 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Symbolic Translation of Language Models for Logical Reasoning
Jan 14, 2026The use of formal language for deductive logical reasoning aligns well with language models (LMs), where translating natural language (NL) into first-order logic (FOL) and employing an external solver results in a verifiable and therefore reliable reasoning system. However, smaller LMs often struggle with this translation task, frequently producing incorrect symbolic outputs due to formatting and translation errors. Existing approaches typically rely on self-iteration to correct these errors, but such methods depend heavily on the capabilities of the underlying model. To address this, we first categorize common errors and fine-tune smaller LMs using data synthesized by large language models. The evaluation is performed using the defined error categories. We introduce incremental inference, which divides inference into two stages, predicate generation and FOL translation, providing greater control over model behavior and enhancing generation quality as measured by predicate metrics. This decomposition framework also enables the use of a verification module that targets predicate-arity errors to further improve performance. Our study evaluates three families of models across four logical-reasoning datasets. The comprehensive fine-tuning, incremental inference, and verification modules reduce error rates, increase predicate coverage, and improve reasoning performance for smaller LMs, moving us closer to developing reliable and accessible symbolic-reasoning systems.
VerifiAgent: a Unified Verification Agent in Language Model Reasoning
Apr 01, 2025


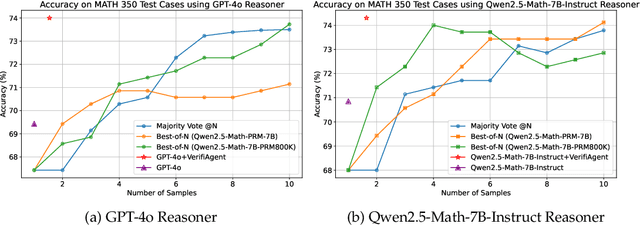
Large language models demonstrate remarkable reasoning capabilities but often produce unreliable or incorrect responses. Existing verification methods are typically model-specific or domain-restricted, requiring significant computational resources and lacking scalability across diverse reasoning tasks. To address these limitations, we propose VerifiAgent, a unified verification agent that integrates two levels of verification: meta-verification, which assesses completeness and consistency in model responses, and tool-based adaptive verification, where VerifiAgent autonomously selects appropriate verification tools based on the reasoning type, including mathematical, logical, or commonsense reasoning. This adaptive approach ensures both efficiency and robustness across different verification scenarios. Experimental results show that VerifiAgent outperforms baseline verification methods (e.g., deductive verifier, backward verifier) among all reasoning tasks. Additionally, it can further enhance reasoning accuracy by leveraging feedback from verification results. VerifiAgent can also be effectively applied to inference scaling, achieving better results with fewer generated samples and costs compared to existing process reward models in the mathematical reasoning domain. Code is available at https://github.com/Jiuzhouh/VerifiAgent
Methods for Legal Citation Prediction in the Age of LLMs: An Australian Law Case Study
Dec 09, 2024



In recent years, Large Language Models (LLMs) have shown great potential across a wide range of legal tasks. Despite these advances, mitigating hallucination remains a significant challenge, with state-of-the-art LLMs still frequently generating incorrect legal references. In this paper, we focus on the problem of legal citation prediction within the Australian law context, where correctly identifying and citing relevant legislations or precedents is critical. We compare several approaches: prompting general purpose and law-specialised LLMs, retrieval-only pipelines with both generic and domain-specific embeddings, task-specific instruction-tuning of LLMs, and hybrid strategies that combine LLMs with retrieval augmentation, query expansion, or voting ensembles. Our findings indicate that domain-specific pre-training alone is insufficient for achieving satisfactory citation accuracy even after law-specialised pre-training. In contrast, instruction tuning on our task-specific dataset dramatically boosts performance reaching the best results across all settings. We also highlight that database granularity along with the type of embeddings play a critical role in the performance of retrieval systems. Among retrieval-based approaches, hybrid methods consistently outperform retrieval-only setups, and among these, ensemble voting delivers the best result by combining the predictive quality of instruction-tuned LLMs with the retrieval system.
