 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROSAR: An Adversarial Re-Training Framework for Robust Side-Scan Sonar Object Detection
Oct 14, 2024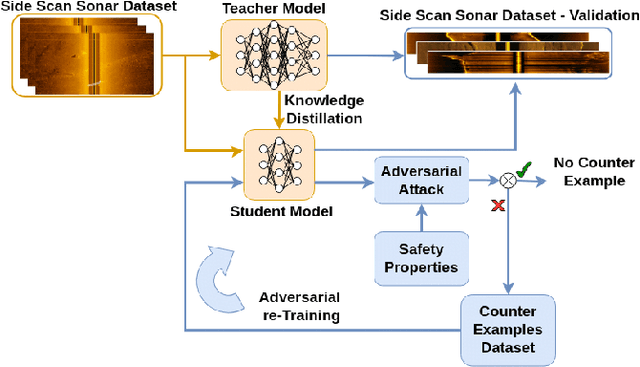


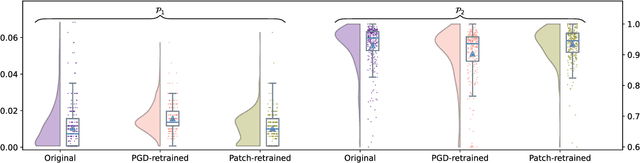
This paper introduces ROSAR, a novel framework enhancing the robustness of deep learning object detection models tailored for side-scan sonar (SSS) images, generated by autonomous underwater vehicles using sonar sensors. By extending our prior work on knowledge distillation (KD), this framework integrates KD with adversarial retraining to address the dual challenges of model efficiency and robustness against SSS noises. We introduce three novel, publicly available SSS datasets, capturing different sonar setups and noise conditions. We propose and formalize two SSS safety properties and utilize them to generate adversarial datasets for retraining. Through a comparative analysis of projected gradient descent (PGD) and patch-based adversarial attacks, ROSAR demonstrates significant improvements in model robustness and detection accuracy under SSS-specific conditions, enhancing the model's robustness by up to 1.85%. ROSAR is available at https://github.com/remaro-network/ROSAR-framework.
Unsupervised Contrastive Analysis for Salient Pattern Detection using Conditional Diffusion Models
Jun 04, 2024



Contrastive Analysis (CA) regards the problem of identifying patterns in images that allow distinguishing between a background (BG) dataset (i.e. healthy subjects) and a target (TG) dataset (i.e. unhealthy subjects). Recent works on this topic rely on variational autoencoders (VAE) or contrastive learning strategies to learn the patterns that separate TG samples from BG samples in a supervised manner. However, the dependency on target (unhealthy) samples can be challenging in medical scenarios due to their limited availability. Also, the blurred reconstructions of VAEs lack utility and interpretability. In this work, we redefine the CA task by employing a self-supervised contrastive encoder to learn a latent representation encoding only common patterns from input images, using samples exclusively from the BG dataset during training, and approximating the distribution of the target patterns by leveraging data augmentation techniques. Subsequently, we exploit state-of-the-art generative methods, i.e. diffusion models, conditioned on the learned latent representation to produce a realistic (healthy) version of the input image encoding solely the common patterns. Thorough validation on a facial image dataset and experiments across three brain MRI datasets demonstrate that conditioning the generative process of state-of-the-art generative methods with the latent representation from our self-supervised contrastive encoder yields improvements in the generated image quality and in the accuracy of image classification. The code is available at https://github.com/CristianoPatricio/unsupervised-contrastive-cond-diff.
Autoencoders as Weight Initialization of Deep Classification Networks for Cancer versus Cancer Studies
Jan 15, 2020
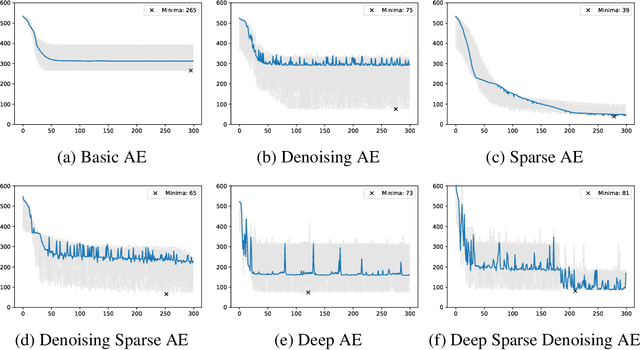
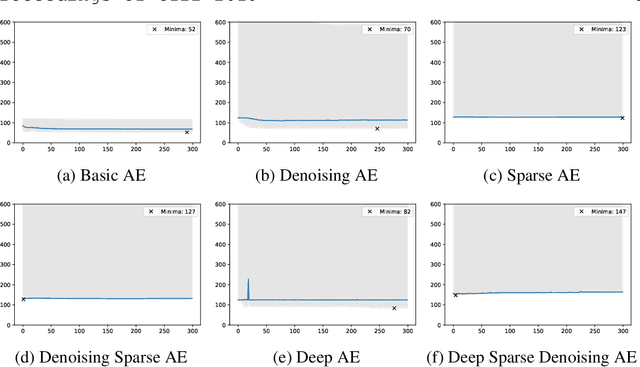

