 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Reinforcement Learning for Adaptive Mesh Refinement
Nov 04, 2022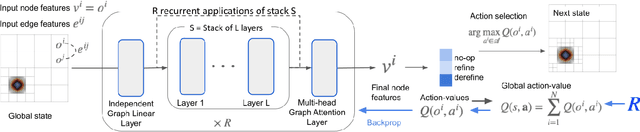
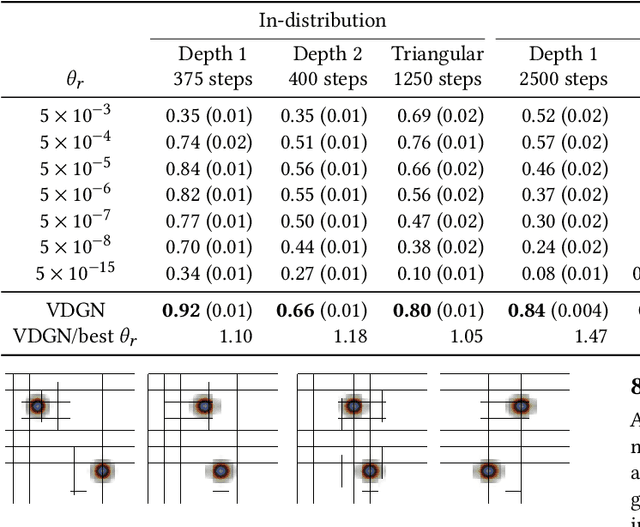
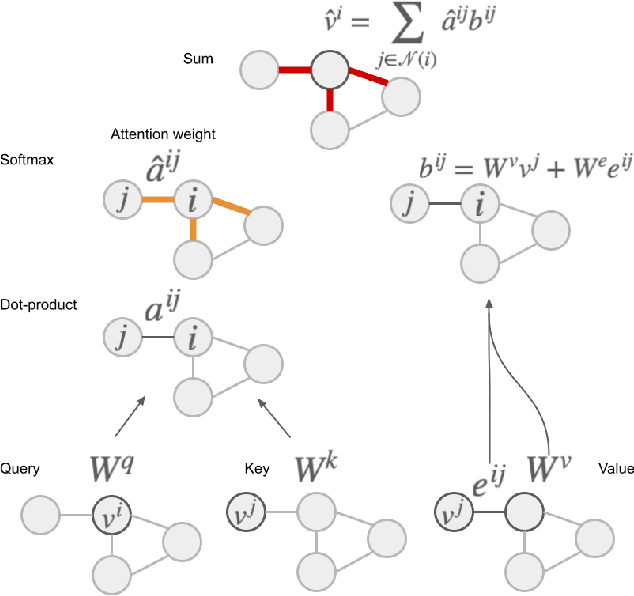
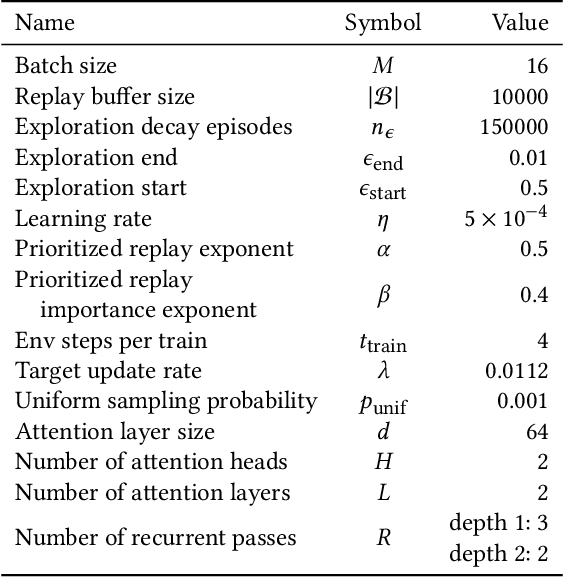
Adaptive mesh refinement (AMR) is necessary for efficient finite element simulations of complex physical phenomenon, as it allocates limited computational budget based on the need for higher or lower resolution, which varies over space and time. We present a novel formulation of AMR as a fully-cooperative Markov game, in which each element is an independent agent who makes refinement and de-refinement choices based on local information. We design a novel deep multi-agent reinforcement learning (MARL) algorithm called Value Decomposition Graph Network (VDGN), which solves the two core challenges that AMR poses for MARL: posthumous credit assignment due to agent creation and deletion, and unstructured observations due to the diversity of mesh geometries. For the first time, we show that MARL enables anticipatory refinement of regions that will encounter complex features at future times, thereby unlocking entirely new regions of the error-cost objective landscape that are inaccessible by traditional methods based on local error estimators. Comprehensive experiments show that VDGN policies significantly outperform error threshold-based policies in global error and cost metrics. We show that learned policies generalize to test problems with physical features, mesh geometries, and longer simulation times that were not seen in training. We also extend VDGN with multi-objective optimization capabilities to find the Pareto front of the tradeoff between cost and error.
