 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Escaping Saddle Points for Non-Convex Policy Optimization
Paper and Code
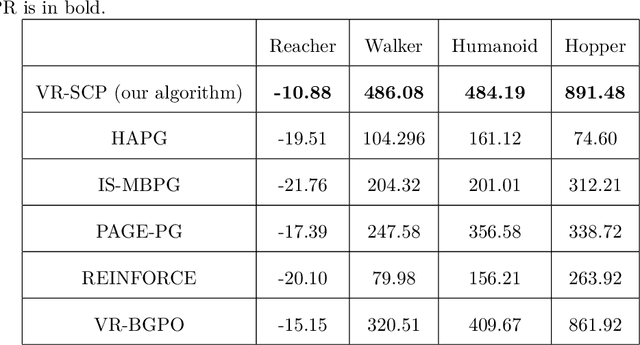
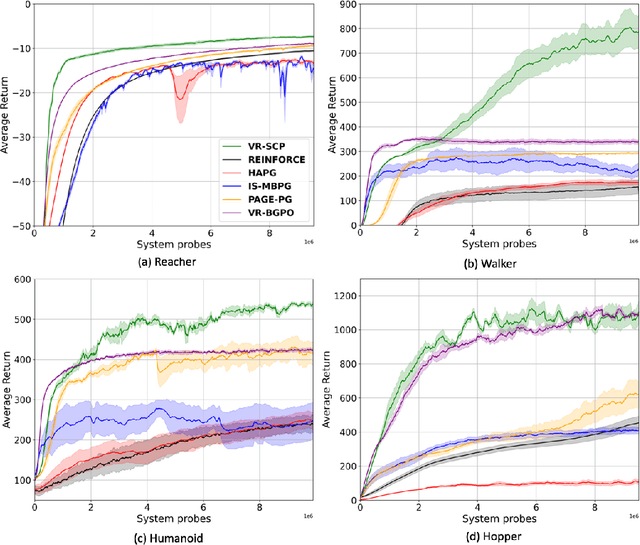
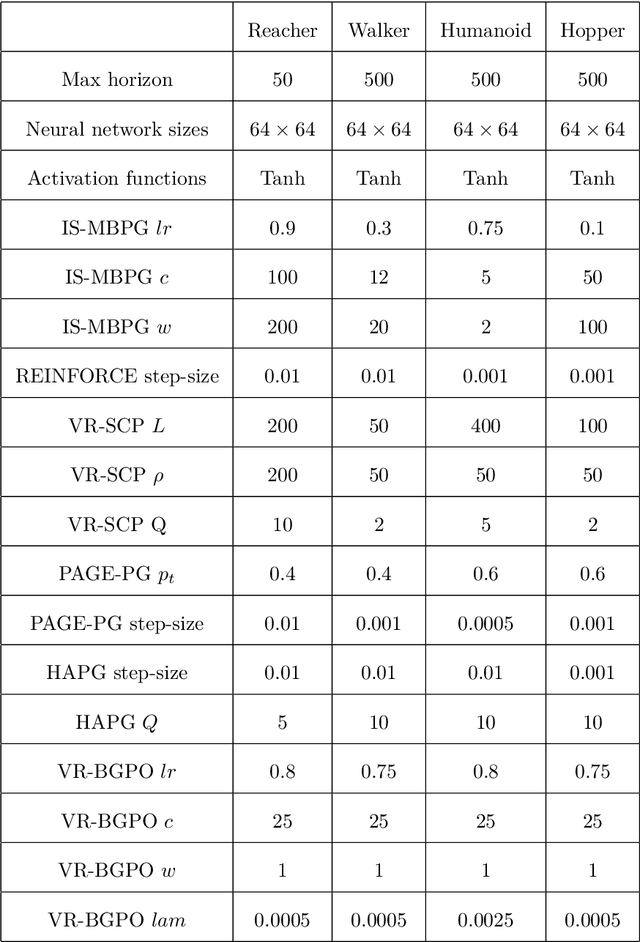
Policy gradient (PG) is widely used in reinforcement learning due to its scalability and good performance. In recent years, several variance-reduced PG methods have been proposed with a theoretical guarantee of converging to an approximate first-order stationary point (FOSP) with the sample complexity of $O(\epsilon^{-3})$. However, FOSPs could be bad local optima or saddle points. Moreover, these algorithms often use importance sampling (IS) weights which could impair the statistical effectiveness of variance reduction. In this paper, we propose a variance-reduced second-order method that uses second-order information in the form of Hessian vector products (HVP) and converges to an approximate second-order stationary point (SOSP) with sample complexity of $\tilde{O}(\epsilon^{-3})$. This rate improves the best-known sample complexity for achieving approximate SOSPs by a factor of $O(\epsilon^{-0.5})$. Moreover, the proposed variance reduction technique bypasses IS weights by using HVP terms. Our experimental results show that the proposed algorithm outperforms the state of the art and is more robust to changes in random seeds.