 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilevel Planning with Learned Symbolic Abstractions from Interaction Data
Mar 09, 2026Intelligent agents must reason over both continuous dynamics and discrete representations to generate effective plans in complex environments. Previous studies have shown that symbolic abstractions can emerge from neural effect predictors trained with a robot's unsupervised exploration. However, these methods rely on deterministic symbolic domains, lack mechanisms to verify the generated symbolic plans, and operate only at the abstract level, often failing to capture the continuous dynamics of the environment. To overcome these limitations, we propose a bilevel neuro-symbolic framework in which learned probabilistic symbolic rules generate candidate plans rapidly at the high level, and learned continuous effect models verify these plans and perform forward search when necessary at the low level. Our experiments on multi-object manipulation tasks demonstrate that the proposed bilevel method outperforms symbolic-only approaches, reliably identifying failing plans through verification, and achieves planning performance statistically comparable to continuous forward search while resolving most problems via efficient symbolic reasoning.
Unsupervised Meta-Testing with Conditional Neural Processes for Hybrid Meta-Reinforcement Learning
Jun 04, 2025We introduce Unsupervised Meta-Testing with Conditional Neural Processes (UMCNP), a novel hybrid few-shot meta-reinforcement learning (meta-RL) method that uniquely combines, yet distinctly separates, parameterized policy gradient-based (PPG) and task inference-based few-shot meta-RL. Tailored for settings where the reward signal is missing during meta-testing, our method increases sample efficiency without requiring additional samples in meta-training. UMCNP leverages the efficiency and scalability of Conditional Neural Processes (CNPs) to reduce the number of online interactions required in meta-testing. During meta-training, samples previously collected through PPG meta-RL are efficiently reused for learning task inference in an offline manner. UMCNP infers the latent representation of the transition dynamics model from a single test task rollout with unknown parameters. This approach allows us to generate rollouts for self-adaptation by interacting with the learned dynamics model. We demonstrate our method can adapt to an unseen test task using significantly fewer samples during meta-testing than the baselines in 2D-Point Agent and continuous control meta-RL benchmarks, namely, cartpole with unknown angle sensor bias, walker agent with randomized dynamics parameters.
* Published in IEEE Robotics and Automation Letters Volume: 9, Issue: 10, 8427 - 8434, October 2024. 8 pages, 7 figures
Predictability-Based Curiosity-Guided Action Symbol Discovery
May 23, 2025Discovering symbolic representations for skills is essential for abstract reasoning and efficient planning in robotics. Previous neuro-symbolic robotic studies mostly focused on discovering perceptual symbolic categories given a pre-defined action repertoire and generating plans with given action symbols. A truly developmental robotic system, on the other hand, should be able to discover all the abstractions required for the planning system with minimal human intervention. In this study, we propose a novel system that is designed to discover symbolic action primitives along with perceptual symbols autonomously. Our system is based on an encoder-decoder structure that takes object and action information as input and predicts the generated effect. To efficiently explore the vast continuous action parameter space, we introduce a Curiosity-Based exploration module that selects the most informative actions -- the ones that maximize the entropy in the predicted effect distribution. The discovered symbolic action primitives are then used to make plans using a symbolic tree search strategy in single- and double-object manipulation tasks. We compare our model with two baselines that use different exploration strategies in different experiments. The results show that our approach can learn a diverse set of symbolic action primitives, which are effective for generating plans in order to achieve given manipulation goals.
Energy Weighted Learning Progress Guided Interleaved Multi-Task Learning
Apr 01, 2025Humans can continuously acquire new skills and knowledge by exploiting existing ones for improved learning, without forgetting them. Similarly, 'continual learning' in machine learning aims to learn new information while preserving the previously acquired knowledge. Existing research often overlooks the nature of human learning, where tasks are interleaved due to human choice or environmental constraints. So, almost never do humans master one task before switching to the next. To investigate to what extent human-like learning can benefit the learner, we propose a method that interleaves tasks based on their 'learning progress' and energy consumption. From a machine learning perspective, our approach can be seen as a multi-task learning system that balances learning performance with energy constraints while mimicking ecologically realistic human task learning. To assess the validity of our approach, we consider a robot learning setting in simulation, where the robot learns the effect of its actions in different contexts. The conducted experiments show that our proposed method achieves better performance than sequential task learning and reduces energy consumption for learning the tasks.
RAMPA: Robotic Augmented Reality for Machine Programming and Automation
Oct 17, 2024As robotics continue to enter various sectors beyond traditional industrial applications, the need for intuitive robot training and interaction systems becomes increasingly more important. This paper introduces Robotic Augmented Reality for Machine Programming (RAMPA), a system that utilizes the capabilities of state-of-the-art and commercially available AR headsets, e.g., Meta Quest 3, to facilitate the application of Programming from Demonstration (PfD) approaches on industrial robotic arms, such as Universal Robots UR10. Our approach enables in-situ data recording, visualization, and fine-tuning of skill demonstrations directly within the user's physical environment. RAMPA addresses critical challenges of PfD, such as safety concerns, programming barriers, and the inefficiency of collecting demonstrations on the actual hardware. The performance of our system is evaluated against the traditional method of kinesthetic control in teaching three different robotic manipulation tasks and analyzed with quantitative metrics, measuring task performance and completion time, trajectory smoothness, system usability, user experience, and task load using standardized surveys. Our findings indicate a substantial advancement in how robotic tasks are taught and refined, promising improvements in operational safety, efficiency, and user engagement in robotic programming.
