 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Manipulation through Symbolic Planning and Residual Operator Learning
Jun 03, 2026Inverting a robotic task requires more than reversing symbolic state transitions or rewinding motor trajectories. In robot manipulation tasks, symbolic inverse plans often fail to fully restore the effects of forward executions under continuous interaction dynamics. We present a hybrid framework for inverse manipulation that derives inverse-skill objectives from STRIPS-like operators automatically extracted from demonstrations through soft geometric predicates. For each extracted operator, we construct an inverse restoration objective that preserves preconditions, restores delete effects, and negates add effects. A task planner first attempts to satisfy this objective using available action primitives. Unresolved symbolic predicates then induce a residual operator learning problem solved through Reinforcement Learning (RL). We evaluate the framework on the ManiSkill3 PushCube task. For a forward pushing skill, the symbolic inverse performs a coarse pick-and-place restoration, while a residual Soft Actor-Critic policy refines the cube pose to satisfy the remaining inverse predicates. Our results show that predicate-derived residual control can turn an approximate symbolic inverse into a physically grounded inverse skill.
RAMPA: Robotic Augmented Reality for Machine Programming and Automation
Oct 17, 2024As robotics continue to enter various sectors beyond traditional industrial applications, the need for intuitive robot training and interaction systems becomes increasingly more important. This paper introduces Robotic Augmented Reality for Machine Programming (RAMPA), a system that utilizes the capabilities of state-of-the-art and commercially available AR headsets, e.g., Meta Quest 3, to facilitate the application of Programming from Demonstration (PfD) approaches on industrial robotic arms, such as Universal Robots UR10. Our approach enables in-situ data recording, visualization, and fine-tuning of skill demonstrations directly within the user's physical environment. RAMPA addresses critical challenges of PfD, such as safety concerns, programming barriers, and the inefficiency of collecting demonstrations on the actual hardware. The performance of our system is evaluated against the traditional method of kinesthetic control in teaching three different robotic manipulation tasks and analyzed with quantitative metrics, measuring task performance and completion time, trajectory smoothness, system usability, user experience, and task load using standardized surveys. Our findings indicate a substantial advancement in how robotic tasks are taught and refined, promising improvements in operational safety, efficiency, and user engagement in robotic programming.
Bidirectional Human Interactive AI Framework for Social Robot Navigation
Apr 05, 2024Trustworthiness is a crucial concept in the context of human-robot interaction. Cooperative robots must be transparent regarding their decision-making process, especially when operating in a human-oriented environment. This paper presents a comprehensive end-to-end framework aimed at fostering trustworthy bidirectional human-robot interaction in collaborative environments for the social navigation of mobile robots. Our method enables a mobile robot to predict the trajectory of people and adjust its route in a socially-aware manner. In case of conflict between human and robot decisions, detected through visual examination, the route is dynamically modified based on human preference while verbal communication is maintained. We present our pipeline, framework design, and preliminary experiments that form the foundation of our proposition.
Conditional Neural Expert Processes for Learning from Demonstration
Feb 13, 2024



Learning from Demonstration (LfD) is a widely used technique for skill acquisition in robotics. However, demonstrations of the same skill may exhibit significant variances, or learning systems may attempt to acquire different means of the same skill simultaneously, making it challenging to encode these motions into movement primitives. To address these challenges, we propose an LfD framework, namely the Conditional Neural Expert Processes (CNEP), that learns to assign demonstrations from different modes to distinct expert networks utilizing the inherent information within the latent space to match experts with the encoded representations. CNEP does not require supervision on which mode the trajectories belong to. Provided experiments on artificially generated datasets demonstrate the efficacy of CNEP. Furthermore, we compare the performance of CNEP with another LfD framework, namely Conditional Neural Movement Primitives (CNMP), on a range of tasks, including experiments on a real robot. The results reveal enhanced modeling performance for movement primitives, leading to the synthesis of trajectories that more accurately reflect those demonstrated by experts, particularly when the model inputs include intersection points from various trajectories. Additionally, CNEP offers improved interpretability and faster convergence by promoting expert specialization. Furthermore, we show that the CNEP model accomplishes obstacle avoidance tasks with a real manipulator when provided with novel start and destination points, in contrast to the CNMP model, which leads to collisions with the obstacle.
