 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-wise Linearization of Neural Network for Model Interpretation
Oct 25, 2023Neural network have achieved remarkable successes in many scientific fields. However, the interpretability of the neural network model is still a major bottlenecks to deploy such technique into our daily life. The challenge can dive into the non-linear behavior of the neural network, which rises a critical question that how a model use input feature to make a decision. The classical approach to address this challenge is feature attribution, which assigns an important score to each input feature and reveal its importance of current prediction. However, current feature attribution approaches often indicate the importance of each input feature without detail of how they are actually processed by a model internally. These attribution approaches often raise a concern that whether they highlight correct features for a model prediction. For a neural network model, the non-linear behavior is often caused by non-linear activation units of a model. However, the computation behavior of a prediction from a neural network model is locally linear, because one prediction has only one activation pattern. Base on the observation, we propose an instance-wise linearization approach to reformulates the forward computation process of a neural network prediction. This approach reformulates different layers of convolution neural networks into linear matrix multiplication. Aggregating all layers' computation, a prediction complex convolution neural network operations can be described as a linear matrix multiplication $F(x) = W \cdot x + b$. This equation can not only provides a feature attribution map that highlights the important of the input features but also tells how each input feature contributes to a prediction exactly. Furthermore, we discuss the application of this technique in both supervise classification and unsupervised neural network learning parametric t-SNE dimension reduction.
"Understanding Robustness Lottery": A Comparative Visual Analysis of Neural Network Pruning Approaches
Jun 16, 2022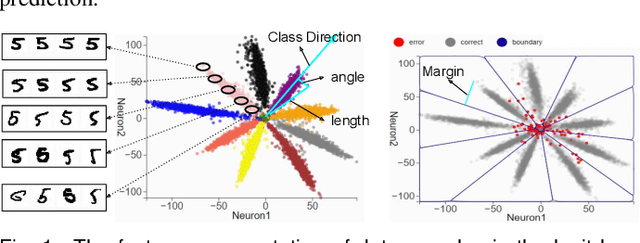

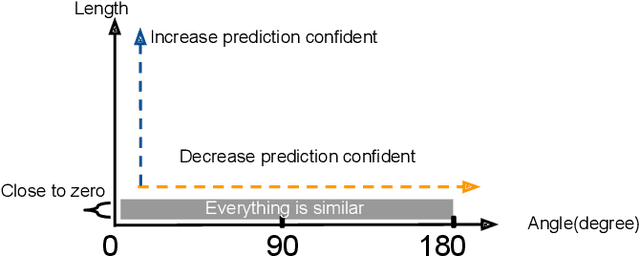
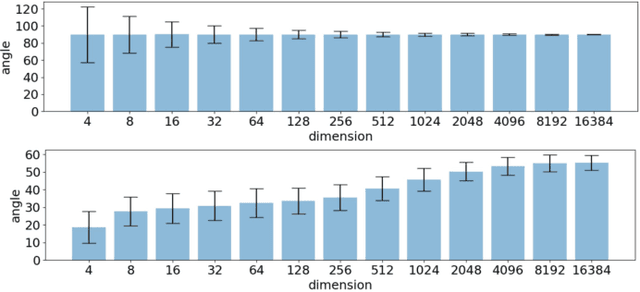
Deep learning approaches have provided state-of-the-art performance in many applications by relying on extremely large and heavily overparameterized neural networks. However, such networks have been shown to be very brittle, not generalize well to new uses cases, and are often difficult if not impossible to deploy on resources limited platforms. Model pruning, i.e., reducing the size of the network, is a widely adopted strategy that can lead to more robust and generalizable network -- usually orders of magnitude smaller with the same or even improved performance. While there exist many heuristics for model pruning, our understanding of the pruning process remains limited. Empirical studies show that some heuristics improve performance while others can make models more brittle or have other side effects. This work aims to shed light on how different pruning methods alter the network's internal feature representation, and the corresponding impact on model performance. To provide a meaningful comparison and characterization of model feature space, we use three geometric metrics that are decomposed from the common adopted classification loss. With these metrics, we design a visualization system to highlight the impact of pruning on model prediction as well as the latent feature embedding. The proposed tool provides an environment for exploring and studying differences among pruning methods and between pruned and original model. By leveraging our visualization, the ML researchers can not only identify samples that are fragile to model pruning and data corruption but also obtain insights and explanations on how some pruned models achieve superior robustness performance.