 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQ-CNMP: Neuro-Symbolic Skill Learning for Bi-Level Planning
Oct 13, 2024



This paper proposes a novel neural network model capable of discovering high-level skill representations from unlabeled demonstration data. We also propose a bi-level planning pipeline that utilizes our model using a gradient-based planning approach. While extracting high-level representations, our model also preserves the low-level information, which can be used for low-level action planning. In the experiments, we tested the skill discovery performance of our model under different conditions, tested whether Multi-Modal LLMs can be utilized to label the learned high-level skill representations, and finally tested the high-level and low-level planning performance of our pipeline.
Affordance Blending Networks
Apr 24, 2024



Affordances, a concept rooted in ecological psychology and pioneered by James J. Gibson, have emerged as a fundamental framework for understanding the dynamic relationship between individuals and their environments. Expanding beyond traditional perceptual and cognitive paradigms, affordances represent the inherent effect and action possibilities that objects offer to the agents within a given context. As a theoretical lens, affordances bridge the gap between effect and action, providing a nuanced understanding of the connections between agents' actions on entities and the effect of these actions. In this study, we propose a model that unifies object, action and effect into a single latent representation in a common latent space that is shared between all affordances that we call the affordance space. Using this affordance space, our system is able to generate effect trajectories when action and object are given and is able to generate action trajectories when effect trajectories and objects are given. In the experiments, we showed that our model does not learn the behavior of each object but it learns the affordance relations shared by the objects that we call equivalences. In addition to simulated experiments, we showed that our model can be used for direct imitation in real world cases. We also propose affordances as a base for Cross Embodiment transfer to link the actions of different robots. Finally, we introduce selective loss as a solution that allows valid outputs to be generated for indeterministic model inputs.
Correspondence learning between morphologically different robots through task demonstrations
Oct 20, 2023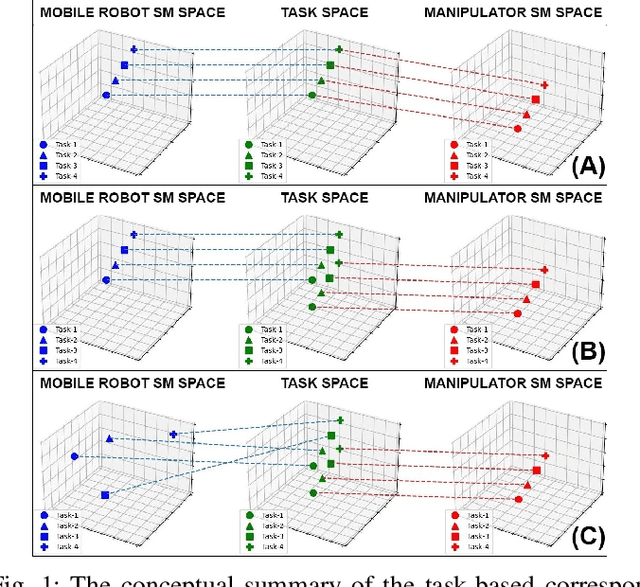
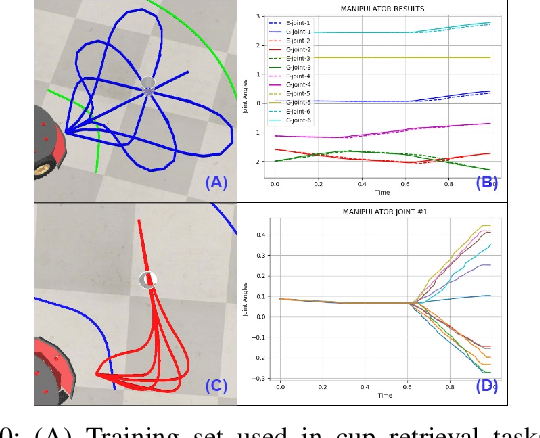
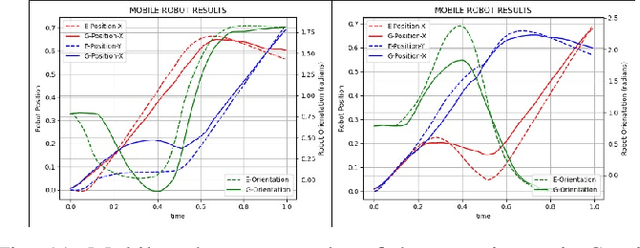
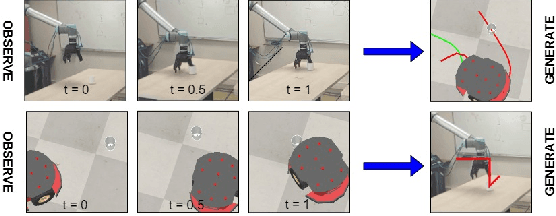
We observe a large variety of robots in terms of their bodies, sensors, and actuators. Given the commonalities in the skill sets, teaching each skill to each different robot independently is inefficient and not scalable when the large variety in the robotic landscape is considered. If we can learn the correspondences between the sensorimotor spaces of different robots, we can expect a skill that is learned in one robot can be more directly and easily transferred to the other robots. In this paper, we propose a method to learn correspondences between robots that have significant differences in their morphologies: a fixed-based manipulator robot with joint control and a differential drive mobile robot. For this, both robots are first given demonstrations that achieve the same tasks. A common latent representation is formed while learning the corresponding policies. After this initial learning stage, the observation of a new task execution by one robot becomes sufficient to generate a latent space representation pertaining to the other robot to achieve the same task. We verified our system in a set of experiments where the correspondence between two simulated robots is learned (1) when the robots need to follow the same paths to achieve the same task, (2) when the robots need to follow different trajectories to achieve the same task, and (3) when complexities of the required sensorimotor trajectories are different for the robots considered. We also provide a proof-of-the-concept realization of correspondence learning between a real manipulator robot and a simulated mobile robot.
