 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMKB-RAG: A Multi-Modal Knowledge-Based Retrieval-Augmented Generation Framework
Apr 15, 2025Recent advancements in large language models (LLMs) and multi-modal LLMs have been remarkable. However, these models still rely solely on their parametric knowledge, which limits their ability to generate up-to-date information and increases the risk of producing erroneous content. Retrieval-Augmented Generation (RAG) partially mitigates these challenges by incorporating external data sources, yet the reliance on databases and retrieval systems can introduce irrelevant or inaccurate documents, ultimately undermining both performance and reasoning quality. In this paper, we propose Multi-Modal Knowledge-Based Retrieval-Augmented Generation (MMKB-RAG), a novel multi-modal RAG framework that leverages the inherent knowledge boundaries of models to dynamically generate semantic tags for the retrieval process. This strategy enables the joint filtering of retrieved documents, retaining only the most relevant and accurate references. Extensive experiments on knowledge-based visual question-answering tasks demonstrate the efficacy of our approach: on the E-VQA dataset, our method improves performance by +4.2% on the Single-Hop subset and +0.4% on the full dataset, while on the InfoSeek dataset, it achieves gains of +7.8% on the Unseen-Q subset, +8.2% on the Unseen-E subset, and +8.1% on the full dataset. These results highlight significant enhancements in both accuracy and robustness over the current state-of-the-art MLLM and RAG frameworks.
Restrained Generative Adversarial Network against Overfitting in Numeric Data Augmentation
Oct 26, 2020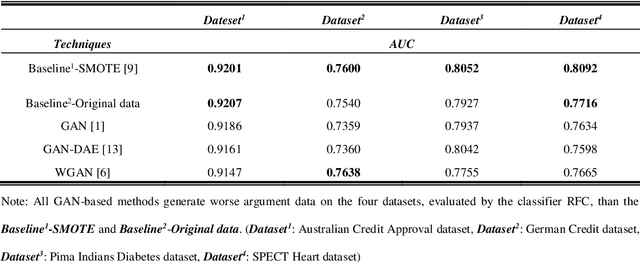
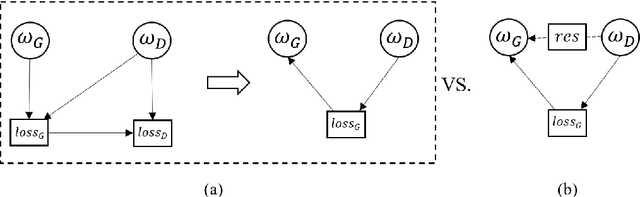
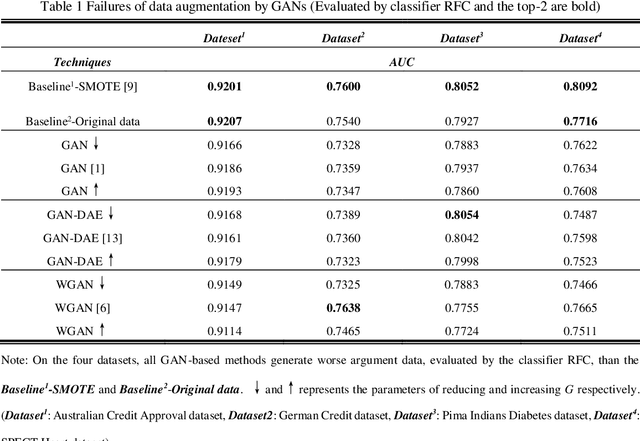

In recent studies, Generative Adversarial Network (GAN) is one of the popular schemes to augment the image dataset. However, in our study we find the generator G in the GAN fails to generate numerical data in lower-dimensional spaces, and we address overfitting in the generation. By analyzing the Directed Graphical Model (DGM), we propose a theoretical restraint, independence on the loss function, to suppress the overfitting. Practically, as the Statically Restrained GAN (SRGAN) and Dynamically Restrained GAN (DRGAN), two frameworks are proposed to employ the theoretical restraint to the network structure. In the static structure, we predefined a pair of particular network topologies of G and D as the restraint, and quantify such restraint by the interpretable metric Similarity of the Restraint (SR). While for DRGAN we design an adjustable dropout module for the restraint function. In the widely carried out 20 group experiments, on four public numerical class imbalance datasets and five classifiers, the static and dynamic methods together produce the best augmentation results of 19 from 20; and both two methods simultaneously generate 14 of 20 groups of the top-2 best, proving the effectiveness and feasibility of the theoretical restraints.