 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Interactive Search with a Scale-Free Comparison Oracle
Jun 02, 2023A comparison-based search algorithm lets a user find a target item $t$ in a database by answering queries of the form, ``Which of items $i$ and $j$ is closer to $t$?'' Instead of formulating an explicit query (such as one or several keywords), the user navigates towards the target via a sequence of such (typically noisy) queries. We propose a scale-free probabilistic oracle model called $\gamma$-CKL for such similarity triplets $(i,j;t)$, which generalizes the CKL triplet model proposed in the literature. The generalization affords independent control over the discriminating power of the oracle and the dimension of the feature space containing the items. We develop a search algorithm with provably exponential rate of convergence under the $\gamma$-CKL oracle, thanks to a backtracking strategy that deals with the unavoidable errors in updating the belief region around the target. We evaluate the performance of the algorithm both over the posited oracle and over several real-world triplet datasets. We also report on a comprehensive user study, where human subjects navigate a database of face portraits.
Learning to Search Efficiently Using Comparisons
May 13, 2019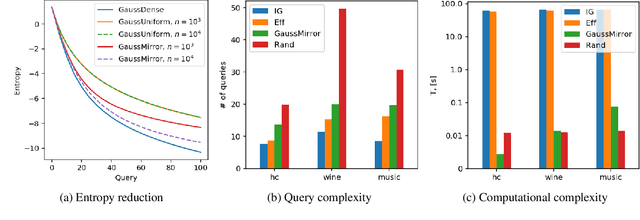
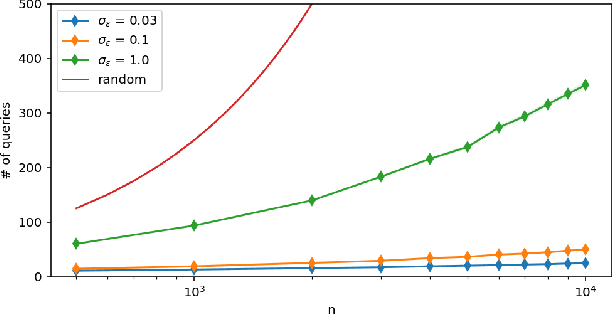
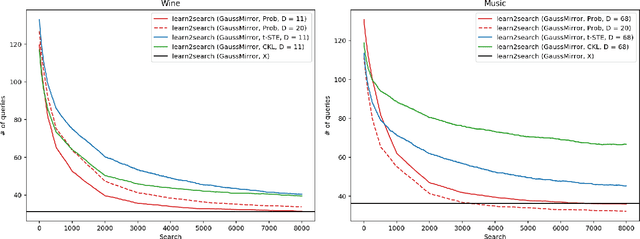
We consider the problem of searching in a set of items by using pairwise comparisons. We aim to locate a target item $t$ by asking an oracle questions of the form "Which item from the pair $(i,j)$ is more similar to t?". We assume a blind setting, where no item features are available to guide the search process; only the oracle sees the features in order to generate an answer. Previous approaches for this problem either assume noiseless answers, or they scale poorly in the number of items, both of which preclude practical applications. In this paper, we present a new scalable learning framework called learn2search that performs efficient comparison-based search on a set of items despite the presence of noise in the answers. Items live in a space of latent features, and we posit a probabilistic model for the oracle comparing two items $i$ and $j$ with respect to a target $t$. Our algorithm maintains its own representation of the space of items, which it learns incrementally based on past searches. We evaluate the performance of learn2search on both synthetic and real-world data, and show that it learns to search more and more efficiently, over time matching the performance of a scheme with access to the item features.