 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimTac: A Physics-Based Simulator for Vision-Based Tactile Sensing with Biomorphic Structures
Nov 14, 2025Tactile sensing in biological organisms is deeply intertwined with morphological form, such as human fingers, cat paws, and elephant trunks, which enables rich and adaptive interactions through a variety of geometrically complex structures. In contrast, vision-based tactile sensors in robotics have been limited to simple planar geometries, with biomorphic designs remaining underexplored. To address this gap, we present SimTac, a physics-based simulation framework for the design and validation of biomorphic tactile sensors. SimTac consists of particle-based deformation modeling, light-field rendering for photorealistic tactile image generation, and a neural network for predicting mechanical responses, enabling accurate and efficient simulation across a wide range of geometries and materials. We demonstrate the versatility of SimTac by designing and validating physical sensor prototypes inspired by biological tactile structures and further demonstrate its effectiveness across multiple Sim2Real tactile tasks, including object classification, slip detection, and contact safety assessment. Our framework bridges the gap between bio-inspired design and practical realisation, expanding the design space of tactile sensors and paving the way for tactile sensing systems that integrate morphology and sensing to enable robust interaction in unstructured environments.
RoTipBot: Robotic Handling of Thin and Flexible Objects using Rotatable Tactile Sensors
Jun 13, 2024



This paper introduces RoTipBot, a novel robotic system for handling thin, flexible objects. Different from previous works that are limited to singulating them using suction cups or soft grippers, RoTipBot can grasp and count multiple layers simultaneously, emulating human handling in various environments. Specifically, we develop a novel vision-based tactile sensor named RoTip that can rotate and sense contact information around its tip. Equipped with two RoTip sensors, RoTipBot feeds multiple layers of thin, flexible objects into the centre between its fingers, enabling effective grasping and counting. RoTip's tactile sensing ensures both fingers maintain good contact with the object, and an adjustment approach is designed to allow the gripper to adapt to changes in the object. Extensive experiments demonstrate the efficacy of the RoTip sensor and the RoTipBot approach. The results show that RoTipBot not only achieves a higher success rate but also grasps and counts multiple layers simultaneously -- capabilities not possible with previous methods. Furthermore, RoTipBot operates up to three times faster than state-of-the-art methods. The success of RoTipBot paves the way for future research in object manipulation using mobilised tactile sensors. All the materials used in this paper are available at \url{https://sites.google.com/view/rotipbot}.
Beyond Flat GelSight Sensors: Simulation of Optical Tactile Sensors of Complex Morphologies for Sim2Real Learning
May 21, 2023



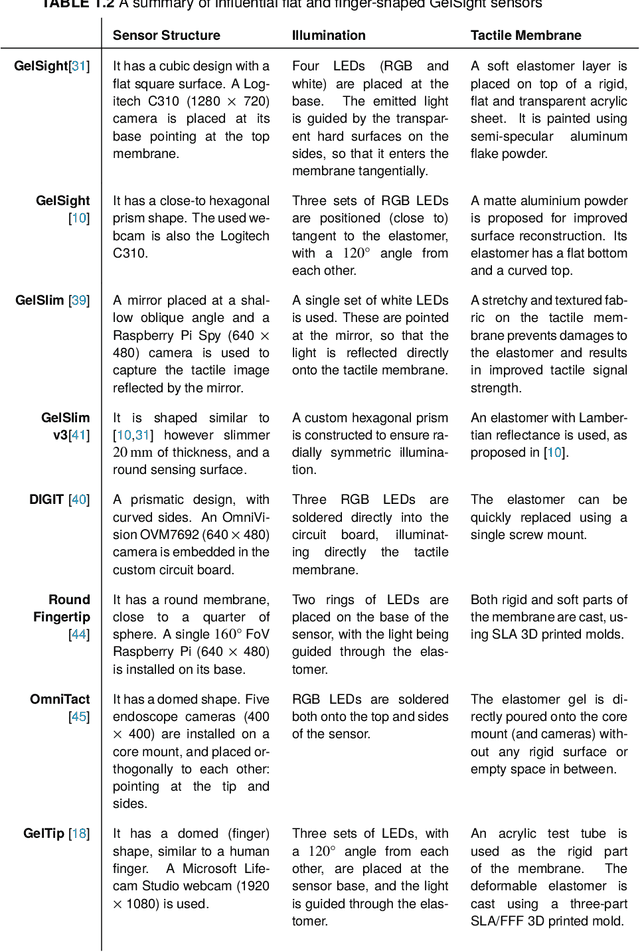
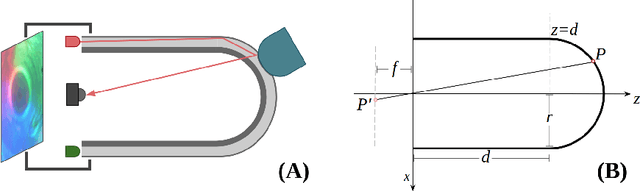
Recently, several morphologies, each with its advantages, have been proposed for the \textit{GelSight} high-resolution tactile sensors. However, existing simulation methods are limited to flat-surface sensors, which prevents their usage with the newer sensors of non-flat morphologies in Sim2Real experiments. In this paper, we extend a previously proposed GelSight simulation method developed for flat-surface sensors and propose a novel method for curved sensors. In particular, we address the simulation of light rays travelling through a curved tactile membrane in the form of geodesic paths. The method is validated by simulating the finger-shaped GelTip sensor