Design optimization for high-performance computing using FPGA
Apr 24, 2023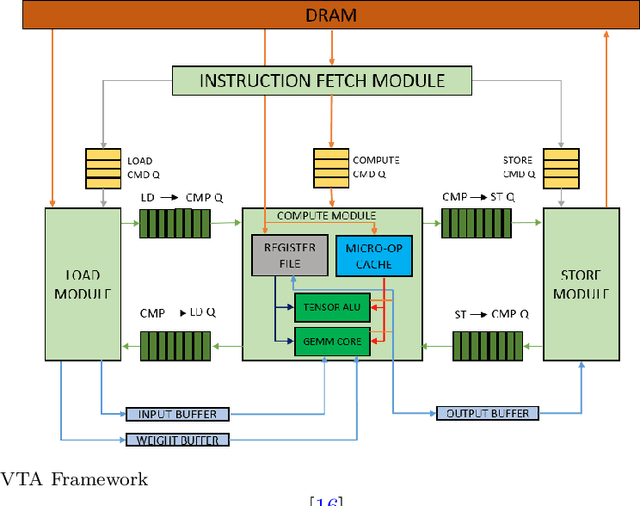
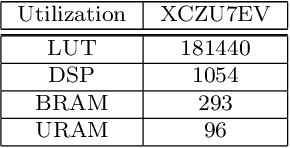
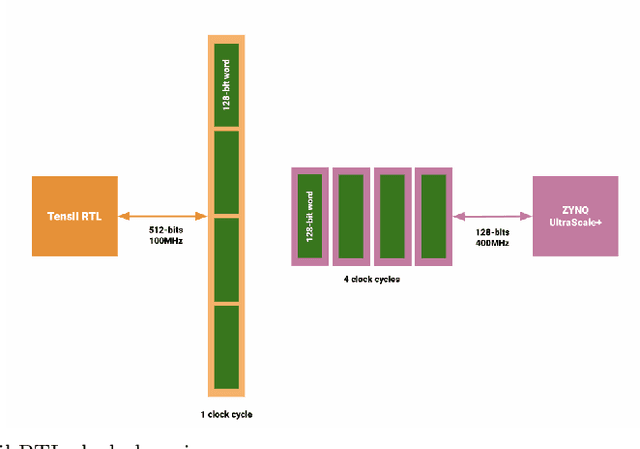
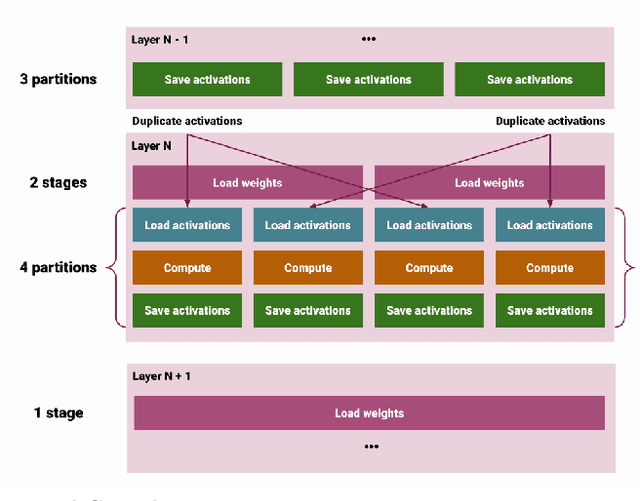
Reconfigurable architectures like Field Programmable Gate Arrays (FPGAs) have been used for accelerating computations in several domains because of their unique combination of flexibility, performance, and power efficiency. However, FPGAs have not been widely used for high-performance computing, primarily because of their programming complexity and difficulties in optimizing performance. We optimize Tensil AI's open-source inference accelerator for maximum performance using ResNet20 trained on CIFAR in this paper in order to gain insight into the use of FPGAs for high-performance computing. In this paper, we show how improving hardware design, using Xilinx Ultra RAM, and using advanced compiler strategies can lead to improved inference performance. We also demonstrate that running the CIFAR test data set shows very little accuracy drop when rounding down from the original 32-bit floating point. The heterogeneous computing model in our platform allows us to achieve a frame rate of 293.58 frames per second (FPS) and a %90 accuracy on a ResNet20 trained using CIFAR. The experimental results show that the proposed accelerator achieves a throughput of 21.12 Giga-Operations Per Second (GOP/s) with a 5.21 W on-chip power consumption at 100 MHz. The comparison results with off-the-shelf devices and recent state-of-the-art implementations illustrate that the proposed accelerator has obvious advantages in terms of energy efficiency.