 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation-Centric Paradigm for Scientific Visualization Agents
Sep 18, 2025
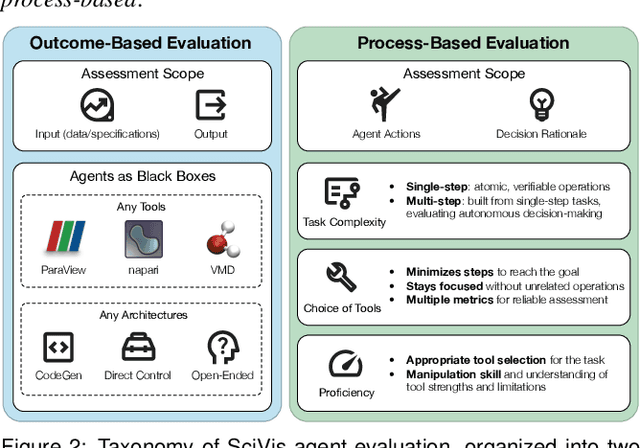
Recent advances in multi-modal large language models (MLLMs) have enabled increasingly sophisticated autonomous visualization agents capable of translating user intentions into data visualizations. However, measuring progress and comparing different agents remains challenging, particularly in scientific visualization (SciVis), due to the absence of comprehensive, large-scale benchmarks for evaluating real-world capabilities. This position paper examines the various types of evaluation required for SciVis agents, outlines the associated challenges, provides a simple proof-of-concept evaluation example, and discusses how evaluation benchmarks can facilitate agent self-improvement. We advocate for a broader collaboration to develop a SciVis agentic evaluation benchmark that would not only assess existing capabilities but also drive innovation and stimulate future development in the field.
ParaView-MCP: An Autonomous Visualization Agent with Direct Tool Use
May 11, 2025While powerful and well-established, tools like ParaView present a steep learning curve that discourages many potential users. This work introduces ParaView-MCP, an autonomous agent that integrates modern multimodal large language models (MLLMs) with ParaView to not only lower the barrier to entry but also augment ParaView with intelligent decision support. By leveraging the state-of-the-art reasoning, command execution, and vision capabilities of MLLMs, ParaView-MCP enables users to interact with ParaView through natural language and visual inputs. Specifically, our system adopted the Model Context Protocol (MCP) - a standardized interface for model-application communication - that facilitates direct interaction between MLLMs with ParaView's Python API to allow seamless information exchange between the user, the language model, and the visualization tool itself. Furthermore, by implementing a visual feedback mechanism that allows the agent to observe the viewport, we unlock a range of new capabilities, including recreating visualizations from examples, closed-loop visualization parameter updates based on user-defined goals, and even cross-application collaboration involving multiple tools. Broadly, we believe such an agent-driven visualization paradigm can profoundly change the way we interact with visualization tools. We expect a significant uptake in the development of such visualization tools, in both visualization research and industry.
See or Recall: A Sanity Check for the Role of Vision in Solving Visualization Question Answer Tasks with Multimodal LLMs
Apr 14, 2025Recent developments in multimodal large language models (MLLM) have equipped language models to reason about vision and language jointly. This permits MLLMs to both perceive and answer questions about data visualization across a variety of designs and tasks. Applying MLLMs to a broad range of visualization tasks requires us to properly evaluate their capabilities, and the most common way to conduct evaluation is through measuring a model's visualization reasoning capability, analogous to how we would evaluate human understanding of visualizations (e.g., visualization literacy). However, we found that in the context of visualization question answering (VisQA), how an MLLM perceives and reasons about visualizations can be fundamentally different from how humans approach the same problem. During the evaluation, even without visualization, the model could correctly answer a substantial portion of the visualization test questions, regardless of whether any selection options were provided. We hypothesize that the vast amount of knowledge encoded in the language model permits factual recall that supersedes the need to seek information from the visual signal. It raises concerns that the current VisQA evaluation may not fully capture the models' visualization reasoning capabilities. To address this, we propose a comprehensive sanity check framework that integrates a rule-based decision tree and a sanity check table to disentangle the effects of "seeing" (visual processing) and "recall" (reliance on prior knowledge). This validates VisQA datasets for evaluation, highlighting where models are truly "seeing", positively or negatively affected by the factual recall, or relying on inductive biases for question answering. Our study underscores the need for careful consideration in designing future visualization understanding studies when utilizing MLLMs.
AVA: Towards Autonomous Visualization Agents through Visual Perception-Driven Decision-Making
Dec 07, 2023With recent advances in multi-modal foundation models, the previously text-only large language models (LLM) have evolved to incorporate visual input, opening up unprecedented opportunities for various applications in visualization. Our work explores the utilization of the visual perception ability of multi-modal LLMs to develop Autonomous Visualization Agents (AVAs) that can interpret and accomplish user-defined visualization objectives through natural language. We propose the first framework for the design of AVAs and present several usage scenarios intended to demonstrate the general applicability of the proposed paradigm. The addition of visual perception allows AVAs to act as the virtual visualization assistant for domain experts who may lack the knowledge or expertise in fine-tuning visualization outputs. Our preliminary exploration and proof-of-concept agents suggest that this approach can be widely applicable whenever the choices of appropriate visualization parameters require the interpretation of previous visual output. Feedback from unstructured interviews with experts in AI research, medical visualization, and radiology has been incorporated, highlighting the practicality and potential of AVAs. Our study indicates that AVAs represent a general paradigm for designing intelligent visualization systems that can achieve high-level visualization goals, which pave the way for developing expert-level visualization agents in the future.