 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyNode-Driven Geometry Coding for Real-World Scanned Human Dynamic Mesh Compression
Jan 03, 2025The compression of real-world scanned 3D human dynamic meshes is an emerging research area, driven by applications such as telepresence, virtual reality, and 3D digital streaming. Unlike synthesized dynamic meshes with fixed topology, scanned dynamic meshes often not only have varying topology across frames but also scan defects such as holes and outliers, increasing the complexity of prediction and compression. Additionally, human meshes often combine rigid and non-rigid motions, making accurate prediction and encoding significantly more difficult compared to objects that exhibit purely rigid motion. To address these challenges, we propose a compression method designed for real-world scanned human dynamic meshes, leveraging embedded key nodes. The temporal motion of each vertex is formulated as a distance-weighted combination of transformations from neighboring key nodes, requiring the transmission of solely the key nodes' transformations. To enhance the quality of the KeyNode-driven prediction, we introduce an octree-based residual coding scheme and a Dual-direction prediction mode, which uses I-frames from both directions. Extensive experiments demonstrate that our method achieves significant improvements over the state-of-the-art, with an average bitrate saving of 24.51% across the evaluated sequences, particularly excelling at low bitrates.
Efficient Progressive Image Compression with Variance-aware Masking
Nov 15, 2024



Learned progressive image compression is gaining momentum as it allows improved image reconstruction as more bits are decoded at the receiver. We propose a progressive image compression method in which an image is first represented as a pair of base-quality and top-quality latent representations. Next, a residual latent representation is encoded as the element-wise difference between the top and base representations. Our scheme enables progressive image compression with element-wise granularity by introducing a masking system that ranks each element of the residual latent representation from most to least important, dividing it into complementary components, which can be transmitted separately to the decoder in order to obtain different reconstruction quality. The masking system does not add further parameters nor complexity. At the receiver, any elements of the top latent representation excluded from the transmitted components can be independently replaced with the mean predicted by the hyperprior architecture, ensuring reliable reconstructions at any intermediate quality level. We also introduced Rate Enhancement Modules (REMs), which refine the estimation of entropy parameters using already decoded components. We obtain results competitive with state-of-the-art competitors, while significantly reducing computational complexity, decoding time, and number of parameters.
Can We Remove the Ground? Obstacle-aware Point Cloud Compression for Remote Object Detection
Oct 01, 2024
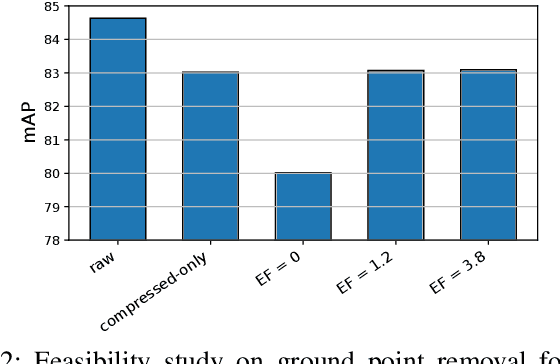
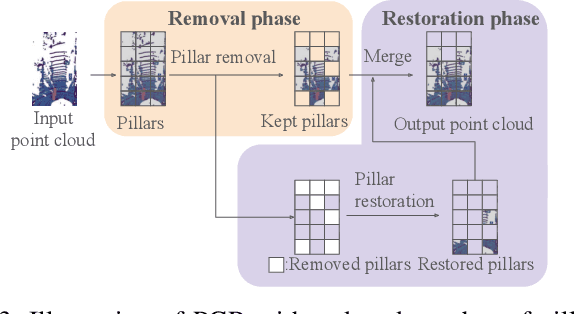
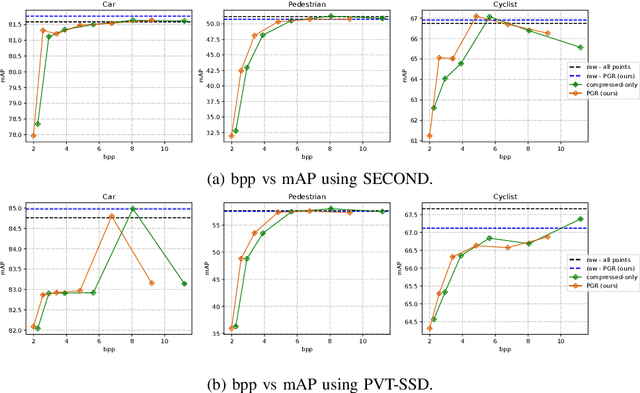
Efficient point cloud (PC) compression is crucial for streaming applications, such as augmented reality and cooperative perception. Classic PC compression techniques encode all the points in a frame. Tailoring compression towards perception tasks at the receiver side, we ask the question, "Can we remove the ground points during transmission without sacrificing the detection performance?" Our study reveals a strong dependency on the ground from state-of-the-art (SOTA) 3D object detection models, especially on those points below and around the object. In this work, we propose a lightweight obstacle-aware Pillar-based Ground Removal (PGR) algorithm. PGR filters out ground points that do not provide context to object recognition, significantly improving compression ratio without sacrificing the receiver side perception performance. Not using heavy object detection or semantic segmentation models, PGR is light-weight, highly parallelizable, and effective. Our evaluations on KITTI and Waymo Open Dataset show that SOTA detection models work equally well with PGR removing 20-30% of the points, with a speeding of 86 FPS.