Cancer is still one of the most devastating diseases of our time. One way of automatically classifying tumor samples is by analyzing its derived molecular information (i.e., its genes expression signatures). In this work, we aim to distinguish three different types of cancer: thyroid, skin, and stomach. For that, we compare the performance of a Denoising Autoencoder (DAE) used as weight initialization of a deep neural network. Although we address a different domain problem in this work, we have adopted the same methodology of Ferreira et al.. In our experiments, we assess two different approaches when training the classification model: (a) fixing the weights, after pre-training the DAE, and (b) allowing fine-tuning of the entire classification network. Additionally, we apply two different strategies for embedding the DAE into the classification network: (1) by only importing the encoding layers, and (2) by inserting the complete autoencoder. Our best result was the combination of unsupervised feature learning through a DAE, followed by its full import into the classification network, and subsequent fine-tuning through supervised training, achieving an F1 score of 98.04% +/- 1.09 when identifying cancerous thyroid samples.
GarmNet: Improving Global with Local Perception for Robotic Laundry Folding
Jun 30, 2019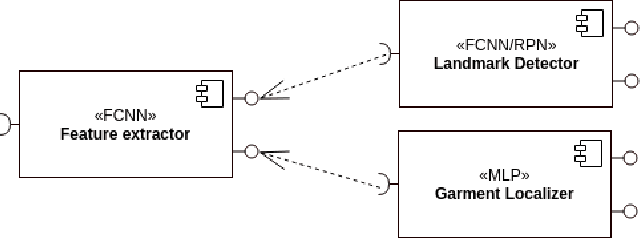
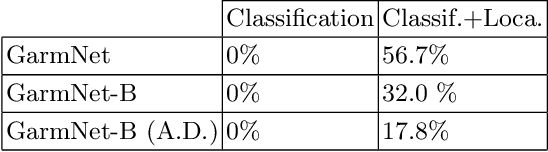
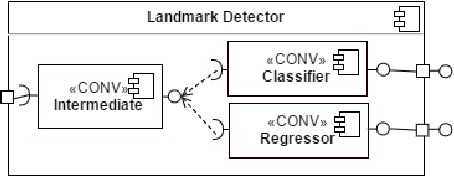
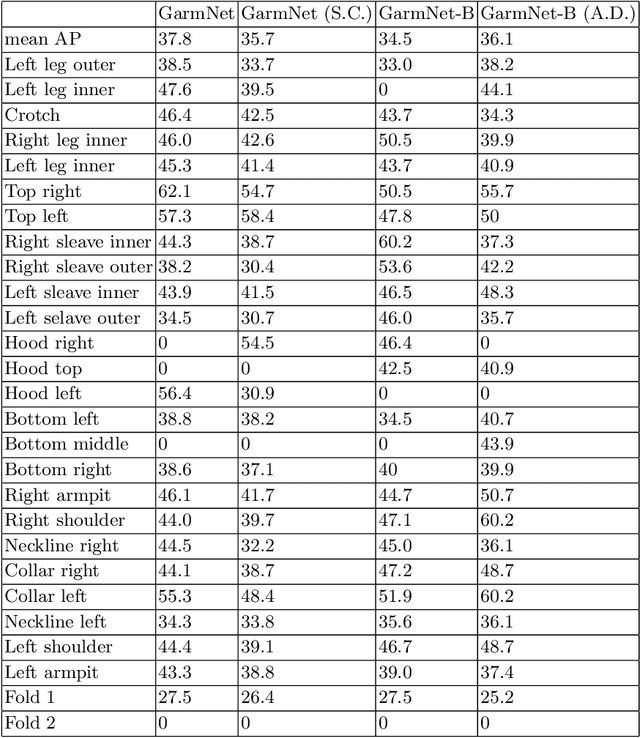
Developing autonomous assistants to help with domestic tasks is a vital topic in robotics research. Among these tasks, garment folding is one of them that is still far from being achieved mainly due to the large number of possible configurations that a crumpled piece of clothing may exhibit. Research has been done on either estimating the pose of the garment as a whole or detecting the landmarks for grasping separately. However, such works constrain the capability of the robots to perceive the states of the garment by limiting the representations for one single task. In this paper, we propose a novel end-to-end deep learning model named GarmNet that is able to simultaneously localize the garment and detect landmarks for grasping. The localization of the garment represents the global information for recognising the category of the garment, whereas the detection of landmarks can facilitate subsequent grasping actions. We train and evaluate our proposed GarmNet model using the CloPeMa Garment dataset that contains 3,330 images of different garment types in different poses. The experiments show that the inclusion of landmark detection (GarmNet-B) can largely improve the garment localization, with an error rate of 24.7% lower. Solutions as ours are important for robotics applications, as these offer scalable to many classes, memory and processing efficient solutions.
Active Mining of Parallel Video Streams
May 14, 2014

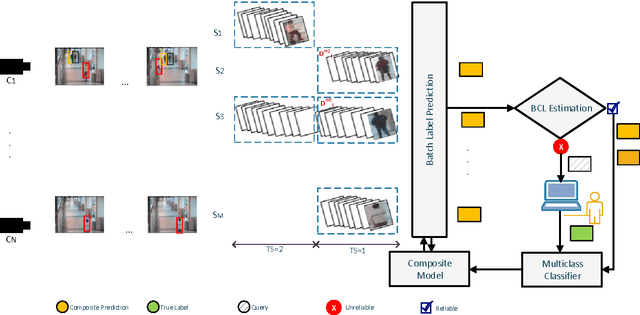

The practicality of a video surveillance system is adversely limited by the amount of queries that can be placed on human resources and their vigilance in response. To transcend this limitation, a major effort under way is to include software that (fully or at least semi) automatically mines video footage, reducing the burden imposed to the system. Herein, we propose a semi-supervised incremental learning framework for evolving visual streams in order to develop a robust and flexible track classification system. Our proposed method learns from consecutive batches by updating an ensemble in each time. It tries to strike a balance between performance of the system and amount of data which needs to be labelled. As no restriction is considered, the system can address many practical problems in an evolving multi-camera scenario, such as concept drift, class evolution and various length of video streams which have not been addressed before. Experiments were performed on synthetic as well as real-world visual data in non-stationary environments, showing high accuracy with fairly little human collaboration.