 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMKB-RAG: A Multi-Modal Knowledge-Based Retrieval-Augmented Generation Framework
Apr 15, 2025Recent advancements in large language models (LLMs) and multi-modal LLMs have been remarkable. However, these models still rely solely on their parametric knowledge, which limits their ability to generate up-to-date information and increases the risk of producing erroneous content. Retrieval-Augmented Generation (RAG) partially mitigates these challenges by incorporating external data sources, yet the reliance on databases and retrieval systems can introduce irrelevant or inaccurate documents, ultimately undermining both performance and reasoning quality. In this paper, we propose Multi-Modal Knowledge-Based Retrieval-Augmented Generation (MMKB-RAG), a novel multi-modal RAG framework that leverages the inherent knowledge boundaries of models to dynamically generate semantic tags for the retrieval process. This strategy enables the joint filtering of retrieved documents, retaining only the most relevant and accurate references. Extensive experiments on knowledge-based visual question-answering tasks demonstrate the efficacy of our approach: on the E-VQA dataset, our method improves performance by +4.2% on the Single-Hop subset and +0.4% on the full dataset, while on the InfoSeek dataset, it achieves gains of +7.8% on the Unseen-Q subset, +8.2% on the Unseen-E subset, and +8.1% on the full dataset. These results highlight significant enhancements in both accuracy and robustness over the current state-of-the-art MLLM and RAG frameworks.
Cross-Modality Attention with Semantic Graph Embedding for Multi-Label Classification
Dec 17, 2019


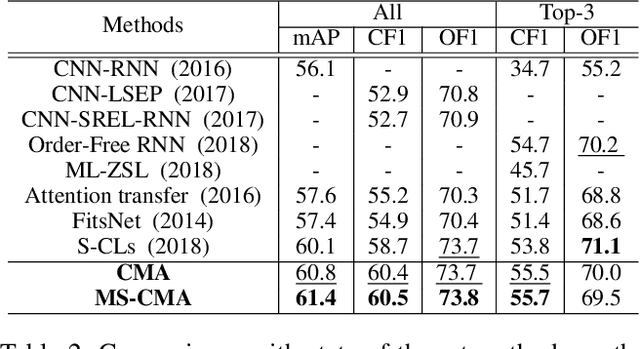
Multi-label image and video classification are fundamental yet challenging tasks in computer vision. The main challenges lie in capturing spatial or temporal dependencies between labels and discovering the locations of discriminative features for each class. In order to overcome these challenges, we propose to use cross-modality attention with semantic graph embedding for multi label classification. Based on the constructed label graph, we propose an adjacency-based similarity graph embedding method to learn semantic label embeddings, which explicitly exploit label relationships. Then our novel cross-modality attention maps are generated with the guidance of learned label embeddings. Experiments on two multi-label image classification datasets (MS-COCO and NUS-WIDE) show our method outperforms other existing state-of-the-arts. In addition, we validate our method on a large multi-label video classification dataset (YouTube-8M Segments) and the evaluation results demonstrate the generalization capability of our method.