 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomized Search Length: Beyond User Models
Jan 05, 2022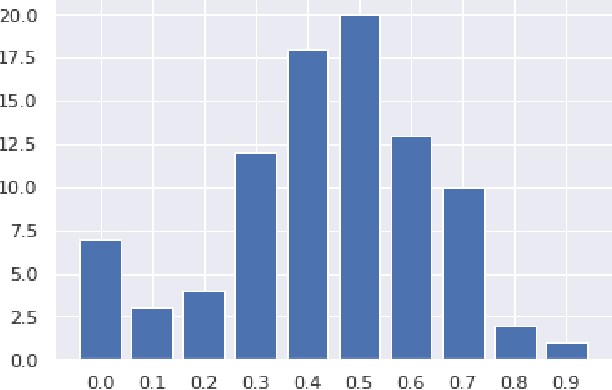
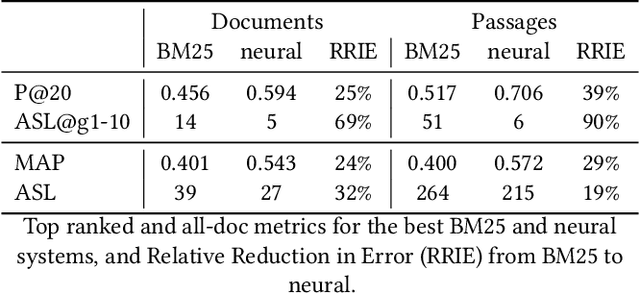
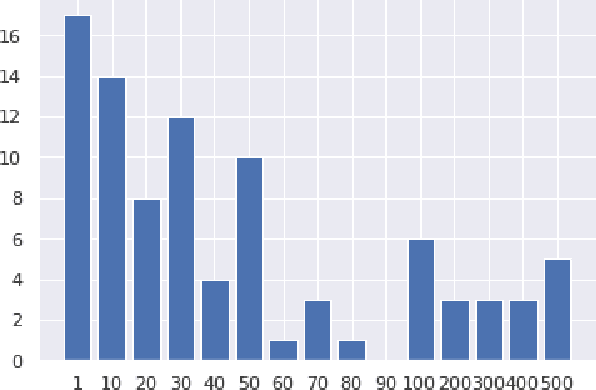
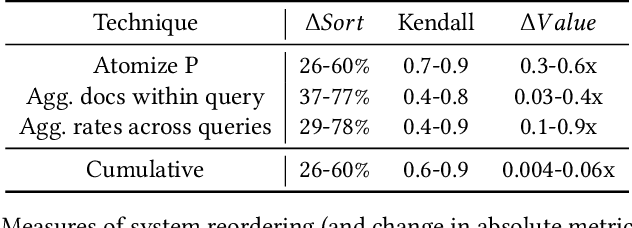
We argue that current IR metrics, modeled on optimizing user experience, measure too narrow a portion of the IR space. If IR systems are weak, these metrics undersample or completely filter out the deeper documents that need improvement. If IR systems are relatively strong, these metrics undersample deeper relevant documents that could underpin even stronger IR systems, ones that could present content from tens or hundreds of relevant documents in a user-digestible hierarchy or text summary. We reanalyze over 70 TREC tracks from the past 28 years, showing that roughly half undersample top ranked documents and nearly all undersample tail documents. We show that in the 2020 Deep Learning tracks, neural systems were actually near-optimal at top-ranked documents, compared to only modest gains over BM25 on tail documents. Our analysis is based on a simple new systems-oriented metric, 'atomized search length', which is capable of accurately and evenly measuring all relevant documents at any depth.
Learning To Split and Rephrase From Wikipedia Edit History
Aug 28, 2018

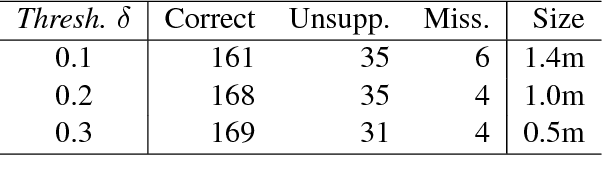

Split and rephrase is the task of breaking down a sentence into shorter ones that together convey the same meaning. We extract a rich new dataset for this task by mining Wikipedia's edit history: WikiSplit contains one million naturally occurring sentence rewrites, providing sixty times more distinct split examples and a ninety times larger vocabulary than the WebSplit corpus introduced by Narayan et al. (2017) as a benchmark for this task. Incorporating WikiSplit as training data produces a model with qualitatively better predictions that score 32 BLEU points above the prior best result on the WebSplit benchmark.