 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyGen2Vec: Learning Document Embedding via Multi-label Keyword Generation in Question-Answering
Oct 30, 2023



Representing documents into high dimensional embedding space while preserving the structural similarity between document sources has been an ultimate goal for many works on text representation learning. Current embedding models, however, mainly rely on the availability of label supervision to increase the expressiveness of the resulting embeddings. In contrast, unsupervised embeddings are cheap, but they often cannot capture implicit structure in target corpus, particularly for samples that come from different distribution with the pretraining source. Our study aims to loosen up the dependency on label supervision by learning document embeddings via Sequence-to-Sequence (Seq2Seq) text generator. Specifically, we reformulate keyphrase generation task into multi-label keyword generation in community-based Question Answering (cQA). Our empirical results show that KeyGen2Vec in general is superior than multi-label keyword classifier by up to 14.7% based on Purity, Normalized Mutual Information (NMI), and F1-Score metrics. Interestingly, although in general the absolute advantage of learning embeddings through label supervision is highly positive across evaluation datasets, KeyGen2Vec is shown to be competitive with classifier that exploits topic label supervision in Yahoo! cQA with larger number of latent topic labels.
ViDi: Descriptive Visual Data Clustering as Radiologist Assistant in COVID-19 Streamline Diagnostic
Nov 30, 2020
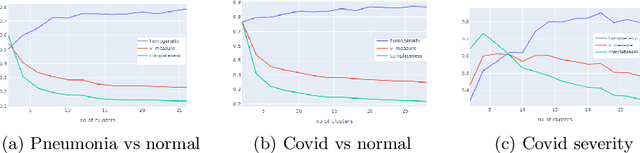

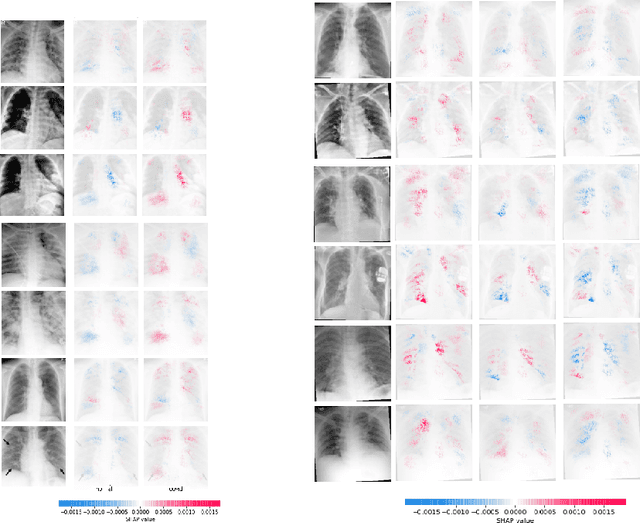
In the light of the COVID-19 pandemic, deep learning methods have been widely investigated in detecting COVID-19 from chest X-rays. However, a more pragmatic approach to applying AI methods to a medical diagnosis is designing a framework that facilitates human-machine interaction and expert decision making. Studies have shown that categorization can play an essential rule in accelerating real-world decision making. Inspired by descriptive document clustering, we propose a domain-independent explanatory clustering framework to group contextually related instances and support radiologists' decision making. While most descriptive clustering approaches employ domain-specific characteristics to form meaningful clusters, we focus on model-level explanation as a more general-purpose element of every learning process to achieve cluster homogeneity. We employ DeepSHAP to generate homogeneous clusters in terms of disease severity and describe the clusters using favorable and unfavorable saliency maps, which visualize the class discriminating regions of an image. These human-interpretable maps complement radiologist knowledge to investigate the whole cluster at once. Besides, as part of this study, we evaluate a model based on VGG-19, which can identify COVID and pneumonia cases with a positive predictive value of 95% and 97%, respectively, comparable to the recent explainable approaches for COVID diagnosis.
Active Mining of Parallel Video Streams
May 14, 2014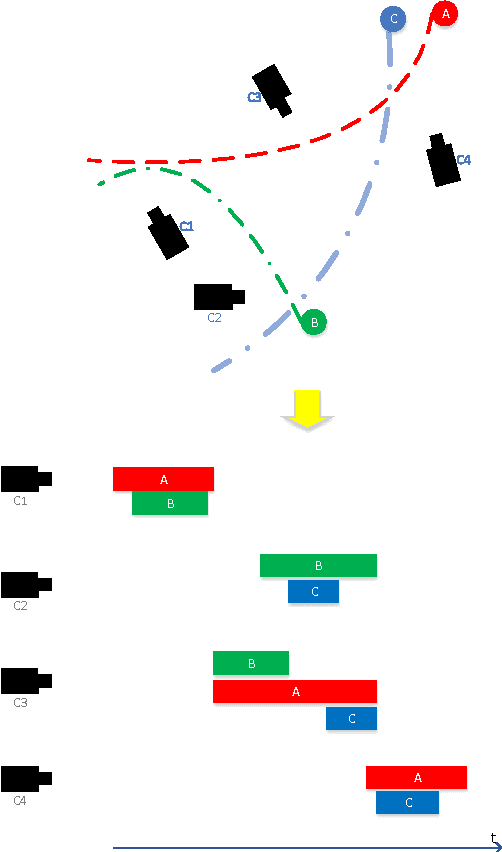

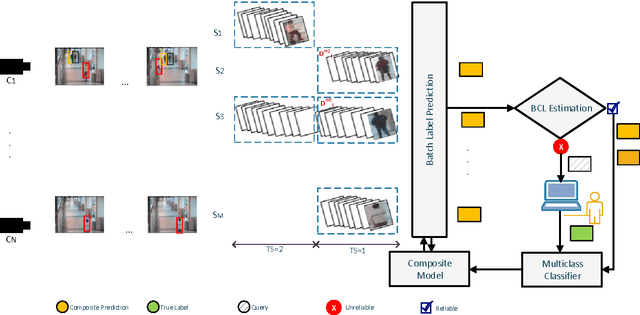

The practicality of a video surveillance system is adversely limited by the amount of queries that can be placed on human resources and their vigilance in response. To transcend this limitation, a major effort under way is to include software that (fully or at least semi) automatically mines video footage, reducing the burden imposed to the system. Herein, we propose a semi-supervised incremental learning framework for evolving visual streams in order to develop a robust and flexible track classification system. Our proposed method learns from consecutive batches by updating an ensemble in each time. It tries to strike a balance between performance of the system and amount of data which needs to be labelled. As no restriction is considered, the system can address many practical problems in an evolving multi-camera scenario, such as concept drift, class evolution and various length of video streams which have not been addressed before. Experiments were performed on synthetic as well as real-world visual data in non-stationary environments, showing high accuracy with fairly little human collaboration.