 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenMSD: Towards Multilingual Scientific Documents Similarity Measurement
Paper and Code
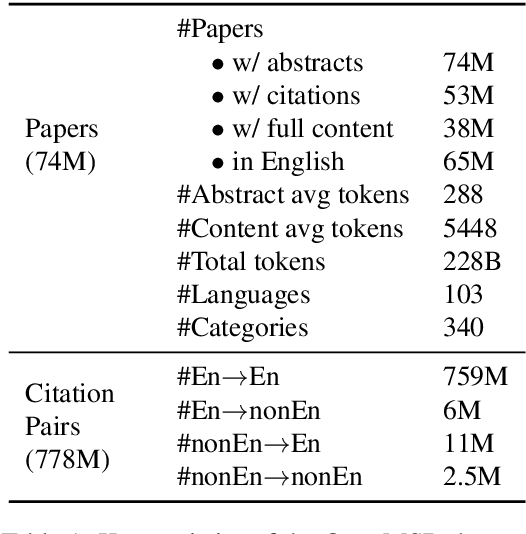
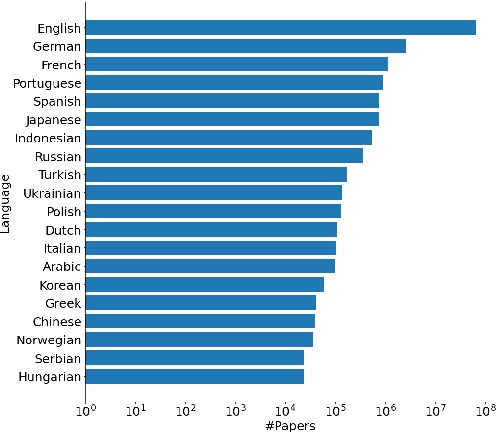
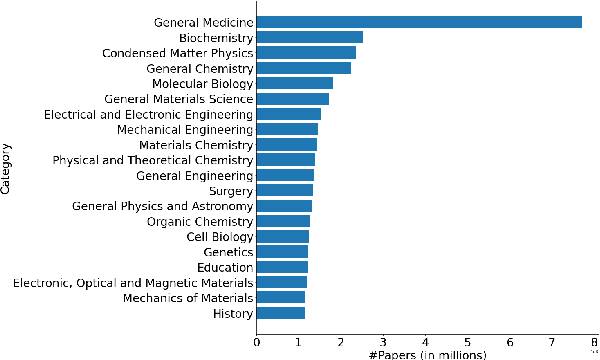
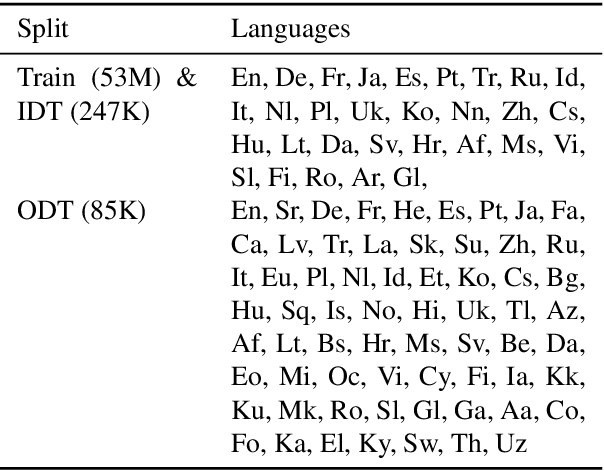
We develop and evaluate multilingual scientific documents similarity measurement models in this work. Such models can be used to find related works in different languages, which can help multilingual researchers find and explore papers more efficiently. We propose the first multilingual scientific documents dataset, Open-access Multilingual Scientific Documents (OpenMSD), which has 74M papers in 103 languages and 778M citation pairs. With OpenMSD, we pretrain science-specialized language models, and explore different strategies to derive "related" paper pairs to fine-tune the models, including using a mixture of citation, co-citation, and bibliographic-coupling pairs. To further improve the models' performance for non-English papers, we explore the use of generative language models to enrich the non-English papers with English summaries. This allows us to leverage the models' English capabilities to create better representations for non-English papers. Our best model significantly outperforms strong baselines by 7-16% (in mean average precision).