 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroth-Order Stackelberg Control in Combinatorial Congestion Games
Feb 26, 2026We study Stackelberg (leader--follower) tuning of network parameters (tolls, capacities, incentives) in combinatorial congestion games, where selfish users choose discrete routes (or other combinatorial strategies) and settle at a congestion equilibrium. The leader minimizes a system-level objective (e.g., total travel time) evaluated at equilibrium, but this objective is typically nonsmooth because the set of used strategies can change abruptly. We propose ZO-Stackelberg, which couples a projection-free Frank--Wolfe equilibrium solver with a zeroth-order outer update, avoiding differentiation through equilibria. We prove convergence to generalized Goldstein stationary points of the true equilibrium objective, with explicit dependence on the equilibrium approximation error, and analyze subsampled oracles: if an exact minimizer is sampled with probability $κ_m$, then the Frank--Wolfe error decays as $\mathcal{O}(1/(κ_m T))$. We also propose stratified sampling as a practical way to avoid a vanishing $κ_m$ when the strategies that matter most for the Wardrop equilibrium concentrate in a few dominant combinatorial classes (e.g., short paths). Experiments on real-world networks demonstrate that our method achieves orders-of-magnitude speedups over a differentiation-based baseline while converging to follower equilibria.
Learn to Vaccinate: Combining Structure Learning and Effective Vaccination for Epidemic and Outbreak Control
Jun 18, 2025



The Susceptible-Infected-Susceptible (SIS) model is a widely used model for the spread of information and infectious diseases, particularly non-immunizing ones, on a graph. Given a highly contagious disease, a natural question is how to best vaccinate individuals to minimize the disease's extinction time. While previous works showed that the problem of optimal vaccination is closely linked to the NP-hard Spectral Radius Minimization (SRM) problem, they assumed that the graph is known, which is often not the case in practice. In this work, we consider the problem of minimizing the extinction time of an outbreak modeled by an SIS model where the graph on which the disease spreads is unknown and only the infection states of the vertices are observed. To this end, we split the problem into two: learning the graph and determining effective vaccination strategies. We propose a novel inclusion-exclusion-based learning algorithm and, unlike previous approaches, establish its sample complexity for graph recovery. We then detail an optimal algorithm for the SRM problem and prove that its running time is polynomial in the number of vertices for graphs with bounded treewidth. This is complemented by an efficient and effective polynomial-time greedy heuristic for any graph. Finally, we present experiments on synthetic and real-world data that numerically validate our learning and vaccination algorithms.
Fast Proxy Experiment Design for Causal Effect Identification
Jul 07, 2024Identifying causal effects is a key problem of interest across many disciplines. The two long-standing approaches to estimate causal effects are observational and experimental (randomized) studies. Observational studies can suffer from unmeasured confounding, which may render the causal effects unidentifiable. On the other hand, direct experiments on the target variable may be too costly or even infeasible to conduct. A middle ground between these two approaches is to estimate the causal effect of interest through proxy experiments, which are conducted on variables with a lower cost to intervene on compared to the main target. Akbari et al. [2022] studied this setting and demonstrated that the problem of designing the optimal (minimum-cost) experiment for causal effect identification is NP-complete and provided a naive algorithm that may require solving exponentially many NP-hard problems as a sub-routine in the worst case. In this work, we provide a few reformulations of the problem that allow for designing significantly more efficient algorithms to solve it as witnessed by our extensive simulations. Additionally, we study the closely-related problem of designing experiments that enable us to identify a given effect through valid adjustments sets.
