 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImperfect Influence, Preserved Rankings: A Theory of TRAK for Data Attribution
Feb 01, 2026Data attribution, tracing a model's prediction back to specific training data, is an important tool for interpreting sophisticated AI models. The widely used TRAK algorithm addresses this challenge by first approximating the underlying model with a kernel machine and then leveraging techniques developed for approximating the leave-one-out (ALO) risk. Despite its strong empirical performance, the theoretical conditions under which the TRAK approximations are accurate as well as the regimes in which they break down remain largely unexplored. In this paper, we provide a theoretical analysis of the TRAK algorithm, characterizing its performance and quantifying the errors introduced by the approximations on which the method relies. We show that although the approximations incur significant errors, TRAK's estimated influence remains highly correlated with the original influence and therefore largely preserves the relative ranking of data points. We corroborate our theoretical results through extensive simulations and empirical studies.
Representation Learning to Advance Multi-institutional Studies with Electronic Health Record Data
Feb 12, 2025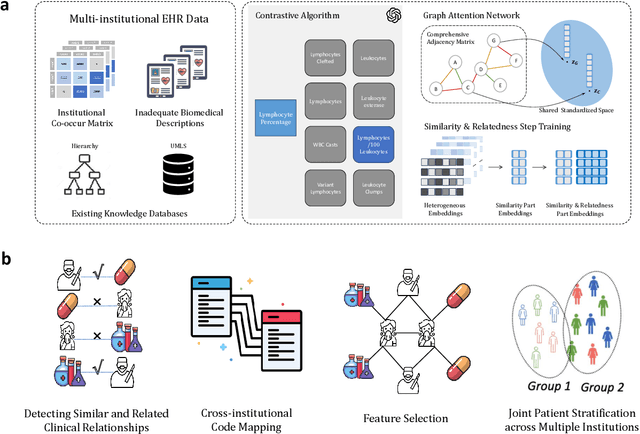
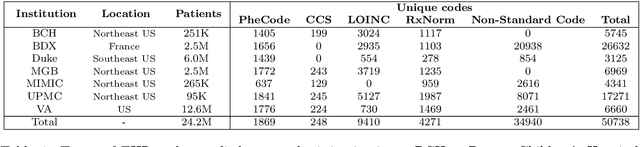
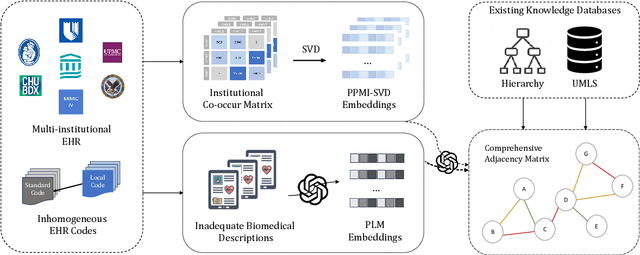

The adoption of EHRs has expanded opportunities to leverage data-driven algorithms in clinical care and research. A major bottleneck in effectively conducting multi-institutional EHR studies is the data heterogeneity across systems with numerous codes that either do not exist or represent different clinical concepts across institutions. The need for data privacy further limits the feasibility of including multi-institutional patient-level data required to study similarities and differences across patient subgroups. To address these challenges, we developed the GAME algorithm. Tested and validated across 7 institutions and 2 languages, GAME integrates data in several levels: (1) at the institutional level with knowledge graphs to establish relationships between codes and existing knowledge sources, providing the medical context for standard codes and their relationship to each other; (2) between institutions, leveraging language models to determine the relationships between institution-specific codes with established standard codes; and (3) quantifying the strength of the relationships between codes using a graph attention network. Jointly trained embeddings are created using transfer and federated learning to preserve data privacy. In this study, we demonstrate the applicability of GAME in selecting relevant features as inputs for AI-driven algorithms in a range of conditions, e.g., heart failure, rheumatoid arthritis. We then highlight the application of GAME harmonized multi-institutional EHR data in a study of Alzheimer's disease outcomes and suicide risk among patients with mental health disorders, without sharing patient-level data outside individual institutions.