Reinforcement Learning for Adaptive Mesh Refinement
Mar 01, 2021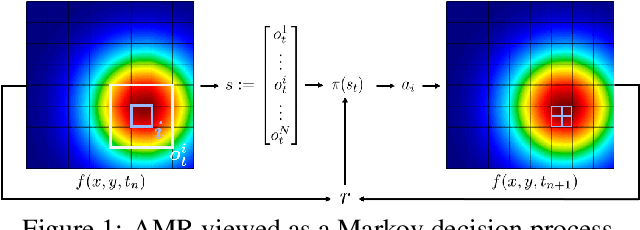
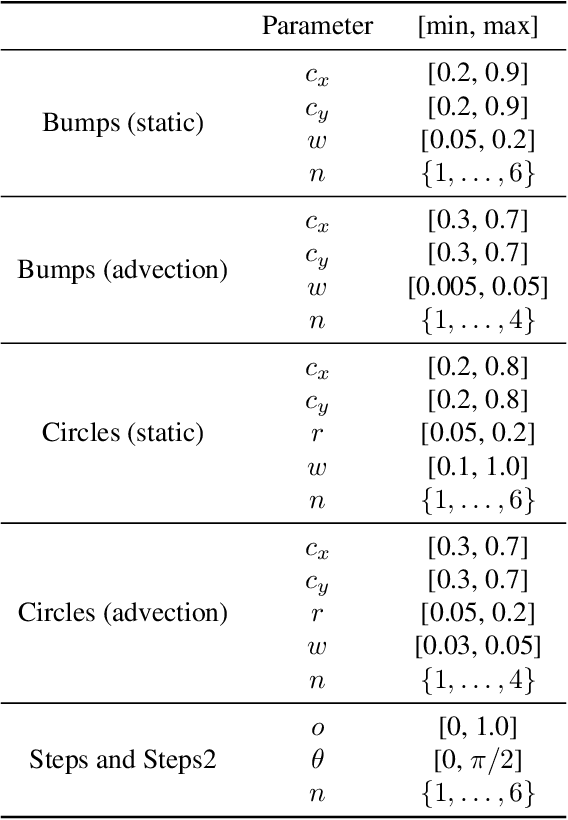
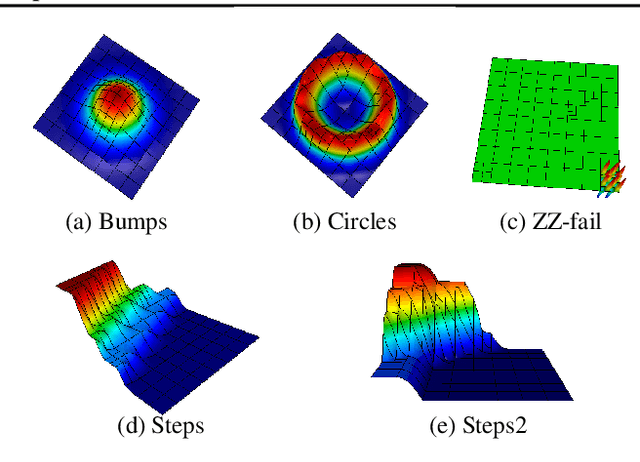

Large-scale finite element simulations of complex physical systems governed by partial differential equations crucially depend on adaptive mesh refinement (AMR) to allocate computational budget to regions where higher resolution is required. Existing scalable AMR methods make heuristic refinement decisions based on instantaneous error estimation and thus do not aim for long-term optimality over an entire simulation. We propose a novel formulation of AMR as a Markov decision process and apply deep reinforcement learning (RL) to train refinement policies directly from simulation. AMR poses a new problem for RL in that both the state dimension and available action set changes at every step, which we solve by proposing new policy architectures with differing generality and inductive bias. The model sizes of these policy architectures are independent of the mesh size and hence scale to arbitrarily large and complex simulations. We demonstrate in comprehensive experiments on static function estimation and the advection of different fields that RL policies can be competitive with a widely-used error estimator and generalize to larger, more complex, and unseen test problems.
Fourier Spectrum Discrepancies in Deep Network Generated Images
Nov 15, 2019

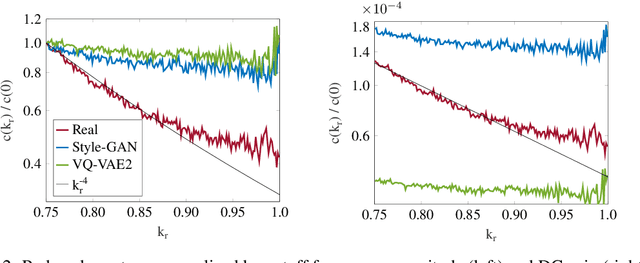
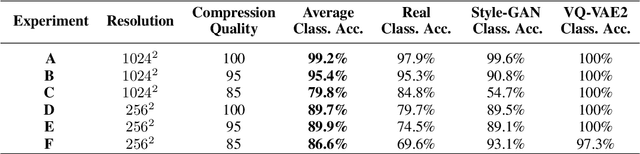
Advancements in deep generative models such as generative adversarial networks and variational autoencoders have resulted in the ability to generate realistic images that are visually indistinguishable from real images. In this paper, we present an analysis of the high-frequency Fourier modes of real and deep network generated images and the effects of resolution and image compression on these modes. Using this, we propose a detection method based on the frequency spectrum of the images which is able to achieve an accuracy of up to 99.2\% in classifying real, Style-GAN generated, and VQ-VAE2 generated images on a dataset of 2000 images with less than 10\% training data. Furthermore, we suggest a method for modifying the high-frequency attributes of deep network generated images to mimic real images.