 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness In Sparse Autoencoders via Masked Regularization
Apr 07, 2026Sparse autoencoders (SAEs) are widely used in mechanistic interpretability to project LLM activations onto sparse latent spaces. However, sparsity alone is an imperfect proxy for interpretability, and current training objectives often result in brittle latent representations. SAEs are known to be prone to feature absorption, where general features are subsumed by more specific ones due to co-occurrence, degrading interpretability despite high reconstruction fidelity. Recent negative results on Out-of-Distribution (OOD) performance further underscore broader robustness related failures tied to under-specified training objectives. We address this by proposing a masking-based regularization that randomly replaces tokens during training to disrupt co-occurrence patterns. This improves robustness across SAE architectures and sparsity levels reducing absorption, enhancing probing performance, and narrowing the OOD gap. Our results point toward a practical path for more reliable interpretability tools.
VERIRAG: Healthcare Claim Verification via Statistical Audit in Retrieval-Augmented Generation
Jul 23, 2025Retrieval-augmented generation (RAG) systems are increasingly adopted in clinical decision support, yet they remain methodologically blind-they retrieve evidence but cannot vet its scientific quality. A paper claiming "Antioxidant proteins decreased after alloferon treatment" and a rigorous multi-laboratory replication study will be treated as equally credible, even if the former lacked scientific rigor or was even retracted. To address this challenge, we introduce VERIRAG, a framework that makes three notable contributions: (i) the Veritable, an 11-point checklist that evaluates each source for methodological rigor, including data integrity and statistical validity; (ii) a Hard-to-Vary (HV) Score, a quantitative aggregator that weights evidence by its quality and diversity; and (iii) a Dynamic Acceptance Threshold, which calibrates the required evidence based on how extraordinary a claim is. Across four datasets-comprising retracted, conflicting, comprehensive, and settled science corpora-the VERIRAG approach consistently outperforms all baselines, achieving absolute F1 scores ranging from 0.53 to 0.65, representing a 10 to 14 point improvement over the next-best method in each respective dataset. We will release all materials necessary for reproducing our results.
Leveraging Registers in Vision Transformers for Robust Adaptation
Jan 08, 2025


Vision Transformers (ViTs) have shown success across a variety of tasks due to their ability to capture global image representations. Recent studies have identified the existence of high-norm tokens in ViTs, which can interfere with unsupervised object discovery. To address this, the use of "registers" which are additional tokens that isolate high norm patch tokens while capturing global image-level information has been proposed. While registers have been studied extensively for object discovery, their generalization properties particularly in out-of-distribution (OOD) scenarios, remains underexplored. In this paper, we examine the utility of register token embeddings in providing additional features for improving generalization and anomaly rejection. To that end, we propose a simple method that combines the special CLS token embedding commonly employed in ViTs with the average-pooled register embeddings to create feature representations which are subsequently used for training a downstream classifier. We find that this enhances OOD generalization and anomaly rejection, while maintaining in-distribution (ID) performance. Extensive experiments across multiple ViT backbones trained with and without registers reveal consistent improvements of 2-4\% in top-1 OOD accuracy and a 2-3\% reduction in false positive rates for anomaly detection. Importantly, these gains are achieved without additional computational overhead.
On the Use of Anchoring for Training Vision Models
Jun 01, 2024