Agent S: An Open Agentic Framework that Uses Computers Like a Human
Oct 10, 2024



We present Agent S, an open agentic framework that enables autonomous interaction with computers through a Graphical User Interface (GUI), aimed at transforming human-computer interaction by automating complex, multi-step tasks. Agent S aims to address three key challenges in automating computer tasks: acquiring domain-specific knowledge, planning over long task horizons, and handling dynamic, non-uniform interfaces. To this end, Agent S introduces experience-augmented hierarchical planning, which learns from external knowledge search and internal experience retrieval at multiple levels, facilitating efficient task planning and subtask execution. In addition, it employs an Agent-Computer Interface (ACI) to better elicit the reasoning and control capabilities of GUI agents based on Multimodal Large Language Models (MLLMs). Evaluation on the OSWorld benchmark shows that Agent S outperforms the baseline by 9.37% on success rate (an 83.6% relative improvement) and achieves a new state-of-the-art. Comprehensive analysis highlights the effectiveness of individual components and provides insights for future improvements. Furthermore, Agent S demonstrates broad generalizability to different operating systems on a newly-released WindowsAgentArena benchmark. Code available at https://github.com/simular-ai/Agent-S.
Strategies for Improving NL-to-FOL Translation with LLMs: Data Generation, Incremental Fine-Tuning, and Verification
Sep 24, 2024Logical reasoning is a fundamental task in natural language processing that presents significant challenges to Large Language Models (LLMs). The inherent characteristics of logical reasoning makes it well-suited for symbolic representations such as first-order logic (FOL). Research in symbolic logical reasoning explored FOL generation using state-of-the-art LLMs (i.e., GPT-4) to produce FOL translations of natural language (NL) statements, but errors in translation are usually not the focus. We address this by categorizing the translation errors in FOL statements generated by LLMs. To make progress towards improving the quality of FOL translations for smaller language models such as LLaMA-2 13B and Mistral 7B, we create ProofFOL, a high-quality FOL-annotated subset of ProofWriter dataset using GPT-4o. The models fine-tuned on this silver standard data achieve a significant gain in performance when compared to larger language models such as LLaMA-2 70B. In addition to improving the model using large data, we also tackle the issue of data scarcity and introduce an incremental framework encompassing of data augmentation and verification steps. In the augmentation process, a single pair of (premises, conclusion) is split into multiple new instances based on the predicates and FOLs. This data is used for fine-tuning, and the inference on this model generates FOLs with fewer errors over the model trained on the original data. Our investigation on the translation errors leads to generation of a perturbation dataset, which is used to train a verifier that corrects potential syntactic and semantic FOL translation errors. We demonstrate an efficient method for making the most of a limited existing human-annotated dataset. Our results show state-of-the-art performance for ProofWriter and ProntoQA datasets using ProofFOL on LLaMA-2 and Mistral models.
