 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEUROSEC: FPGA-Based Neuromorphic Audio Security
Jan 22, 2024
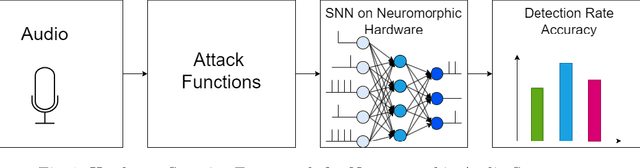
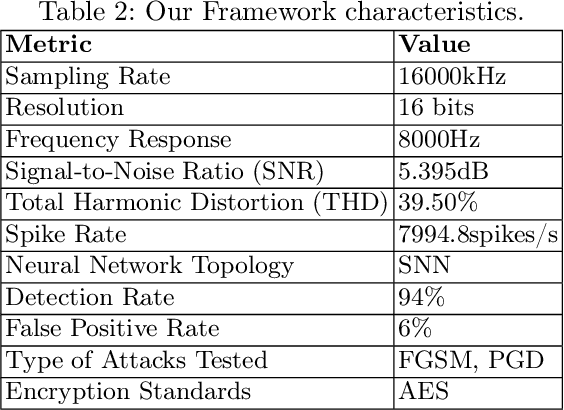
Neuromorphic systems, inspired by the complexity and functionality of the human brain, have gained interest in academic and industrial attention due to their unparalleled potential across a wide range of applications. While their capabilities herald innovation, it is imperative to underscore that these computational paradigms, analogous to their traditional counterparts, are not impervious to security threats. Although the exploration of neuromorphic methodologies for image and video processing has been rigorously pursued, the realm of neuromorphic audio processing remains in its early stages. Our results highlight the robustness and precision of our FPGA-based neuromorphic system. Specifically, our system showcases a commendable balance between desired signal and background noise, efficient spike rate encoding, and unparalleled resilience against adversarial attacks such as FGSM and PGD. A standout feature of our framework is its detection rate of 94%, which, when compared to other methodologies, underscores its greater capability in identifying and mitigating threats within 5.39 dB, a commendable SNR ratio. Furthermore, neuromorphic computing and hardware security serve many sensor domains in mission-critical and privacy-preserving applications.
HPCNeuroNet: Advancing Neuromorphic Audio Signal Processing with Transformer-Enhanced Spiking Neural Networks
Nov 21, 2023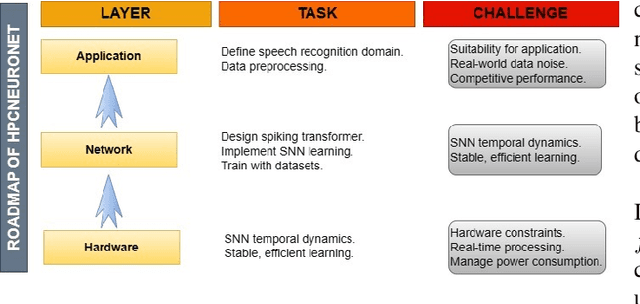
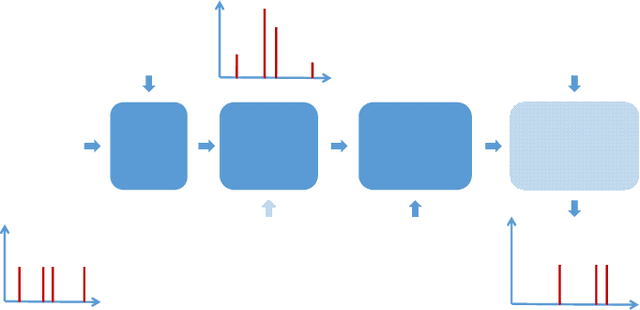
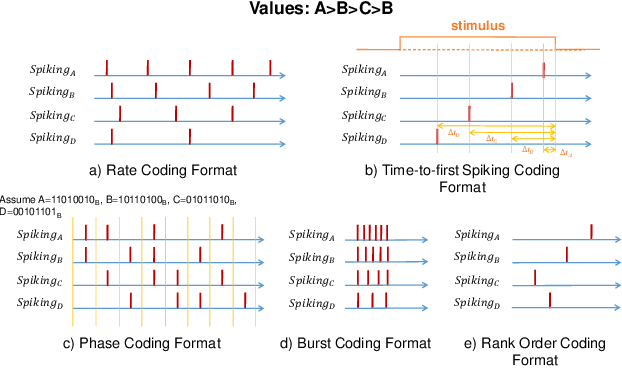
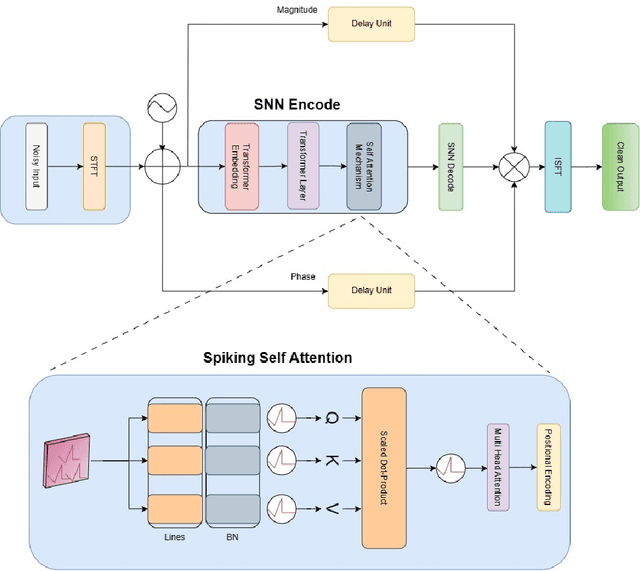
This paper presents a novel approach to neuromorphic audio processing by integrating the strengths of Spiking Neural Networks (SNNs), Transformers, and high-performance computing (HPC) into the HPCNeuroNet architecture. Utilizing the Intel N-DNS dataset, we demonstrate the system's capability to process diverse human vocal recordings across multiple languages and noise backgrounds. The core of our approach lies in the fusion of the temporal dynamics of SNNs with the attention mechanisms of Transformers, enabling the model to capture intricate audio patterns and relationships. Our architecture, HPCNeuroNet, employs the Short-Time Fourier Transform (STFT) for time-frequency