A Neural Network Detector for Spectrum Sensing under Uncertainties
Aug 06, 2019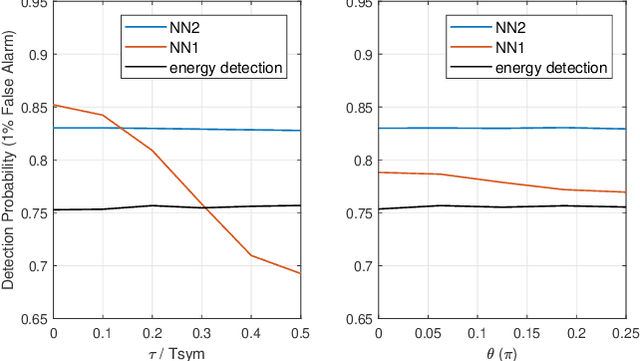
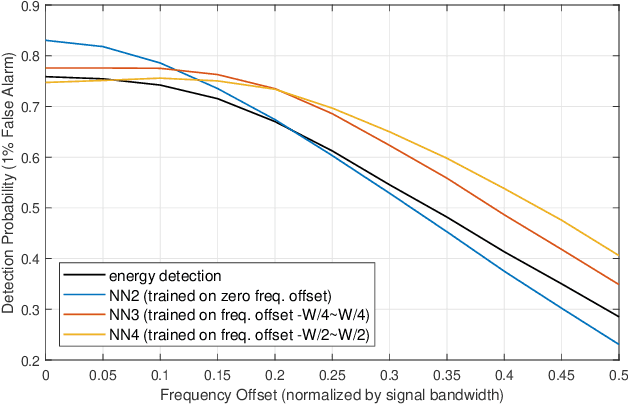
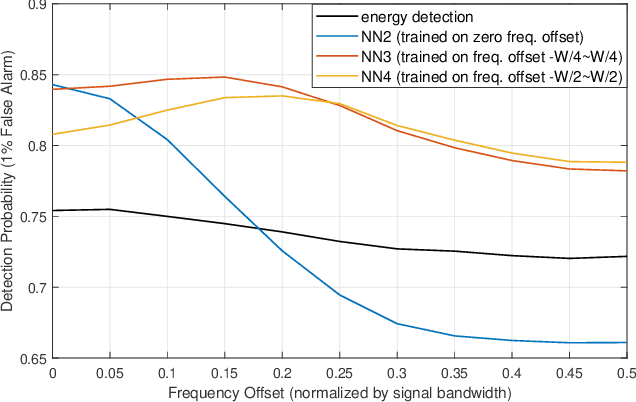
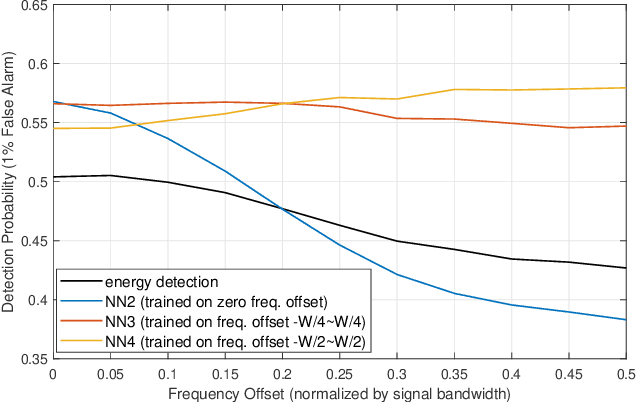
Spectrum sensing is of critical importance in any cognitive radio system. When the primary user's signal has uncertain parameters, the likelihood ratio test, which is the theoretically optimal detector, generally has no closed-form expression. As a result, spectrum sensing under parameter uncertainty remains an open question, though many detectors exploiting specific features of a primary signal have been proposed and have achieved reasonably good performance. In this paper, a neural network is trained as a detector for modulated signals. The result shows by training on an appropriate dataset, the neural network gains robustness under uncertainties in system parameters including the carrier frequency offset, carrier phase offset, and symbol time offset. The result displays the neural network's potential in exploiting implicit and incomplete knowledge about the signal's structure.