and comparing the generated synthetic tactile images against the corresponding real images. Our extensive experiments show that combining the illumination generated from the geodesic paths, with a background image from the real sensor, produces the best results when compared to the lighting generated by direct linear paths in the same conditions. As the method is parameterised by the sensor mesh, it can be applied in principle to simulate a tactile sensor of any morphology. The proposed method not only unlocks simulating existing optical tactile sensors of complex morphologies but also enables experimenting with sensors of novel morphologies, before the fabrication of the real sensor. Project website: https://danfergo.github.io/geltip-sim
GelTip Tactile Sensor for Dexterous Manipulation in Clutter
Dec 03, 2021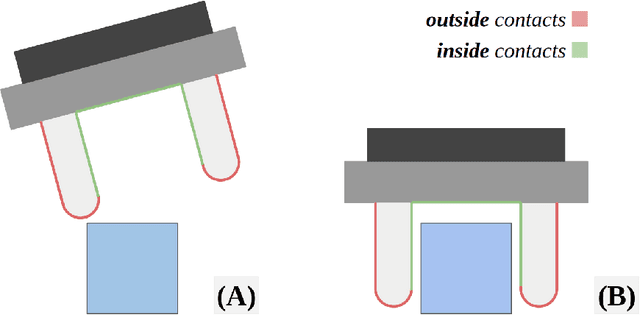
Tactile sensing is an essential capability for robots that carry out dexterous manipulation tasks. While cameras, Lidars and other remote sensors can assess a scene globally and instantly, tactile sensors can reduce their measurement uncertainties and gain information about the local physical interactions between the in-contact objects and the robot, that are often not accessible via remote sensing. Tactile sensors can be grouped into two main categories: electronic tactile skins and camera based optical tactile sensors. The former are slim and can be fitted to different body parts, whereas the latter assume a more prismatic shape and have much higher sensing resolutions, offering a good advantage for being used as robotic fingers or fingertips. One of such optical tactile sensors is our GelTip sensor that is shaped as a finger and can sense contacts on any location of its surface. As such, the GelTip sensor is able to detect contacts from all the directions, like a human finger. To capture these contacts, it uses a camera installed at its base to track the deformations of the opaque elastomer that covers its hollow, rigid and transparent body. Thanks to this design, a gripper equipped with GelTip sensors is capable of simultaneously monitoring contacts happening inside and outside its grasp closure. Experiments carried out using this sensor demonstrate how contacts can be localised, and more importantly, the advantages, and even possibly a necessity, of leveraging all-around touch sensing in dexterous manipulation tasks in clutter where contacts may happen at any location of the finger. All the materials for the fabrication of the GelTip sensor can be found at https://danfergo.github.io/geltip/
Reducing Tactile Sim2Real Domain Gaps via Deep Texture Generation Networks
Dec 03, 2021
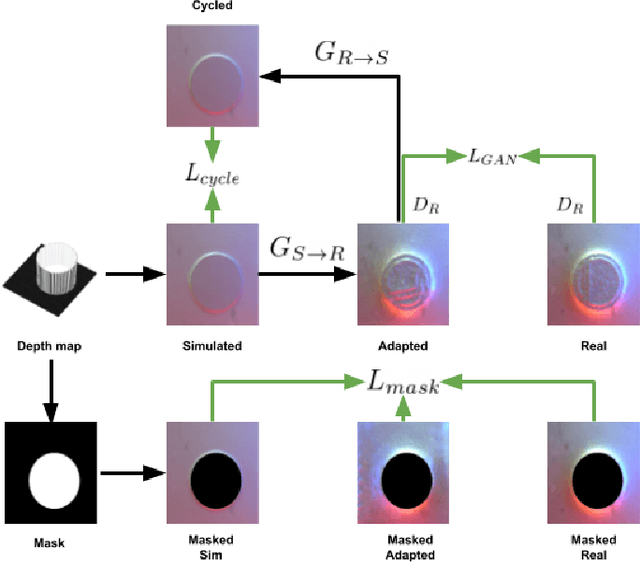


Recently simulation methods have been developed for optical tactile sensors to enable the Sim2Real learning, i.e., firstly training models in simulation before deploying them on the real robot. However, some artefacts in the real objects are unpredictable, such as imperfections caused by fabrication processes, or scratches by the natural wear and tear, and thus cannot be represented in the simulation, resulting in a significant gap between the simulated and real tactile images. To address this Sim2Real gap, we propose a novel texture generation network that maps the simulated images into photorealistic tactile images that resemble a real sensor contacting a real imperfect object. Each simulated tactile image is first divided into two types of regions: areas that are in contact with the object and areas that are not. The former is applied with generated textures learned from real textures in the real tactile images, whereas the latter maintains its appearance as when the sensor is not in contact with any object. This makes sure that the artefacts are only applied to the deformed regions of the sensor. Our extensive experiments show that the proposed texture generation network can generate these realistic artefacts on the deformed regions of the sensor, while avoiding leaking the textures into areas of no contact. Quantitative experiments further reveal that when using the adapted images generated by our proposed network for a Sim2Real classification task, the drop in accuracy caused by the Sim2Real gap is reduced from 38.43% to merely 0.81%. As such, this work has the potential to accelerate the Sim2Real learning for robotic tasks requiring tactile sensing.