Towards Uncertainty-Aware Language Agent
Feb 08, 2024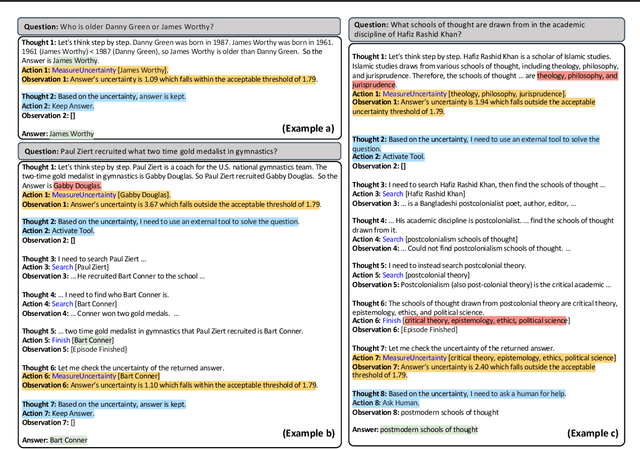

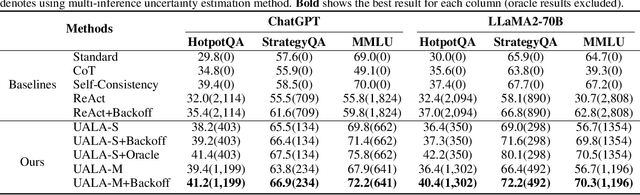
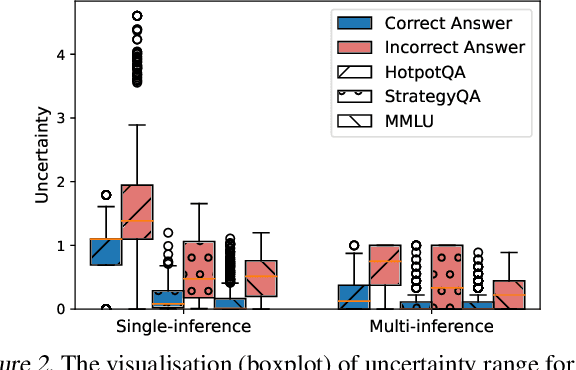
While Language Agents have achieved promising success by placing Large Language Models at the core of a more versatile design that dynamically interacts with the external world, the existing approaches neglect the notion of uncertainty during these interactions. We present the Uncertainty-Aware Language Agent (UALA), a framework that orchestrates the interaction between the agent and the external world using uncertainty quantification. Compared with other well-known counterparts like ReAct, our extensive experiments across 3 representative tasks (HotpotQA, StrategyQA, MMLU) and various LLM sizes demonstrate that UALA brings a significant improvement of performance, while having a substantially lower reliance on the external world (i.e., reduced number of tool calls and tokens). Our analyses provide various insights including the great potential of UALA compared with agent fine-tuning, and underscore the unreliability of verbalised confidence of LLMs as a proxy for uncertainty.
POSQA: Probe the World Models of LLMs with Size Comparisons
Oct 20, 2023



Embodied language comprehension emphasizes that language understanding is not solely a matter of mental processing in the brain but also involves interactions with the physical and social environment. With the explosive growth of Large Language Models (LLMs) and their already ubiquitous presence in our daily lives, it is becoming increasingly necessary to verify their real-world understanding. Inspired by cognitive theories, we propose POSQA: a Physical Object Size Question Answering dataset with simple size comparison questions to examine the extremity and analyze the potential mechanisms of the embodied comprehension of the latest LLMs. We show that even the largest LLMs today perform poorly under the zero-shot setting. We then push their limits with advanced prompting techniques and external knowledge augmentation. Furthermore, we investigate whether their real-world comprehension primarily derives from contextual information or internal weights and analyse the impact of prompt formats and report bias of different objects. Our results show that real-world understanding that LLMs shaped from textual data can be vulnerable to deception and confusion by the surface form of prompts, which makes it less aligned with human behaviours.
Reward Engineering for Generating Semi-structured Explanation
Sep 15, 2023


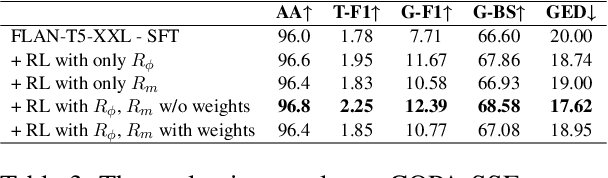
Semi-structured explanation depicts the implicit process of a reasoner with an explicit representation. This explanation highlights how available information in a specific query is supplemented with information a reasoner produces from its internal weights towards generating an answer. Despite the recent improvements in generative capabilities of language models, producing structured explanations to verify model's true reasoning capabilities remains a challenge. This issue is particularly pronounced for not-so-large LMs, as the reasoner is expected to couple a sequential answer with a structured explanation which embodies both the correct presentation and the correct reasoning process. In this work, we first underscore the limitations of supervised fine-tuning (SFT) in tackling this challenge, and then introduce a carefully crafted reward engineering method in reinforcement learning (RL) to better address this problem. We investigate multiple reward aggregation methods and provide a detailed discussion which sheds light on the promising potential of RL for future research. Our proposed reward on two semi-structured explanation generation benchmarks (ExplaGraph and COPA-SSE) achieves new state-of-the-art results.
