 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated One-Shot Ensemble Clustering
Sep 12, 2024Cluster analysis across multiple institutions poses significant challenges due to data-sharing restrictions. To overcome these limitations, we introduce the Federated One-shot Ensemble Clustering (FONT) algorithm, a novel solution tailored for multi-site analyses under such constraints. FONT requires only a single round of communication between sites and ensures privacy by exchanging only fitted model parameters and class labels. The algorithm combines locally fitted clustering models into a data-adaptive ensemble, making it broadly applicable to various clustering techniques and robust to differences in cluster proportions across sites. Our theoretical analysis validates the effectiveness of the data-adaptive weights learned by FONT, and simulation studies demonstrate its superior performance compared to existing benchmark methods. We applied FONT to identify subgroups of patients with rheumatoid arthritis across two health systems, revealing improved consistency of patient clusters across sites, while locally fitted clusters proved less transferable. FONT is particularly well-suited for real-world applications with stringent communication and privacy constraints, offering a scalable and practical solution for multi-site clustering.
LATTE: Label-efficient Incident Phenotyping from Longitudinal Electronic Health Records
May 19, 2023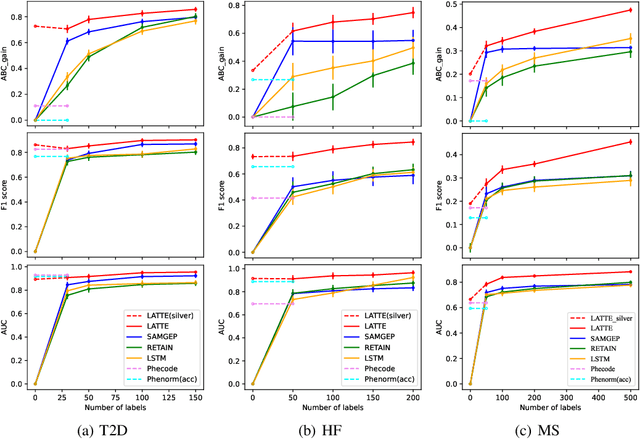
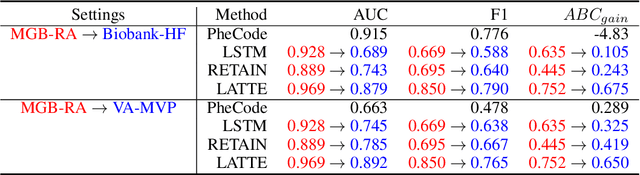
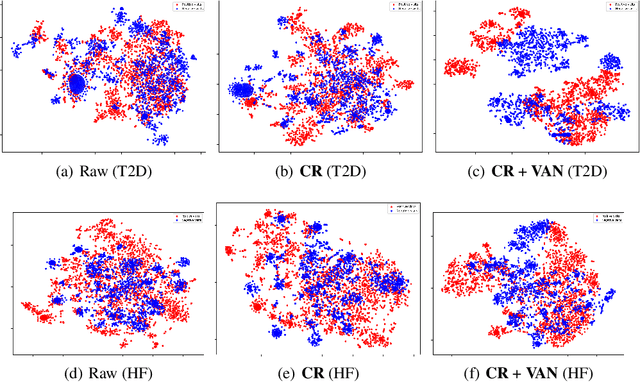

Electronic health record (EHR) data are increasingly used to support real-world evidence (RWE) studies. Yet its ability to generate reliable RWE is limited by the lack of readily available precise information on the timing of clinical events such as the onset time of heart failure. We propose a LAbel-efficienT incidenT phEnotyping (LATTE) algorithm to accurately annotate the timing of clinical events from longitudinal EHR data. By leveraging the pre-trained semantic embedding vectors from large-scale EHR data as prior knowledge, LATTE selects predictive EHR features in a concept re-weighting module by mining their relationship to the target event and compresses their information into longitudinal visit embeddings through a visit attention learning network. LATTE employs a recurrent neural network to capture the sequential dependency between the target event and visit embeddings before/after it. To improve label efficiency, LATTE constructs highly informative longitudinal silver-standard labels from large-scale unlabeled patients to perform unsupervised pre-training and semi-supervised joint training. Finally, LATTE enhances cross-site portability via contrastive representation learning. LATTE is evaluated on three analyses: the onset of type-2 diabetes, heart failure, and the onset and relapses of multiple sclerosis. We use various evaluation metrics present in the literature including the $ABC_{gain}$, the proportion of reduction in the area between the observed event indicator and the predicted cumulative incidences in reference to the prediction per incident prevalence. LATTE consistently achieves substantial improvement over benchmark methods such as SAMGEP and RETAIN in all settings.