Comparison of Neural Network Architectures for Spectrum Sensing
Jul 15, 2019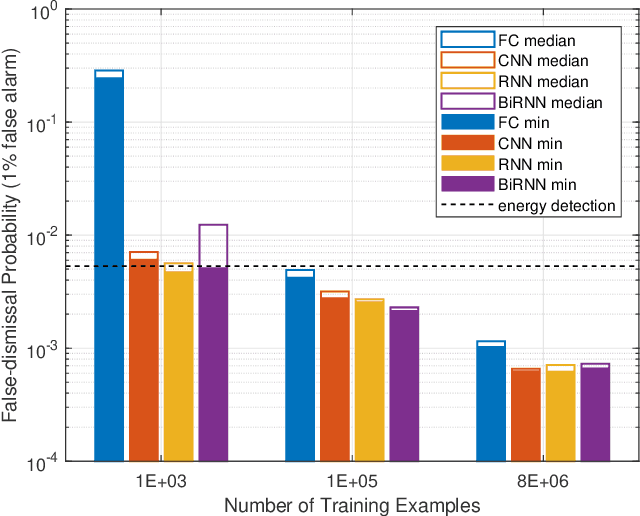
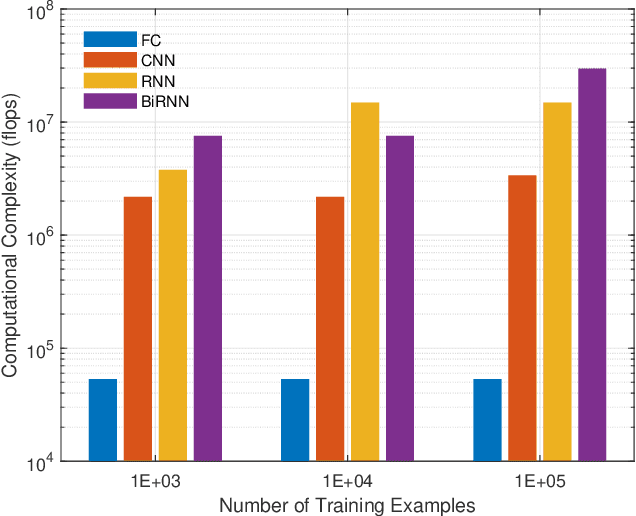
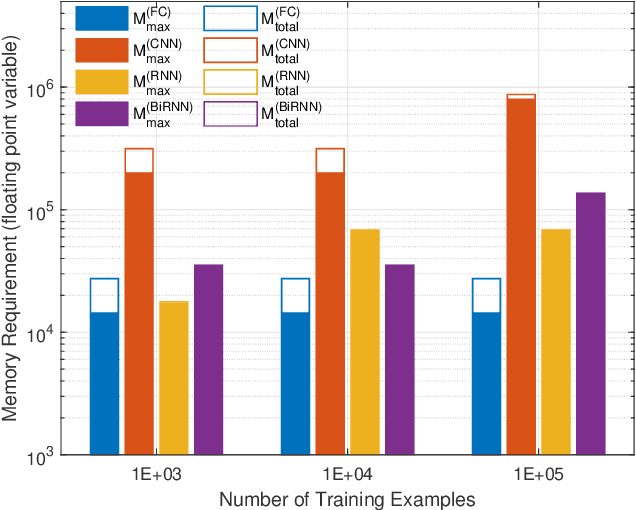
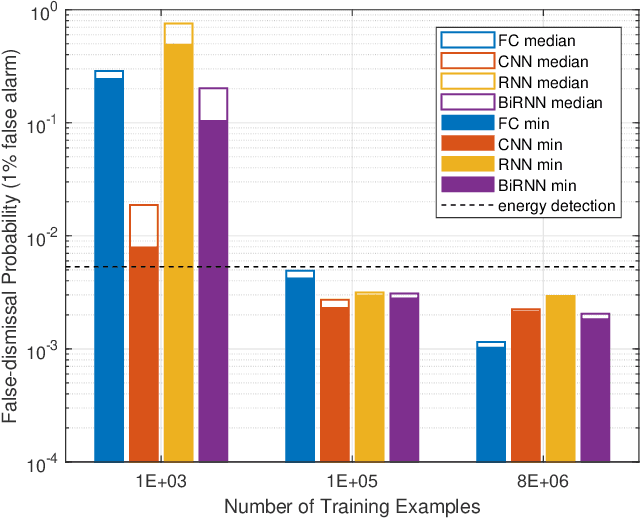
Different neural network (NN) architectures have different advantages. Convolutional neural networks (CNNs) achieved enormous success in computer vision, while recurrent neural networks (RNNs) gained popularity in speech recognition. It is not known which type of NN architecture is the best fit for classification of communication signals. In this work, we compare the behavior of fully-connected NN (FC), CNN, RNN, and bi-directional RNN (BiRNN) in a spectrum sensing task. The four NN architectures are compared on their detection performance, requirement of training data, computational complexity, and memory requirement. Given abundant training data and computational and memory resources, CNN, RNN, and BiRNN are shown to achieve similar performance. The performance of FC is worse than that of the other three types, except in the case where computational complexity is stringently limited.