 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-User mmWave Beam and Rate Adaptation via Combinatorial Satisficing Bandits
Apr 16, 2026We study downlink beam and rate adaptation in a multi-user mmWave MISO system where multiple base stations (BSs), each using analog beamforming from finite codebooks, serve multiple single-antenna user equipments (UEs) with a unique beam per UE and discrete data transmission rates. BSs learn about transmission success based on ACK/NACK feedback. To encode service goals, we introduce a satisficing throughput threshold $τ_r$ and cast joint beam and rate adaptation as a combinatorial semi-bandit over beam-rate tuples. Within this framework, we propose SAT-CTS, a lightweight, threshold-aware policy that blends conservative confidence estimates with posterior sampling, steering learning toward meeting $τ_r$ rather than merely maximizing. Our main theoretical contribution provides the first finite-time regret bounds for combinatorial semi-bandits with satisficing objective: when $τ_r$ is realizable, we upper bound the cumulative satisficing regret to the target with a time-independent constant, and when $τ_r$ is non-realizable, we show that SAT-CTS incurs only a finite expected transient outside committed CTS rounds, after which its regret is governed by the sum of the regret contributions of restarted CTS rounds, yielding an $O((\log T)^2)$ standard regret bound. On the practical side, we evaluate the performance via cumulative satisficing regret to $τ_r$ alongside standard regret and fairness. Experiments with time-varying sparse multipath channels show that SAT-CTS consistently reduces satisficing regret and maintains competitive standard regret, while achieving favorable average throughput and fairness across users, indicating that feedback-efficient learning can equitably allocate beams and rates to meet QoS targets without channel state knowledge.
Cost-aware LLM-based Online Dataset Annotation
May 21, 2025
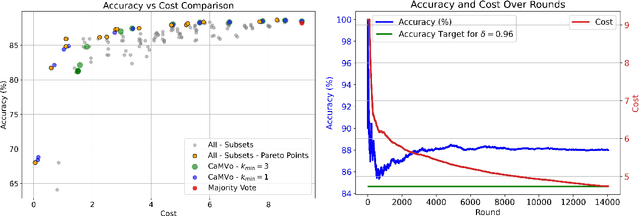


Recent advances in large language models (LLMs) have enabled automated dataset labeling with minimal human supervision. While majority voting across multiple LLMs can improve label reliability by mitigating individual model biases, it incurs high computational costs due to repeated querying. In this work, we propose a novel online framework, Cost-aware Majority Voting (CaMVo), for efficient and accurate LLM-based dataset annotation. CaMVo adaptively selects a subset of LLMs for each data instance based on contextual embeddings, balancing confidence and cost without requiring pre-training or ground-truth labels. Leveraging a LinUCB-based selection mechanism and a Bayesian estimator over confidence scores, CaMVo estimates a lower bound on labeling accuracy for each LLM and aggregates responses through weighted majority voting. Our empirical evaluation on the MMLU and IMDB Movie Review datasets demonstrates that CaMVo achieves comparable or superior accuracy to full majority voting while significantly reducing labeling costs. This establishes CaMVo as a practical and robust solution for cost-efficient annotation in dynamic labeling environments.
Bandits with Anytime Knapsacks
Jan 30, 2025



We consider bandits with anytime knapsacks (BwAK), a novel version of the BwK problem where there is an \textit{anytime} cost constraint instead of a total cost budget. This problem setting introduces additional complexities as it mandates adherence to the constraint throughout the decision-making process. We propose SUAK, an algorithm that utilizes upper confidence bounds to identify the optimal mixture of arms while maintaining a balance between exploration and exploitation. SUAK is an adaptive algorithm that strategically utilizes the available budget in each round in the decision-making process and skips a round when it is possible to violate the anytime cost constraint. In particular, SUAK slightly under-utilizes the available cost budget to reduce the need for skipping rounds. We show that SUAK attains the same problem-dependent regret upper bound of $ O(K \log T)$ established in prior work under the simpler BwK framework. Finally, we provide simulations to verify the utility of SUAK in practical settings.