Recursive Causal Discovery
Mar 14, 2024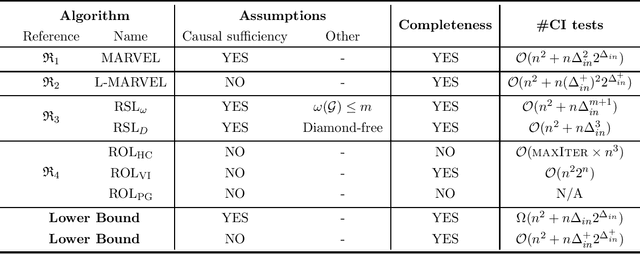
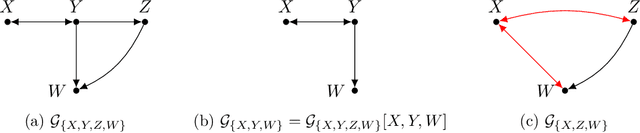
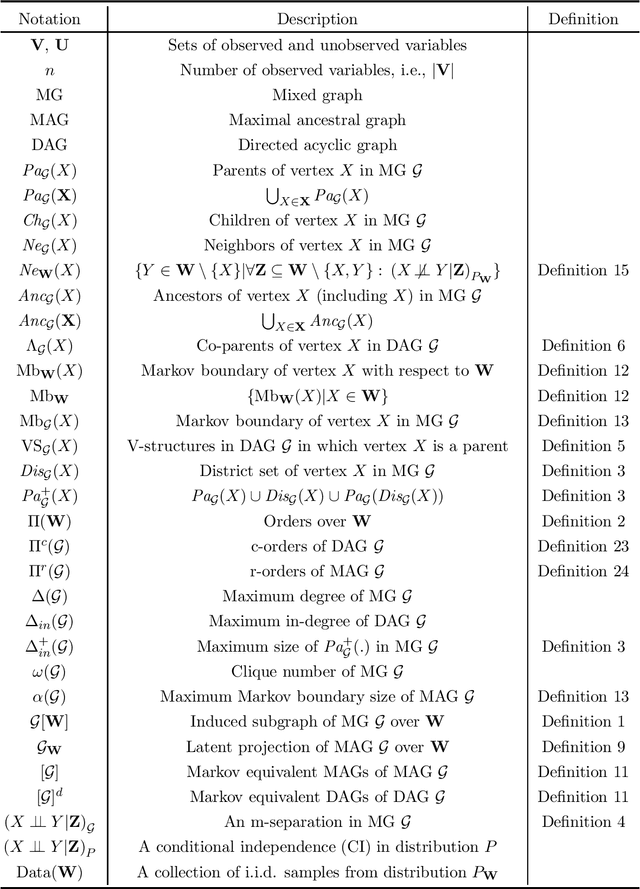
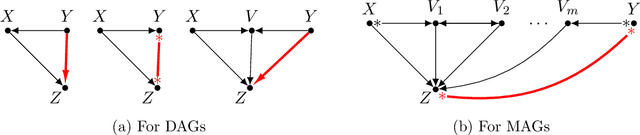
Causal discovery, i.e., learning the causal graph from data, is often the first step toward the identification and estimation of causal effects, a key requirement in numerous scientific domains. Causal discovery is hampered by two main challenges: limited data results in errors in statistical testing and the computational complexity of the learning task is daunting. This paper builds upon and extends four of our prior publications (Mokhtarian et al., 2021; Akbari et al., 2021; Mokhtarian et al., 2022, 2023a). These works introduced the concept of removable variables, which are the only variables that can be removed recursively for the purpose of causal discovery. Presence and identification of removable variables allow recursive approaches for causal discovery, a promising solution that helps to address the aforementioned challenges by reducing the problem size successively. This reduction not only minimizes conditioning sets in each conditional independence (CI) test, leading to fewer errors but also significantly decreases the number of required CI tests. The worst-case performances of these methods nearly match the lower bound. In this paper, we present a unified framework for the proposed algorithms, refined with additional details and enhancements for a coherent presentation. A comprehensive literature review is also included, comparing the computational complexity of our methods with existing approaches, showcasing their state-of-the-art efficiency. Another contribution of this paper is the release of RCD, a Python package that efficiently implements these algorithms. This package is designed for practitioners and researchers interested in applying these methods in practical scenarios. The package is available at github.com/ban-epfl/rcd, with comprehensive documentation provided at rcdpackage.com.
