 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling the Unigram Distribution
Paper and Code
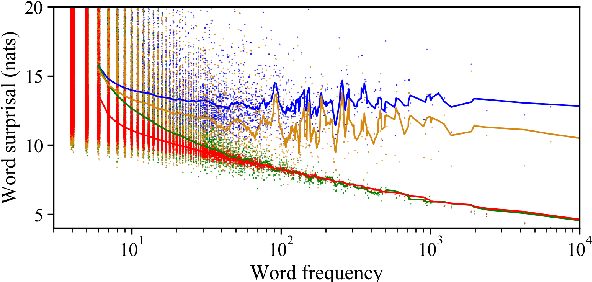
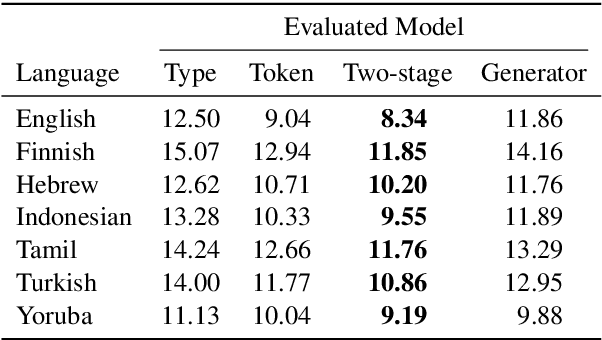

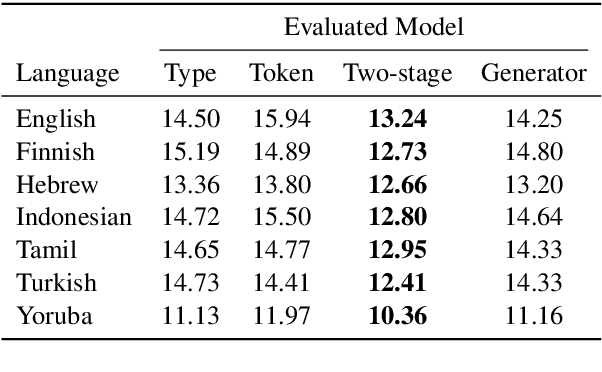
The unigram distribution is the non-contextual probability of finding a specific word form in a corpus. While of central importance to the study of language, it is commonly approximated by each word's sample frequency in the corpus. This approach, being highly dependent on sample size, assigns zero probability to any out-of-vocabulary (oov) word form. As a result, it produces negatively biased probabilities for any oov word form, while positively biased probabilities to in-corpus words. In this work, we argue in favor of properly modeling the unigram distribution -- claiming it should be a central task in natural language processing. With this in mind, we present a novel model for estimating it in a language (a neuralization of Goldwater et al.'s (2011) model) and show it produces much better estimates across a diverse set of 7 languages than the na\"ive use of neural character-level language models.