VOPy: A Framework for Black-box Vector Optimization
Dec 09, 2024We introduce VOPy, an open-source Python library designed to address black-box vector optimization, where multiple objectives must be optimized simultaneously with respect to a partial order induced by a convex cone. VOPy extends beyond traditional multi-objective optimization (MOO) tools by enabling flexible, cone-based ordering of solutions; with an application scope that includes environments with observation noise, discrete or continuous design spaces, limited budgets, and batch observations. VOPy provides a modular architecture, facilitating the integration of existing methods and the development of novel algorithms. We detail VOPy's architecture, usage, and potential to advance research and application in the field of vector optimization. The source code for VOPy is available at https://github.com/Bilkent-CYBORG/VOPy.
Vector Optimization with Gaussian Process Bandits
Dec 03, 2024Learning problems in which multiple conflicting objectives must be considered simultaneously often arise in various fields, including engineering, drug design, and environmental management. Traditional methods for dealing with multiple black-box objective functions, such as scalarization and identification of the Pareto set under the componentwise order, have limitations in incorporating objective preferences and exploring the solution space accordingly. While vector optimization offers improved flexibility and adaptability via specifying partial orders based on ordering cones, current techniques designed for sequential experiments either suffer from high sample complexity or lack theoretical guarantees. To address these issues, we propose Vector Optimization with Gaussian Process (VOGP), a probably approximately correct adaptive elimination algorithm that performs black-box vector optimization using Gaussian process bandits. VOGP allows users to convey objective preferences through ordering cones while performing efficient sampling by exploiting the smoothness of the objective function, resulting in a more effective optimization process that requires fewer evaluations. We establish theoretical guarantees for VOGP and derive information gain-based and kernel-specific sample complexity bounds. We also conduct experiments on both real-world and synthetic datasets to compare VOGP with the state-of-the-art methods.
Robust Bayesian Satisficing
Aug 16, 2023

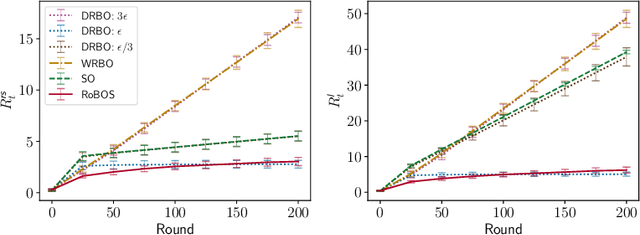

Distributional shifts pose a significant challenge to achieving robustness in contemporary machine learning. To overcome this challenge, robust satisficing (RS) seeks a robust solution to an unspecified distributional shift while achieving a utility above a desired threshold. This paper focuses on the problem of RS in contextual Bayesian optimization when there is a discrepancy between the true and reference distributions of the context. We propose a novel robust Bayesian satisficing algorithm called RoBOS for noisy black-box optimization. Our algorithm guarantees sublinear lenient regret under certain assumptions on the amount of distribution shift. In addition, we define a weaker notion of regret called robust satisficing regret, in which our algorithm achieves a sublinear upper bound independent of the amount of distribution shift. To demonstrate the effectiveness of our method, we apply it to various learning problems and compare it to other approaches, such as distributionally robust optimization.