PiVe: Prompting with Iterative Verification Improving Graph-based Generative Capability of LLMs
May 21, 2023Large language models (LLMs) have shown great abilities of solving various natural language tasks in different domains. Due to the training objective of LLMs and their pretraining data, LLMs are not very well equipped for tasks involving structured data generation. We propose a framework, Prompting with Iterative Verification (PiVe), to improve graphbased generative capability of LLMs. We show how a small language model could be trained to act as a verifier module for the output of an LLM (i.e., ChatGPT), and to iteratively improve its performance via fine-grained corrective instructions. Additionally, we show how the verifier module could apply iterative corrections offline for a more cost-effective solution to the text-to-graph generation task. Experiments on three graph-based datasets show consistent improvement gained via PiVe. Additionally, we highlight how the proposed verifier module can be used as a data augmentation tool to help improve the quality of automatically generated parallel text-graph datasets. Our code and data are available at https://github.com/Jiuzhouh/PiVe.
Self-supervised Graph Masking Pre-training for Graph-to-Text Generation
Oct 19, 2022
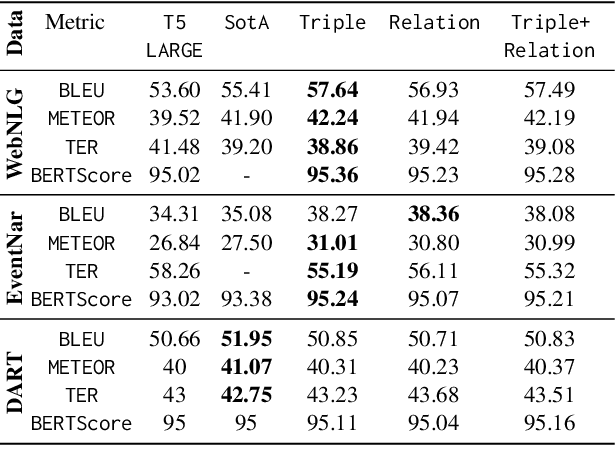
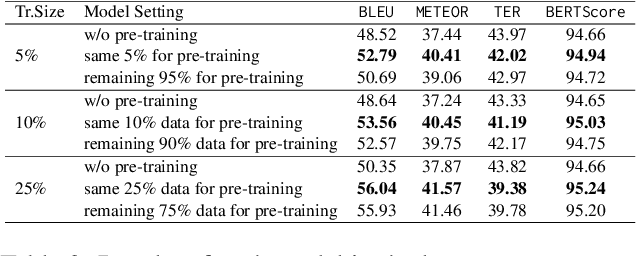
Large-scale pre-trained language models (PLMs) have advanced Graph-to-Text (G2T) generation by processing the linearised version of a graph. However, the linearisation is known to ignore the structural information. Additionally, PLMs are typically pre-trained on free text which introduces domain mismatch between pre-training and downstream G2T generation tasks. To address these shortcomings, we propose graph masking pre-training strategies that neither require supervision signals nor adjust the architecture of the underlying pre-trained encoder-decoder model. When used with a pre-trained T5, our approach achieves new state-of-the-art results on WebNLG+2020 and EventNarrative G2T generation datasets. Our method also shows to be very effective in the low-resource setting.