Vision-Guided Active Tactile Perception for Crack Detection and Reconstruction
May 13, 2021



Crack detection is of great significance for monitoring the integrity and well-being of the infrastructure such as bridges and underground pipelines, which are harsh environments for people to access. In recent years, computer vision techniques have been applied in detecting cracks in concrete structures. However, they suffer from variances in light conditions and shadows, lacking robustness and resulting in many false positives. To address the uncertainty in vision, human inspectors actively touch the surface of the structures, guided by vision, which has not been explored in autonomous crack detection. In this paper, we propose a novel approach to detect and reconstruct cracks in concrete structures using vision-guided active tactile perception. Given an RGB-D image of a structure, the rough profile of the crack in the structure surface will first be segmented with a fine-tuned Deep Convolutional Neural Networks, and a set of contact points are generated to guide the collection of tactile images by a camera-based optical tactile sensor. When contacts are made, a pixel-wise mask of the crack can be obtained from the tactile images and therefore the profile of the crack can be refined by aligning the RGB-D image and the tactile images. Extensive experiment results have shown that the proposed method improves the effectiveness and robustness of crack detection and reconstruction significantly, compared to crack detection with vision only, and has the potential to enable robots to help humans with the inspection and repair of the concrete infrastructure.
TouchRoller: A Rolling Optical Tactile Sensor for Rapid Assessment of Large Surfaces
Feb 28, 2021

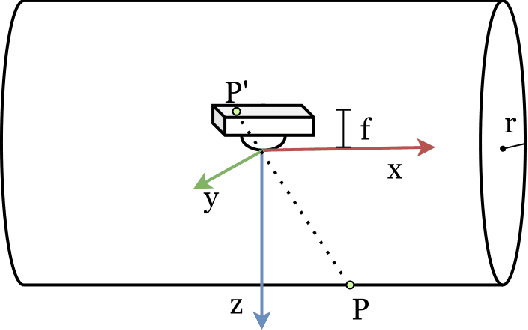

Tactile sensing is important for robots to perceive the world as it captures the texture and hardness of the object in contact and is robust to illumination and colour variances. However, due to the limited sensing area and the resistance of the fixed surface, current tactile sensors have to tap the tactile sensor on target object many times when assessing a large surface, i.e., pressing, lifting up and shifting to another region. This process is ineffective and time consuming. It is also undesirable to drag such sensors as this often damages the sensitive membrane of the sensor or the object. To address these problems, we propose a cylindrical optical tactile sensor named TouchRoller that can roll around its center axis. It maintains being in contact with the assessed surface throughout the entire motion, which allows for measuring the object continuously and effectively. Extensive experiments show that the TouchRoller sensor can cover a textured surface of 8cm*11cm in a short time of 10s, much more effectively than a flat optical tactile sensor (in 196s). The reconstructed map of the texture from the collected tactile images has a high Structural Similarity Index (SSIM) of 0.31 on average, when compared with the visual texture. In addition, the contacts on the sensor can be localised with a low localisation error, 2.63mm in the center regions and 7.66mm on average. The proposed sensor will enable the fast assessment of large surfaces with high-resolution tactile sensing, and also the effective collection of tactile images.
