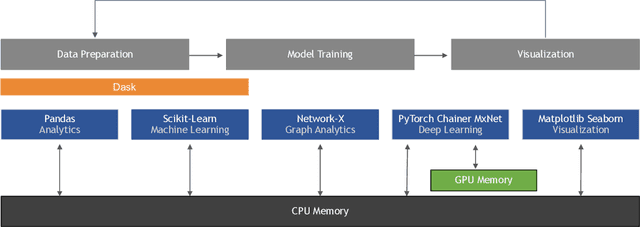
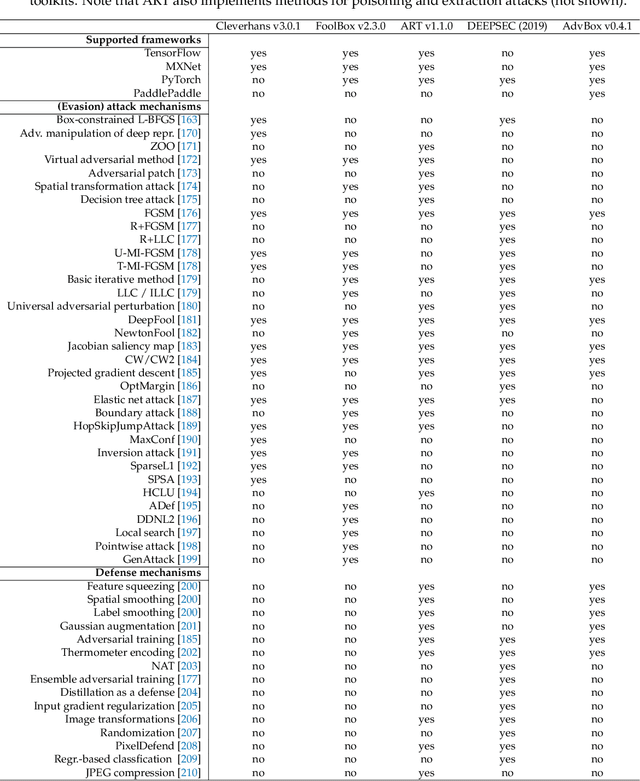
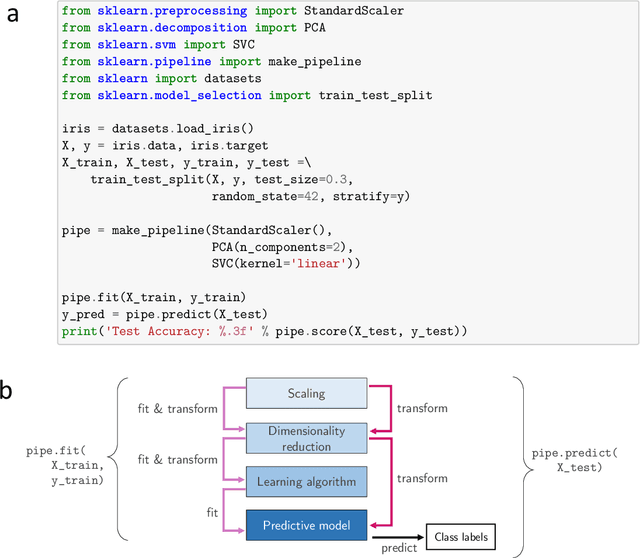

Smarter applications are making better use of the insights gleaned from data, having an impact on every industry and research discipline. At the core of this revolution lies the tools and the methods that are driving it, from processing the massive piles of data generated each day to learning from and taking useful action. Deep neural networks, along with advancements in classical ML and scalable general-purpose GPU computing, have become critical components of artificial intelligence, enabling many of these astounding breakthroughs and lowering the barrier to adoption. Python continues to be the most preferred language for scientific computing, data science, and machine learning, boosting both performance and productivity by enabling the use of low-level libraries and clean high-level APIs. This survey offers insight into the field of machine learning with Python, taking a tour through important topics to identify some of the core hardware and software paradigms that have enabled it. We cover widely-used libraries and concepts, collected together for holistic comparison, with the goal of educating the reader and driving the field of Python machine learning forward.