Learning Social Navigation from Demonstrations with Conditional Neural Processes
Oct 07, 2022



Sociability is essential for modern robots to increase their acceptability in human environments. Traditional techniques use manually engineered utility functions inspired by observing pedestrian behaviors to achieve social navigation. However, social aspects of navigation are diverse, changing across different types of environments, societies, and population densities, making it unrealistic to use hand-crafted techniques in each domain. This paper presents a data-driven navigation architecture that uses state-of-the-art neural architectures, namely Conditional Neural Processes, to learn global and local controllers of the mobile robot from observations. Additionally, we leverage a state-of-the-art, deep prediction mechanism to detect situations not similar to the trained ones, where reactive controllers step in to ensure safe navigation. Our results demonstrate that the proposed framework can successfully carry out navigation tasks regarding social norms in the data. Further, we showed that our system produces fewer personal-zone violations, causing less discomfort.
Federated Multi-Armed Bandits Under Byzantine Attacks
May 09, 2022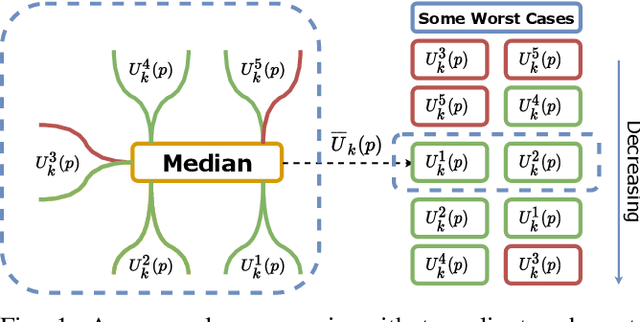
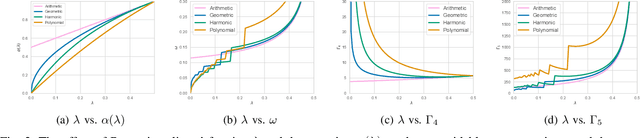
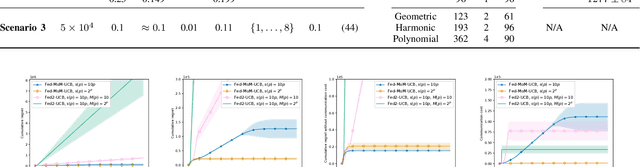
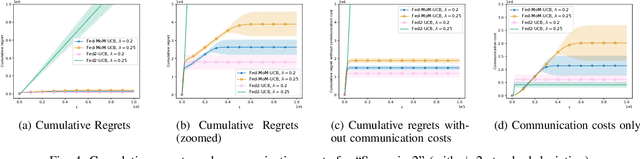
Multi-armed bandits (MAB) is a simple reinforcement learning model where the learner controls the trade-off between exploration versus exploitation to maximize its cumulative reward. Federated multi-armed bandits (FMAB) is a recently emerging framework where a cohort of learners with heterogeneous local models play a MAB game and communicate their aggregated feedback to a parameter server to learn the global feedback model. Federated learning models are vulnerable to adversarial attacks such as model-update attacks or data poisoning. In this work, we study an FMAB problem in the presence of Byzantine clients who can send false model updates that pose a threat to the learning process. We borrow tools from robust statistics and propose a median-of-means-based estimator: Fed-MoM-UCB, to cope with the Byzantine clients. We show that if the Byzantine clients constitute at most half the cohort, it is possible to incur a cumulative regret on the order of ${\cal O} (\log T)$ with respect to an unavoidable error margin, including the communication cost between the clients and the parameter server. We analyze the interplay between the algorithm parameters, unavoidable error margin, regret, communication cost, and the arms' suboptimality gaps. We demonstrate Fed-MoM-UCB's effectiveness against the baselines in the presence of Byzantine attacks via experiments.