 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Registers in Vision Transformers for Robust Adaptation
Jan 08, 2025


Vision Transformers (ViTs) have shown success across a variety of tasks due to their ability to capture global image representations. Recent studies have identified the existence of high-norm tokens in ViTs, which can interfere with unsupervised object discovery. To address this, the use of "registers" which are additional tokens that isolate high norm patch tokens while capturing global image-level information has been proposed. While registers have been studied extensively for object discovery, their generalization properties particularly in out-of-distribution (OOD) scenarios, remains underexplored. In this paper, we examine the utility of register token embeddings in providing additional features for improving generalization and anomaly rejection. To that end, we propose a simple method that combines the special CLS token embedding commonly employed in ViTs with the average-pooled register embeddings to create feature representations which are subsequently used for training a downstream classifier. We find that this enhances OOD generalization and anomaly rejection, while maintaining in-distribution (ID) performance. Extensive experiments across multiple ViT backbones trained with and without registers reveal consistent improvements of 2-4\% in top-1 OOD accuracy and a 2-3\% reduction in false positive rates for anomaly detection. Importantly, these gains are achieved without additional computational overhead.
On the Use of Anchoring for Training Vision Models
Jun 01, 2024



Anchoring is a recent, architecture-agnostic principle for training deep neural networks that has been shown to significantly improve uncertainty estimation, calibration, and extrapolation capabilities. In this paper, we systematically explore anchoring as a general protocol for training vision models, providing fundamental insights into its training and inference processes and their implications for generalization and safety. Despite its promise, we identify a critical problem in anchored training that can lead to an increased risk of learning undesirable shortcuts, thereby limiting its generalization capabilities. To address this, we introduce a new anchored training protocol that employs a simple regularizer to mitigate this issue and significantly enhances generalization. We empirically evaluate our proposed approach across datasets and architectures of varying scales and complexities, demonstrating substantial performance gains in generalization and safety metrics compared to the standard training protocol.
Revisiting Inlier and Outlier Specification for Improved Out-of-Distribution Detection
Jul 12, 2022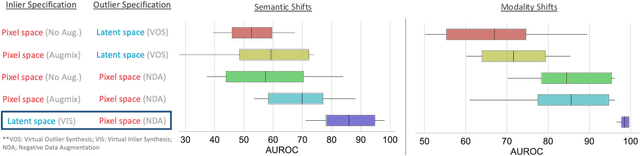
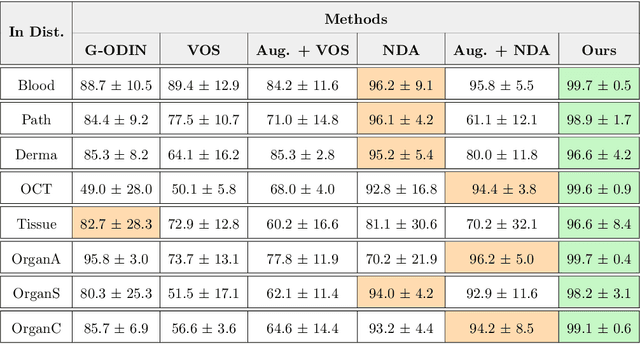
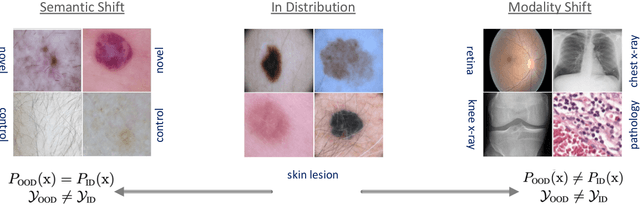
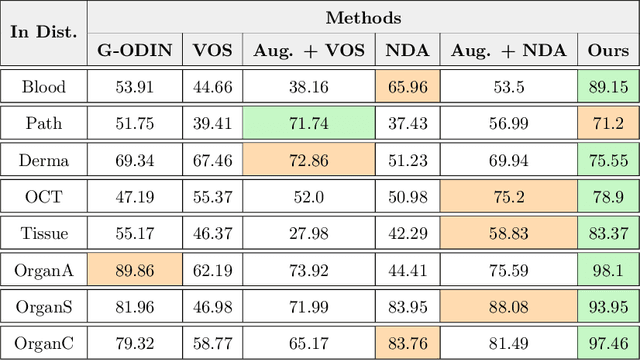
Accurately detecting out-of-distribution (OOD) data with varying levels of semantic and covariate shifts with respect to the in-distribution (ID) data is critical for deployment of safe and reliable models. This is particularly the case when dealing with highly consequential applications (e.g. medical imaging, self-driving cars, etc). The goal is to design a detector that can accept meaningful variations of the ID data, while also rejecting examples from OOD regimes. In practice, this dual objective can be realized by enforcing consistency using an appropriate scoring function (e.g., energy) and calibrating the detector to reject a curated set of OOD data (referred to as outlier exposure or shortly OE). While OE methods are widely adopted, assembling representative OOD datasets is both costly and challenging due to the unpredictability of real-world scenarios, hence the recent trend of designing OE-free detectors. In this paper, we make a surprising finding that controlled generalization to ID variations and exposure to diverse (synthetic) outlier examples are essential to simultaneously improving semantic and modality shift detection. In contrast to existing methods, our approach samples inliers in the latent space, and constructs outlier examples via negative data augmentation. Through a rigorous empirical study on medical imaging benchmarks (MedMNIST, ISIC2019 and NCT), we demonstrate significant performance gains ($15\% - 35\%$ in AUROC) over existing OE-free, OOD detection approaches under both semantic and modality shifts.