 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign optimization for high-performance computing using FPGA
Paper and Code
Apr 24, 2023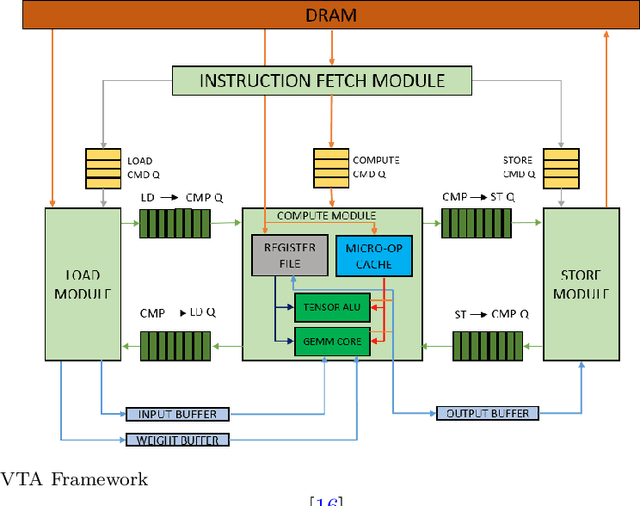
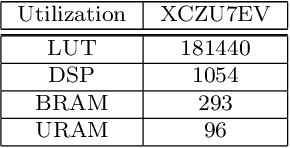
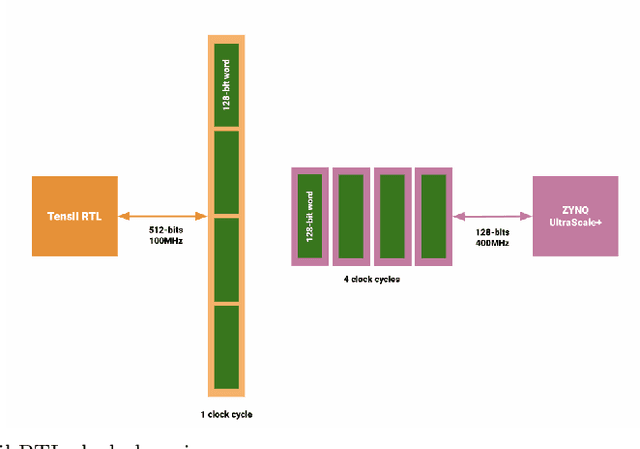
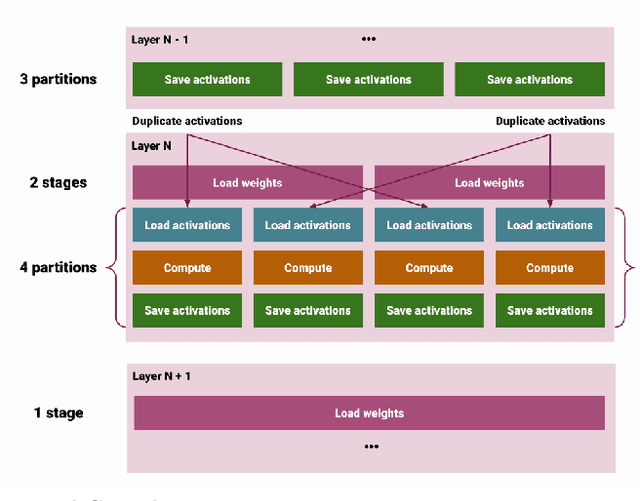
Reconfigurable architectures like Field Programmable Gate Arrays (FPGAs) have been used for accelerating computations in several domains because of their unique combination of flexibility, performance, and power efficiency. However, FPGAs have not been widely used for high-performance computing, primarily because of their programming complexity and difficulties in optimizing performance. We optimize Tensil AI's open-source inference accelerator for maximum performance using ResNet20 trained on CIFAR in this paper in order to gain insight into the use of FPGAs for high-performance computing. In this paper, we show how improving hardware design, using Xilinx Ultra RAM, and using advanced compiler strategies can lead to improved inference performance. We also demonstrate that running the CIFAR test data set shows very little accuracy drop when rounding down from the original 32-bit floating point. The heterogeneous computing model in our platform allows us to achieve a frame rate of 293.58 frames per second (FPS) and a %90 accuracy on a ResNet20 trained using CIFAR. The experimental results show that the proposed accelerator achieves a throughput of 21.12 Giga-Operations Per Second (GOP/s) with a 5.21 W on-chip power consumption at 100 MHz. The comparison results with off-the-shelf devices and recent state-of-the-art implementations illustrate that the proposed accelerator has obvious advantages in terms of energy efficiency.