 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous-Time Video Generation via Learning Motion Dynamics with Neural ODE
Paper and Code
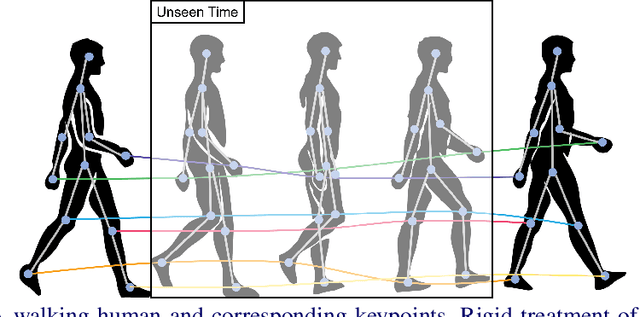
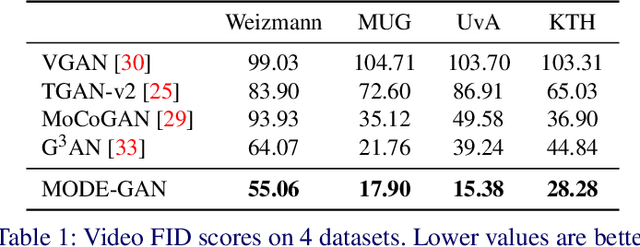
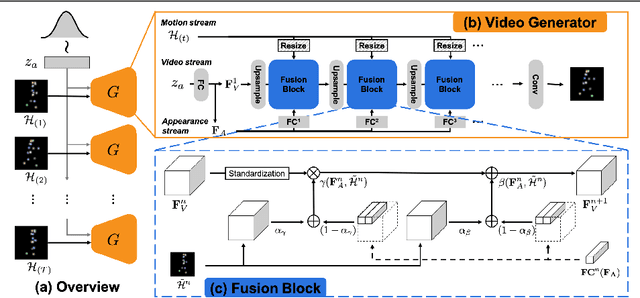

In order to perform unconditional video generation, we must learn the distribution of the real-world videos. In an effort to synthesize high-quality videos, various studies attempted to learn a mapping function between noise and videos, including recent efforts to separate motion distribution and appearance distribution. Previous methods, however, learn motion dynamics in discretized, fixed-interval timesteps, which is contrary to the continuous nature of motion of a physical body. In this paper, we propose a novel video generation approach that learns separate distributions for motion and appearance, the former modeled by neural ODE to learn natural motion dynamics. Specifically, we employ a two-stage approach where the first stage converts a noise vector to a sequence of keypoints in arbitrary frame rates, and the second stage synthesizes videos based on the given keypoints sequence and the appearance noise vector. Our model not only quantitatively outperforms recent baselines for video generation, but also demonstrates versatile functionality such as dynamic frame rate manipulation and motion transfer between two datasets, thus opening new doors to diverse video generation applications.