Contextual Combinatorial Volatile Bandits with Satisfying via Gaussian Processes
Nov 29, 2021
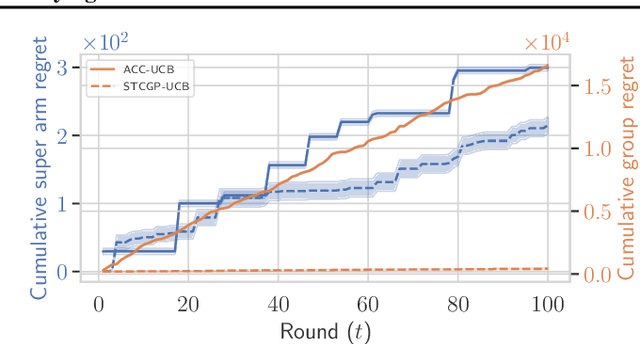
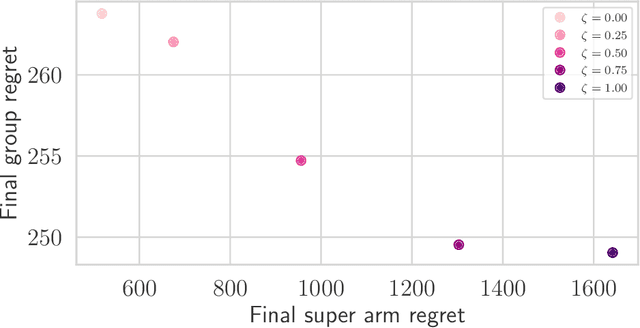
In many real-world applications of combinatorial bandits such as content caching, rewards must be maximized while satisfying minimum service requirements. In addition, base arm availabilities vary over time, and actions need to be adapted to the situation to maximize the rewards. We propose a new bandit model called Contextual Combinatorial Volatile Bandits with Group Thresholds to address these challenges. Our model subsumes combinatorial bandits by considering super arms to be subsets of groups of base arms. We seek to maximize super arm rewards while satisfying thresholds of all base arm groups that constitute a super arm. To this end, we define a new notion of regret that merges super arm reward maximization with group reward satisfaction. To facilitate learning, we assume that the mean outcomes of base arms are samples from a Gaussian Process indexed by the context set ${\cal X}$, and the expected reward is Lipschitz continuous in expected base arm outcomes. We propose an algorithm, called Thresholded Combinatorial Gaussian Process Upper Confidence Bounds (TCGP-UCB), that balances between maximizing cumulative reward and satisfying group reward thresholds and prove that it incurs $\tilde{O}(K\sqrt{T\overline{\gamma}_{T}} )$ regret with high probability, where $\overline{\gamma}_{T}$ is the maximum information gain associated with the set of base arm contexts that appeared in the first $T$ rounds and $K$ is the maximum super arm cardinality of any feasible action over all rounds. We show in experiments that our algorithm accumulates a reward comparable with that of the state-of-the-art combinatorial bandit algorithm while picking actions whose groups satisfy their thresholds.
Contextual Combinatorial Volatile Bandits via Gaussian Processes
Oct 05, 2021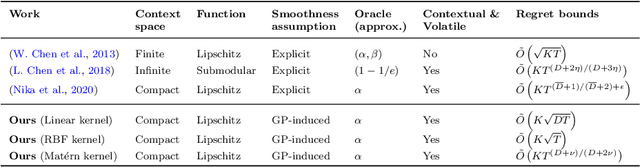
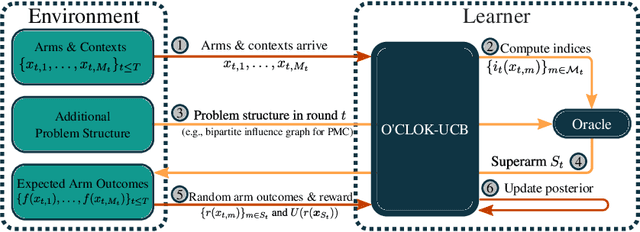
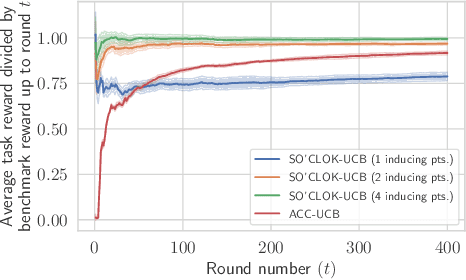
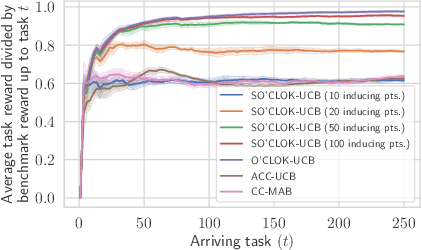
We consider a contextual bandit problem with a combinatorial action set and time-varying base arm availability. At the beginning of each round, the agent observes the set of available base arms and their contexts and then selects an action that is a feasible subset of the set of available base arms to maximize its cumulative reward in the long run. We assume that the mean outcomes of base arms are samples from a Gaussian Process indexed by the context set ${\cal X}$, and the expected reward is Lipschitz continuous in expected base arm outcomes. For this setup, we propose an algorithm called Optimistic Combinatorial Learning and Optimization with Kernel Upper Confidence Bounds (O'CLOK-UCB) and prove that it incurs $\tilde{O}(K\sqrt{T\overline{\gamma}_{T}} )$ regret with high probability, where $\overline{\gamma}_{T}$ is the maximum information gain associated with the set of base arm contexts that appeared in the first $T$ rounds and $K$ is the maximum cardinality of any feasible action over all rounds. To dramatically speed up the algorithm, we also propose a variant of O'CLOK-UCB that uses sparse GPs. Finally, we experimentally show that both algorithms exploit inter-base arm outcome correlation and vastly outperform the previous state-of-the-art UCB-based algorithms in realistic setups.