Robust Pareto Set Identification with Contaminated Bandit Feedback
Jun 06, 2022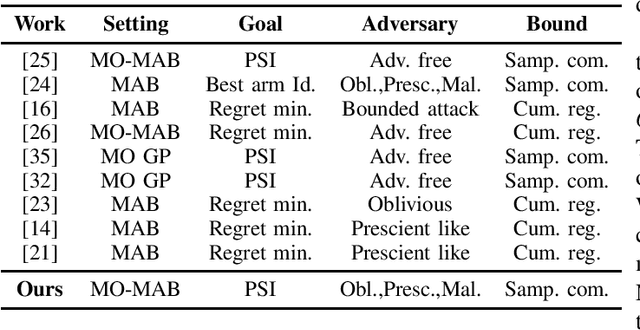
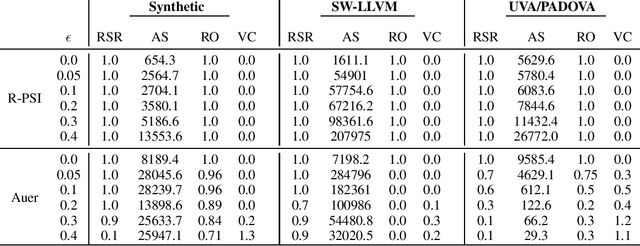
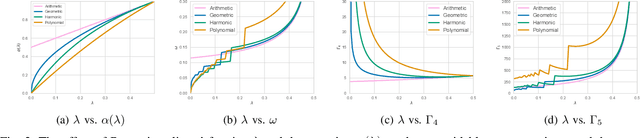
We consider the Pareto set identification (PSI) problem in multi-objective multi-armed bandits (MO-MAB) with contaminated reward observations. At each arm pull, with some probability, the true reward samples are replaced with the samples from an arbitrary contamination distribution chosen by the adversary. We propose a median-based MO-MAB algorithm for robust PSI that abides by the accuracy requirements set by the user via an accuracy parameter. We prove that the sample complexity of this algorithm depends on the accuracy parameter inverse squarely. We compare the proposed algorithm with a mean-based method from MO-MAB literature on Gaussian reward distributions. Our numerical results verify our theoretical expectations and show the necessity for robust algorithm design in the adversarial setting.
Federated Multi-Armed Bandits Under Byzantine Attacks
May 09, 2022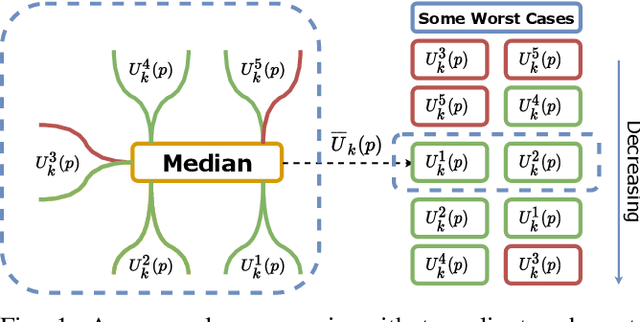
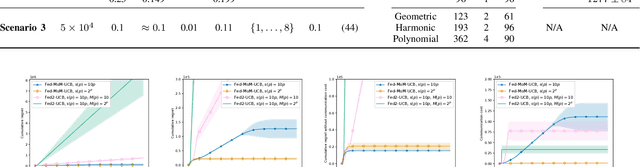
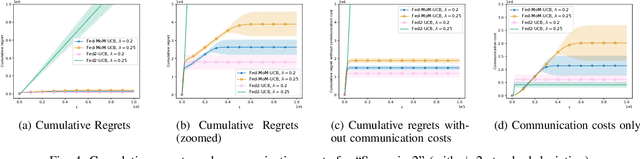
Multi-armed bandits (MAB) is a simple reinforcement learning model where the learner controls the trade-off between exploration versus exploitation to maximize its cumulative reward. Federated multi-armed bandits (FMAB) is a recently emerging framework where a cohort of learners with heterogeneous local models play a MAB game and communicate their aggregated feedback to a parameter server to learn the global feedback model. Federated learning models are vulnerable to adversarial attacks such as model-update attacks or data poisoning. In this work, we study an FMAB problem in the presence of Byzantine clients who can send false model updates that pose a threat to the learning process. We borrow tools from robust statistics and propose a median-of-means-based estimator: Fed-MoM-UCB, to cope with the Byzantine clients. We show that if the Byzantine clients constitute at most half the cohort, it is possible to incur a cumulative regret on the order of ${\cal O} (\log T)$ with respect to an unavoidable error margin, including the communication cost between the clients and the parameter server. We analyze the interplay between the algorithm parameters, unavoidable error margin, regret, communication cost, and the arms' suboptimality gaps. We demonstrate Fed-MoM-UCB's effectiveness against the baselines in the presence of Byzantine attacks via experiments.
