 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Inlier and Outlier Specification for Improved Out-of-Distribution Detection
Paper and Code
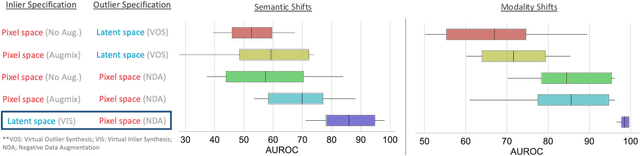
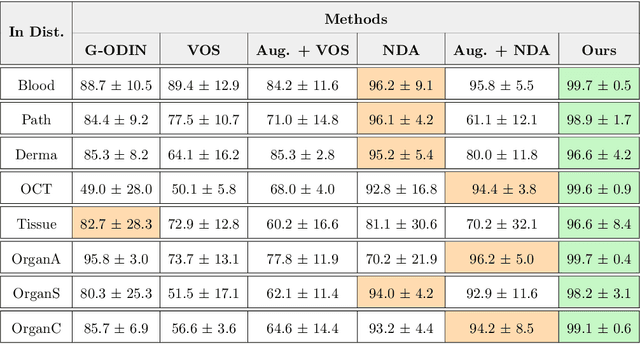
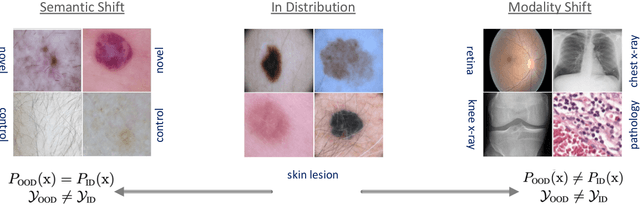
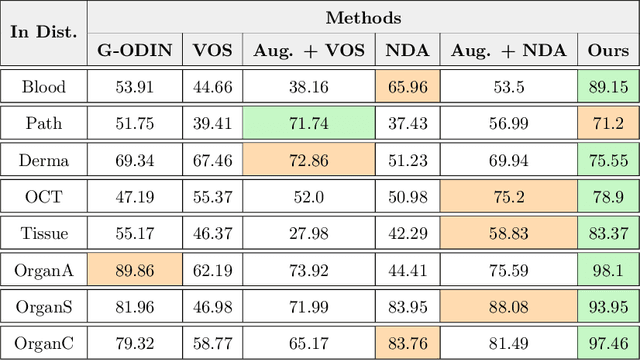
Accurately detecting out-of-distribution (OOD) data with varying levels of semantic and covariate shifts with respect to the in-distribution (ID) data is critical for deployment of safe and reliable models. This is particularly the case when dealing with highly consequential applications (e.g. medical imaging, self-driving cars, etc). The goal is to design a detector that can accept meaningful variations of the ID data, while also rejecting examples from OOD regimes. In practice, this dual objective can be realized by enforcing consistency using an appropriate scoring function (e.g., energy) and calibrating the detector to reject a curated set of OOD data (referred to as outlier exposure or shortly OE). While OE methods are widely adopted, assembling representative OOD datasets is both costly and challenging due to the unpredictability of real-world scenarios, hence the recent trend of designing OE-free detectors. In this paper, we make a surprising finding that controlled generalization to ID variations and exposure to diverse (synthetic) outlier examples are essential to simultaneously improving semantic and modality shift detection. In contrast to existing methods, our approach samples inliers in the latent space, and constructs outlier examples via negative data augmentation. Through a rigorous empirical study on medical imaging benchmarks (MedMNIST, ISIC2019 and NCT), we demonstrate significant performance gains ($15\% - 35\%$ in AUROC) over existing OE-free, OOD detection approaches under both semantic and modality shifts.