VQ-CNMP: Neuro-Symbolic Skill Learning for Bi-Level Planning
Oct 13, 2024



This paper proposes a novel neural network model capable of discovering high-level skill representations from unlabeled demonstration data. We also propose a bi-level planning pipeline that utilizes our model using a gradient-based planning approach. While extracting high-level representations, our model also preserves the low-level information, which can be used for low-level action planning. In the experiments, we tested the skill discovery performance of our model under different conditions, tested whether Multi-Modal LLMs can be utilized to label the learned high-level skill representations, and finally tested the high-level and low-level planning performance of our pipeline.
Affordance Blending Networks
Apr 24, 2024



Affordances, a concept rooted in ecological psychology and pioneered by James J. Gibson, have emerged as a fundamental framework for understanding the dynamic relationship between individuals and their environments. Expanding beyond traditional perceptual and cognitive paradigms, affordances represent the inherent effect and action possibilities that objects offer to the agents within a given context. As a theoretical lens, affordances bridge the gap between effect and action, providing a nuanced understanding of the connections between agents' actions on entities and the effect of these actions. In this study, we propose a model that unifies object, action and effect into a single latent representation in a common latent space that is shared between all affordances that we call the affordance space. Using this affordance space, our system is able to generate effect trajectories when action and object are given and is able to generate action trajectories when effect trajectories and objects are given. In the experiments, we showed that our model does not learn the behavior of each object but it learns the affordance relations shared by the objects that we call equivalences. In addition to simulated experiments, we showed that our model can be used for direct imitation in real world cases. We also propose affordances as a base for Cross Embodiment transfer to link the actions of different robots. Finally, we introduce selective loss as a solution that allows valid outputs to be generated for indeterministic model inputs.
Bidirectional Human Interactive AI Framework for Social Robot Navigation
Apr 05, 2024Trustworthiness is a crucial concept in the context of human-robot interaction. Cooperative robots must be transparent regarding their decision-making process, especially when operating in a human-oriented environment. This paper presents a comprehensive end-to-end framework aimed at fostering trustworthy bidirectional human-robot interaction in collaborative environments for the social navigation of mobile robots. Our method enables a mobile robot to predict the trajectory of people and adjust its route in a socially-aware manner. In case of conflict between human and robot decisions, detected through visual examination, the route is dynamically modified based on human preference while verbal communication is maintained. We present our pipeline, framework design, and preliminary experiments that form the foundation of our proposition.
Learning Early Social Maneuvers for Enhanced Social Navigation
Mar 23, 2024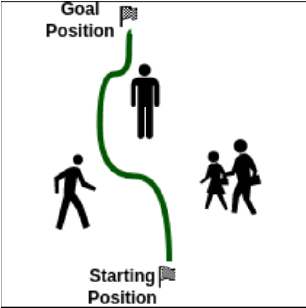
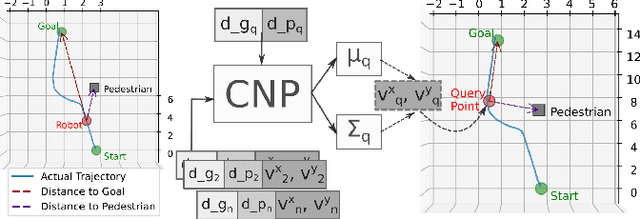
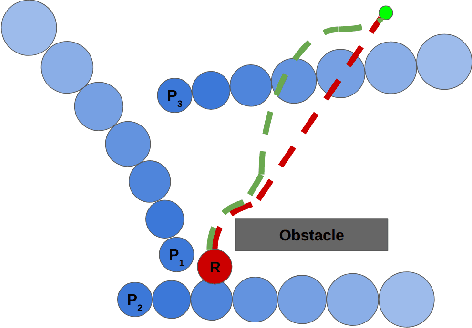
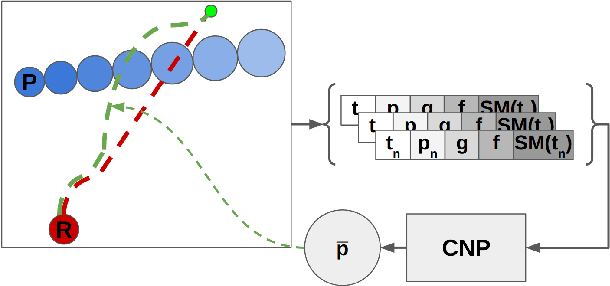
Socially compliant navigation is an integral part of safety features in Human-Robot Interaction. Traditional approaches to mobile navigation prioritize physical aspects, such as efficiency, but social behaviors gain traction as robots appear more in daily life. Recent techniques to improve the social compliance of navigation often rely on predefined features or reward functions, introducing assumptions about social human behavior. To address this limitation, we propose a novel Learning from Demonstration (LfD) framework for social navigation that exclusively utilizes raw sensory data. Additionally, the proposed system contains mechanisms to consider the future paths of the surrounding pedestrians, acknowledging the temporal aspect of the problem. The final product is expected to reduce the anxiety of people sharing their environment with a mobile robot, helping them trust that the robot is aware of their presence and will not harm them. As the framework is currently being developed, we outline its components, present experimental results, and discuss future work towards realizing this framework.