Generation of GelSight Tactile Images for Sim2Real Learning
Jan 18, 2021



Most current works in Sim2Real learning for robotic manipulation tasks leverage camera vision that may be significantly occluded by robot hands during the manipulation. Tactile sensing offers complementary information to vision and can compensate for the information loss caused by the occlusion. However, the use of tactile sensing is restricted in the Sim2Real research due to no simulated tactile sensors being available. To mitigate the gap, we introduce a novel approach for simulating a GelSight tactile sensor in the commonly used Gazebo simulator. Similar to the real GelSight sensor, the simulated sensor can produce high-resolution images by an optical sensor from the interaction between the touched object and an opaque soft membrane. It can indirectly sense forces, geometry, texture and other properties of the object and enables Sim2Real learning with tactile sensing. Preliminary experimental results have shown that the simulated sensor could generate realistic outputs similar to the ones captured by a real GelSight sensor. All the materials used in this paper are available at https://danfergo.github.io/gelsight-simulation.
GelTip: A Finger-shaped Optical Tactile Sensor for Robotic Manipulation
Aug 12, 2020
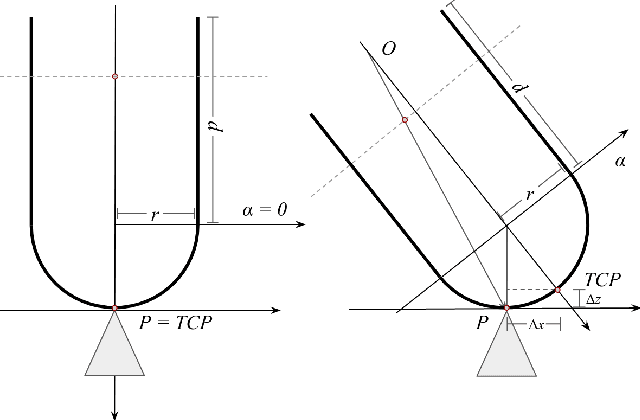
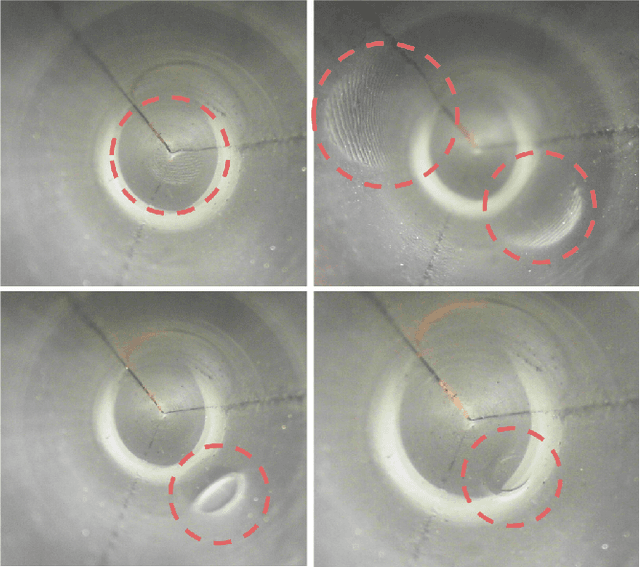
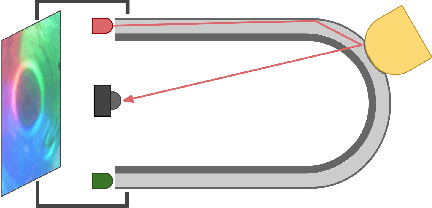
Sensing contacts throughout the fingers is an essential capability for a robot to perform manipulation tasks in cluttered environments. However, existing tactile sensors either only have a flat sensing surface or a compliant tip with a limited sensing area. In this paper, we propose a novel optical tactile sensor, the GelTip, that is shaped as a finger and can sense contacts on any location of its surface. The sensor captures high-resolution and color-invariant tactile images that can be exploited to extract detailed information about the end-effector's interactions against manipulated objects. Our extensive experiments show that the GelTip sensor can effectively localise the contacts on different locations of its finger-shaped body, with a small localisation error of approximately 5 mm, on average, and under 1 mm in the best cases. The obtained results show the potential of the GelTip sensor in facilitating dynamic manipulation tasks with its all-round tactile sensing capability. The sensor models and further information about the GelTip sensor can be found at http://danfergo.github.io/geltip.