representation, Transformer embeddings for dense vector generation, and SNN encoding/decoding mechanisms for spike train conversions. The system's performance is further enhanced by leveraging the computational capabilities of NVIDIA's GeForce RTX 3060 GPU and Intel's Core i9 12900H CPU. Additionally, we introduce a hardware implementation on the Xilinx VU37P HBM FPGA platform, optimizing for energy efficiency and real-time processing. The proposed accelerator achieves a throughput of 71.11 Giga-Operations Per Second (GOP/s) with a 3.55 W on-chip power consumption at 100 MHz. The comparison results with off-the-shelf devices and recent state-of-the-art implementations illustrate that the proposed accelerator has obvious advantages in terms of energy efficiency and design flexibility. Through design-space exploration, we provide insights into optimizing core capacities for audio tasks. Our findings underscore the transformative potential of integrating SNNs, Transformers, and HPC for neuromorphic audio processing, setting a new benchmark for future research and applications.
Harnessing FPGA Technology for Enhanced Biomedical Computation
Nov 21, 2023



This research delves into sophisticated neural network frameworks like Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Long Short-Term Memory Networks (LSTMs), and Deep Belief Networks (DBNs) for improved analysis of ECG signals via Field Programmable Gate Arrays (FPGAs). The MIT-BIH Arrhythmia Database serves as the foundation for training and evaluating our models, with added Gaussian noise to heighten the algorithms' resilience. The developed architectures incorporate various layers for specific processing and categorization functions, employing strategies such as the EarlyStopping callback and Dropout layer to prevent overfitting. Additionally, this paper details the creation of a tailored Tensor Compute Unit (TCU) accelerator for the PYNQ Z1 platform. It provides a thorough methodology for implementing FPGA-based machine learning, encompassing the configuration of the Tensil toolchain in Docker, selection of architectures, PS-PL configuration, and the compilation and deployment of models. By evaluating performance indicators like latency and throughput, we showcase the efficacy of FPGAs in advanced biomedical computing. This study ultimately serves as a comprehensive guide to optimizing neural network operations on FPGAs across various fields.