Bidirectional Progressive Neural Networks with Episodic Return Progress for Emergent Task Sequencing and Robotic Skill Transfer
Mar 06, 2024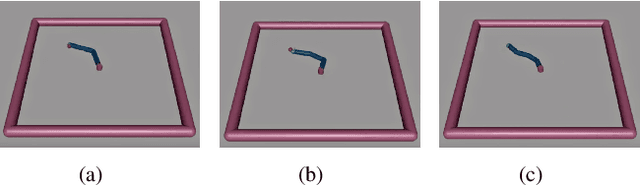
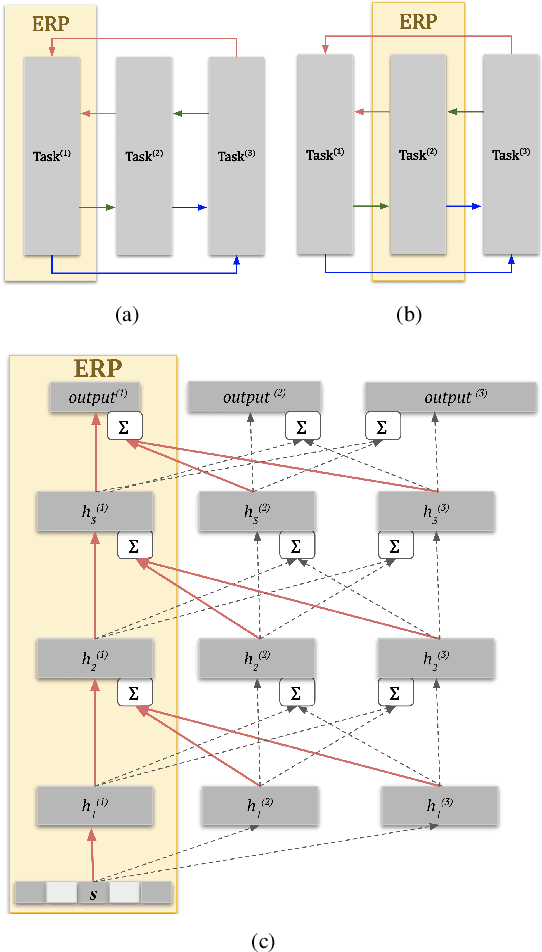
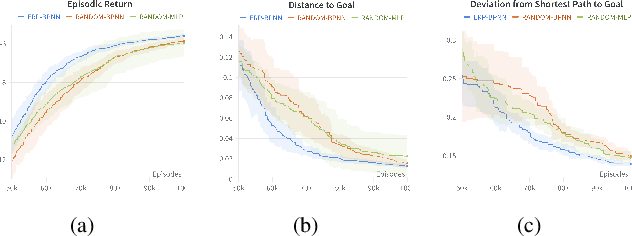

Human brain and behavior provide a rich venue that can inspire novel control and learning methods for robotics. In an attempt to exemplify such a development by inspiring how humans acquire knowledge and transfer skills among tasks, we introduce a novel multi-task reinforcement learning framework named Episodic Return Progress with Bidirectional Progressive Neural Networks (ERP-BPNN). The proposed ERP-BPNN model (1) learns in a human-like interleaved manner by (2) autonomous task switching based on a novel intrinsic motivation signal and, in contrast to existing methods, (3) allows bidirectional skill transfer among tasks. ERP-BPNN is a general architecture applicable to several multi-task learning settings; in this paper, we present the details of its neural architecture and show its ability to enable effective learning and skill transfer among morphologically different robots in a reaching task. The developed Bidirectional Progressive Neural Network (BPNN) architecture enables bidirectional skill transfer without requiring incremental training and seamlessly integrates with online task arbitration. The task arbitration mechanism developed is based on soft Episodic Return progress (ERP), a novel intrinsic motivation (IM) signal. To evaluate our method, we use quantifiable robotics metrics such as 'expected distance to goal' and 'path straightness' in addition to the usual reward-based measure of episodic return common in reinforcement learning. With simulation experiments, we show that ERP-BPNN achieves faster cumulative convergence and improves performance in all metrics considered among morphologically different robots compared to the baselines.