Anchoring is a recent, architecture-agnostic principle for training deep neural networks that has been shown to significantly improve uncertainty estimation, calibration, and extrapolation capabilities. In this paper, we systematically explore anchoring as a general protocol for training vision models, providing fundamental insights into its training and inference processes and their implications for generalization and safety. Despite its promise, we identify a critical problem in anchored training that can lead to an increased risk of learning undesirable shortcuts, thereby limiting its generalization capabilities. To address this, we introduce a new anchored training protocol that employs a simple regularizer to mitigate this issue and significantly enhances generalization. We empirically evaluate our proposed approach across datasets and architectures of varying scales and complexities, demonstrating substantial performance gains in generalization and safety metrics compared to the standard training protocol.
On-the-fly Object Detection using StyleGAN with CLIP Guidance
Oct 30, 2022We present a fully automated framework for building object detectors on satellite imagery without requiring any human annotation or intervention. We achieve this by leveraging the combined power of modern generative models (e.g., StyleGAN) and recent advances in multi-modal learning (e.g., CLIP). While deep generative models effectively encode the key semantics pertinent to a data distribution, this information is not immediately accessible for downstream tasks, such as object detection. In this work, we exploit CLIP's ability to associate image features with text descriptions to identify neurons in the generator network, which are subsequently used to build detectors on-the-fly.
Low Shot Learning with Untrained Neural Networks for Imaging Inverse Problems
Oct 23, 2019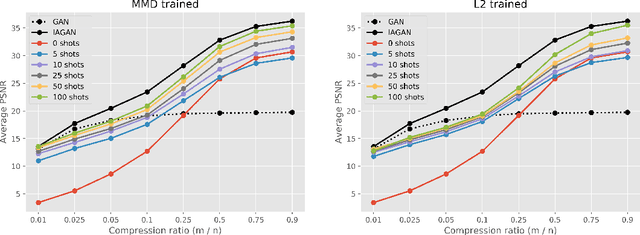

Employing deep neural networks as natural image priors to solve inverse problems either requires large amounts of data to sufficiently train expressive generative models or can succeed with no data via untrained neural networks. However, very few works have considered how to interpolate between these no- to high-data regimes. In particular, how can one use the availability of a small amount of data (even $5-25$ examples) to one's advantage in solving these inverse problems and can a system's performance increase as the amount of data increases as well? In this work, we consider solving linear inverse problems when given a small number of examples of images that are drawn from the same distribution as the image of interest. Comparing to untrained neural networks that use no data, we show how one can pre-train a neural network with a few given examples to improve reconstruction results in compressed sensing and semantic image recovery problems such as colorization. Our approach leads to improved reconstruction as the amount of available data increases and is on par with fully trained generative models, while requiring less than $1 \%$ of the data needed to train a generative model.
Remote Sensor Design for Visual Recognition with Convolutional Neural Networks
Jun 24, 2019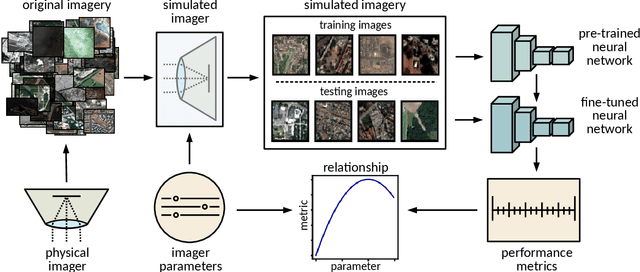

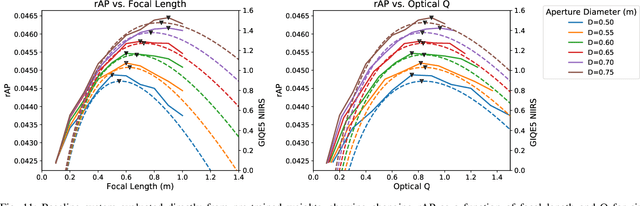
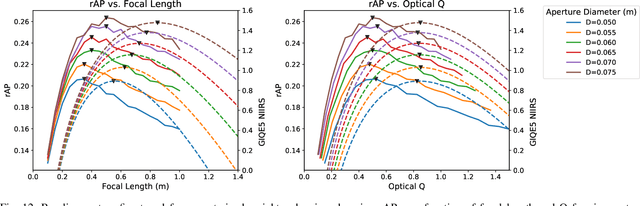
While deep learning technologies for computer vision have developed rapidly since 2012, modeling of remote sensing systems has remained focused around human vision. In particular, remote sensing systems are usually constructed to optimize sensing cost-quality trade-offs with respect to human image interpretability. While some recent studies have explored remote sensing system design as a function of simple computer vision algorithm performance, there has been little work relating this design to the state-of-the-art in computer vision: deep learning with convolutional neural networks. We develop experimental systems to conduct this analysis, showing results with modern deep learning algorithms and recent overhead image data. Our results are compared to standard image quality measurements based on human visual perception, and we conclude not only that machine and human interpretability differ significantly, but that computer vision performance is largely self-consistent across a range of disparate conditions. This research is presented as a cornerstone for a new generation of sensor design systems which focus on computer algorithm performance instead of human visual perception.