Safe Linear Leveling Bandits
Dec 13, 2021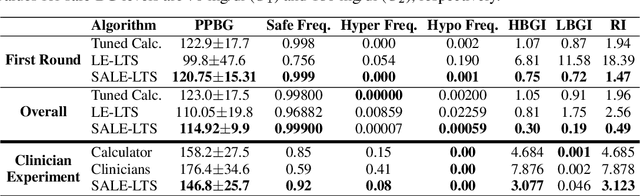
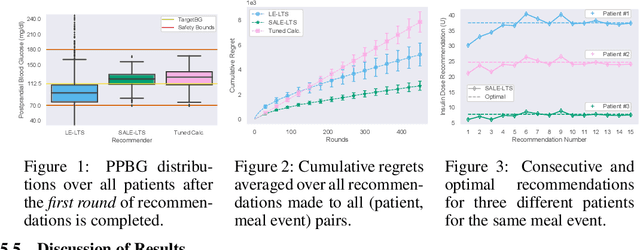
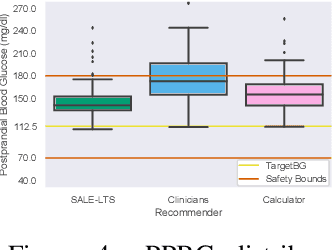
Multi-armed bandits (MAB) are extensively studied in various settings where the objective is to \textit{maximize} the actions' outcomes (i.e., rewards) over time. Since safety is crucial in many real-world problems, safe versions of MAB algorithms have also garnered considerable interest. In this work, we tackle a different critical task through the lens of \textit{linear stochastic bandits}, where the aim is to keep the actions' outcomes close to a target level while respecting a \textit{two-sided} safety constraint, which we call \textit{leveling}. Such a task is prevalent in numerous domains. Many healthcare problems, for instance, require keeping a physiological variable in a range and preferably close to a target level. The radical change in our objective necessitates a new acquisition strategy, which is at the heart of a MAB algorithm. We propose SALE-LTS: Safe Leveling via Linear Thompson Sampling algorithm, with a novel acquisition strategy to accommodate our task and show that it achieves sublinear regret with the same time and dimension dependence as previous works on the classical reward maximization problem absent any safety constraint. We demonstrate and discuss our algorithm's empirical performance in detail via thorough experiments.
Contextual Combinatorial Volatile Bandits with Satisfying via Gaussian Processes
Nov 29, 2021
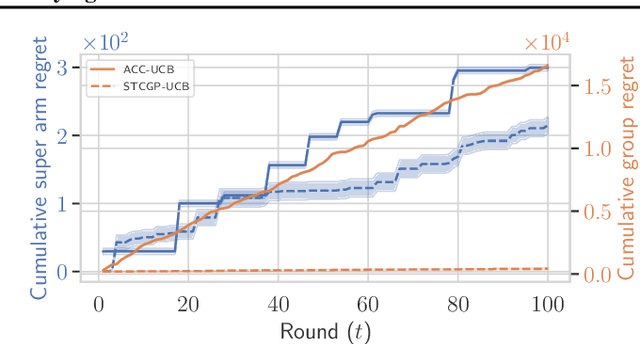
In many real-world applications of combinatorial bandits such as content caching, rewards must be maximized while satisfying minimum service requirements. In addition, base arm availabilities vary over time, and actions need to be adapted to the situation to maximize the rewards. We propose a new bandit model called Contextual Combinatorial Volatile Bandits with Group Thresholds to address these challenges. Our model subsumes combinatorial bandits by considering super arms to be subsets of groups of base arms. We seek to maximize super arm rewards while satisfying thresholds of all base arm groups that constitute a super arm. To this end, we define a new notion of regret that merges super arm reward maximization with group reward satisfaction. To facilitate learning, we assume that the mean outcomes of base arms are samples from a Gaussian Process indexed by the context set ${\cal X}$, and the expected reward is Lipschitz continuous in expected base arm outcomes. We propose an algorithm, called Thresholded Combinatorial Gaussian Process Upper Confidence Bounds (TCGP-UCB), that balances between maximizing cumulative reward and satisfying group reward thresholds and prove that it incurs $\tilde{O}(K\sqrt{T\overline{\gamma}_{T}} )$ regret with high probability, where $\overline{\gamma}_{T}$ is the maximum information gain associated with the set of base arm contexts that appeared in the first $T$ rounds and $K$ is the maximum super arm cardinality of any feasible action over all rounds. We show in experiments that our algorithm accumulates a reward comparable with that of the state-of-the-art combinatorial bandit algorithm while picking actions whose groups satisfy their thresholds.