 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwap Path Network for Robust Person Search Pre-training
Dec 06, 2024



In person search, we detect and rank matches to a query person image within a set of gallery scenes. Most person search models make use of a feature extraction backbone, followed by separate heads for detection and re-identification. While pre-training methods for vision backbones are well-established, pre-training additional modules for the person search task has not been previously examined. In this work, we present the first framework for end-to-end person search pre-training. Our framework splits person search into object-centric and query-centric methodologies, and we show that the query-centric framing is robust to label noise, and trainable using only weakly-labeled person bounding boxes. Further, we provide a novel model dubbed Swap Path Net (SPNet) which implements both query-centric and object-centric training objectives, and can swap between the two while using the same weights. Using SPNet, we show that query-centric pre-training, followed by object-centric fine-tuning, achieves state-of-the-art results on the standard PRW and CUHK-SYSU person search benchmarks, with 96.4% mAP on CUHK-SYSU and 61.2% mAP on PRW. In addition, we show that our method is more effective, efficient, and robust for person search pre-training than recent backbone-only pre-training alternatives.
Gallery Filter Network for Person Search
Oct 25, 2022



In person search, we aim to localize a query person from one scene in other gallery scenes. The cost of this search operation is dependent on the number of gallery scenes, making it beneficial to reduce the pool of likely scenes. We describe and demonstrate the Gallery Filter Network (GFN), a novel module which can efficiently discard gallery scenes from the search process, and benefit scoring for persons detected in remaining scenes. We show that the GFN is robust under a range of different conditions by testing on different retrieval sets, including cross-camera, occluded, and low-resolution scenarios. In addition, we develop the base SeqNeXt person search model, which improves and simplifies the original SeqNet model. We show that the SeqNeXt+GFN combination yields significant performance gains over other state-of-the-art methods on the standard PRW and CUHK-SYSU person search datasets. To aid experimentation for this and other models, we provide standardized tooling for the data processing and evaluation pipeline typically used for person search research.
Remote Sensor Design for Visual Recognition with Convolutional Neural Networks
Jun 24, 2019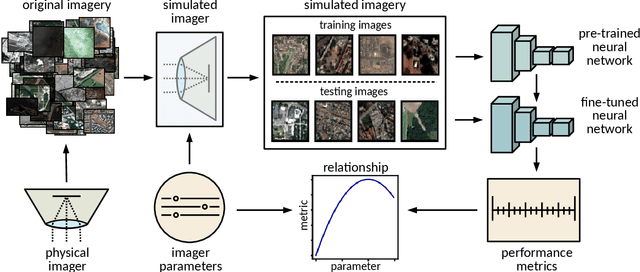

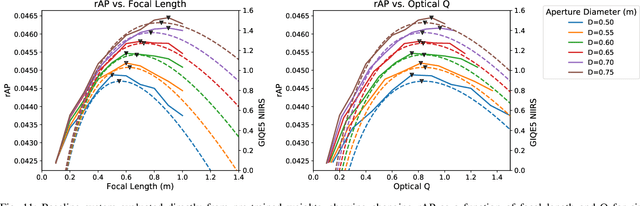
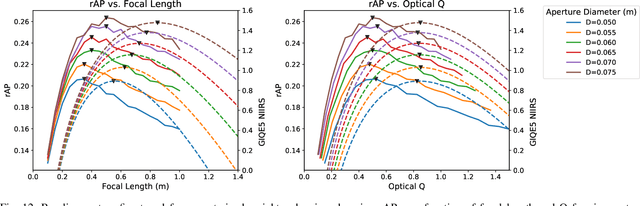
While deep learning technologies for computer vision have developed rapidly since 2012, modeling of remote sensing systems has remained focused around human vision. In particular, remote sensing systems are usually constructed to optimize sensing cost-quality trade-offs with respect to human image interpretability. While some recent studies have explored remote sensing system design as a function of simple computer vision algorithm performance, there has been little work relating this design to the state-of-the-art in computer vision: deep learning with convolutional neural networks. We develop experimental systems to conduct this analysis, showing results with modern deep learning algorithms and recent overhead image data. Our results are compared to standard image quality measurements based on human visual perception, and we conclude not only that machine and human interpretability differ significantly, but that computer vision performance is largely self-consistent across a range of disparate conditions. This research is presented as a cornerstone for a new generation of sensor design systems which focus on computer algorithm performance instead of human visual perception.