GarmNet: Improving Global with Local Perception for Robotic Laundry Folding
Jun 30, 2019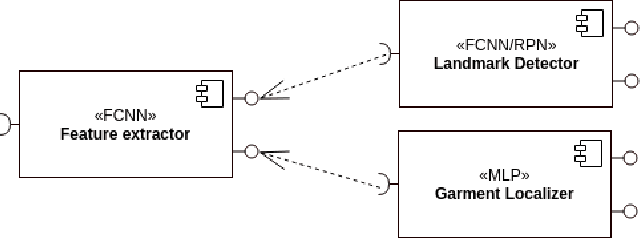
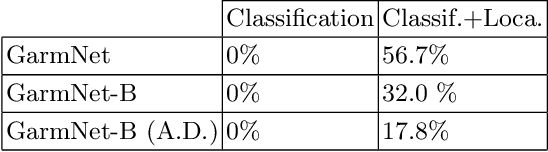
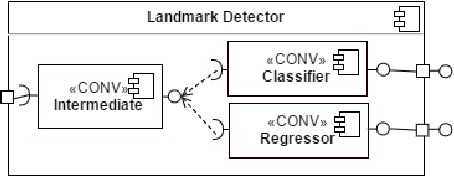
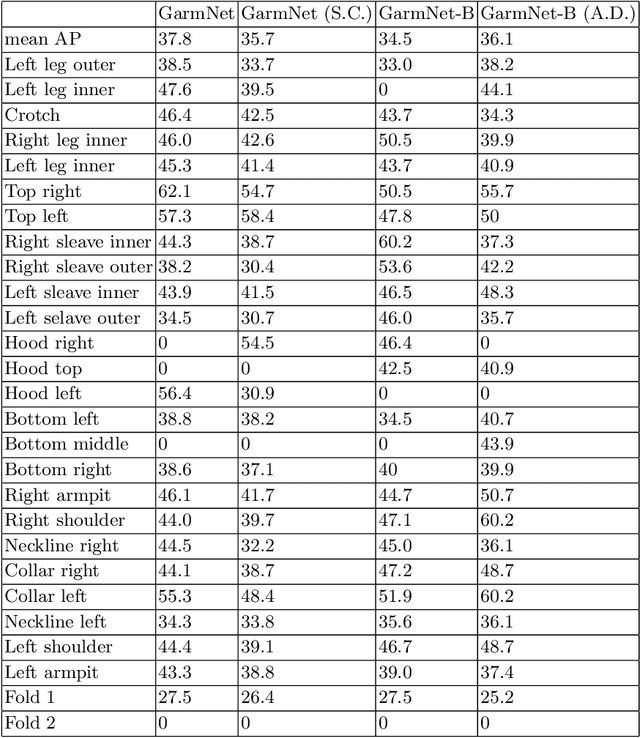
Developing autonomous assistants to help with domestic tasks is a vital topic in robotics research. Among these tasks, garment folding is one of them that is still far from being achieved mainly due to the large number of possible configurations that a crumpled piece of clothing may exhibit. Research has been done on either estimating the pose of the garment as a whole or detecting the landmarks for grasping separately. However, such works constrain the capability of the robots to perceive the states of the garment by limiting the representations for one single task. In this paper, we propose a novel end-to-end deep learning model named GarmNet that is able to simultaneously localize the garment and detect landmarks for grasping. The localization of the garment represents the global information for recognising the category of the garment, whereas the detection of landmarks can facilitate subsequent grasping actions. We train and evaluate our proposed GarmNet model using the CloPeMa Garment dataset that contains 3,330 images of different garment types in different poses. The experiments show that the inclusion of landmark detection (GarmNet-B) can largely improve the garment localization, with an error rate of 24.7% lower. Solutions as ours are important for robotics applications, as these offer scalable to many classes, memory and processing efficient solutions.