Astrocyte-Integrated Dynamic Function Exchange in Spiking Neural Networks
Sep 15, 2023



This paper presents an innovative methodology for improving the robustness and computational efficiency of Spiking Neural Networks (SNNs), a critical component in neuromorphic computing. The proposed approach integrates astrocytes, a type of glial cell prevalent in the human brain, into SNNs, creating astrocyte-augmented networks. To achieve this, we designed and implemented an astrocyte model in two distinct platforms: CPU/GPU and FPGA. Our FPGA implementation notably utilizes Dynamic Function Exchange (DFX) technology, enabling real-time hardware reconfiguration and adaptive model creation based on current operating conditions. The novel approach of leveraging astrocytes significantly improves the fault tolerance of SNNs, thereby enhancing their robustness. Notably, our astrocyte-augmented SNN displays near-zero latency and theoretically infinite throughput, implying exceptional computational efficiency. Through comprehensive comparative analysis with prior works, it's established that our model surpasses others in terms of neuron and synapse count while maintaining an efficient power consumption profile. These results underscore the potential of our methodology in shaping the future of neuromorphic computing, by providing robust and energy-efficient systems.
Exploiting FPGA Capabilities for Accelerated Biomedical Computing
Jul 16, 2023

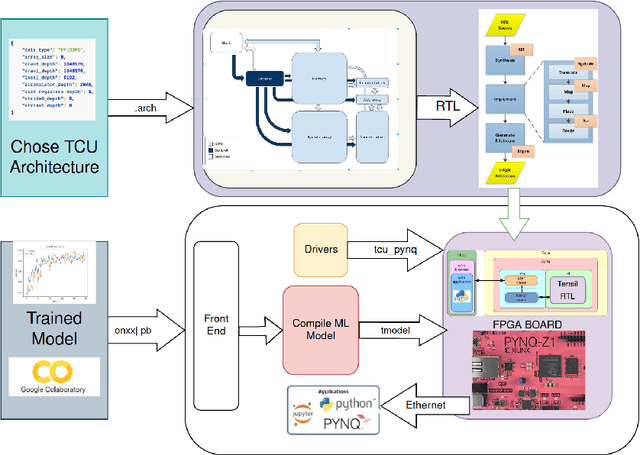

This study presents advanced neural network architectures including Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Long Short-Term Memory Networks (LSTMs), and Deep Belief Networks (DBNs) for enhanced ECG signal analysis using Field Programmable Gate Arrays (FPGAs). We utilize the MIT-BIH Arrhythmia Database for training and validation, introducing Gaussian noise to improve algorithm robustness. The implemented models feature various layers for distinct processing and classification tasks and techniques like EarlyStopping callback and Dropout layer are used to mitigate overfitting. Our work also explores the development of a custom Tensor Compute Unit (TCU) accelerator for the PYNQ Z1 board, offering comprehensive steps for FPGA-based machine learning, including setting up the Tensil toolchain in Docker, selecting architecture, configuring PS-PL, and compiling and executing models. Performance metrics such as latency and throughput are calculated for practical insights, demonstrating the potential of FPGAs in high-performance biomedical computing. The study ultimately offers a guide for optimizing neural network performance on FPGAs for various applications.
Design optimization for high-performance computing using FPGA
Apr 24, 2023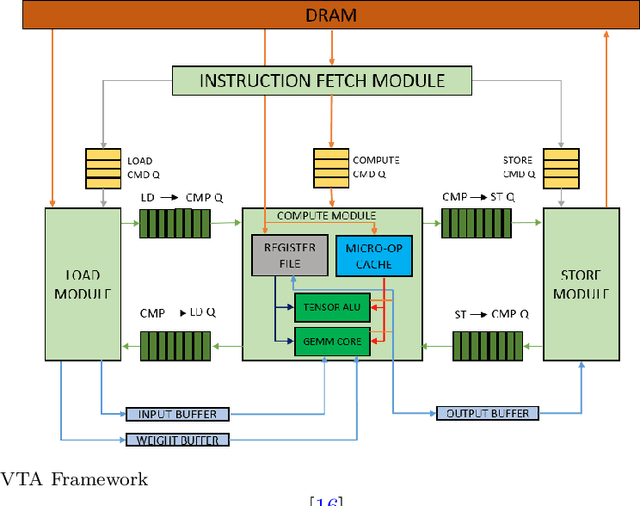
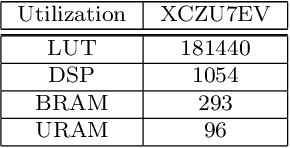
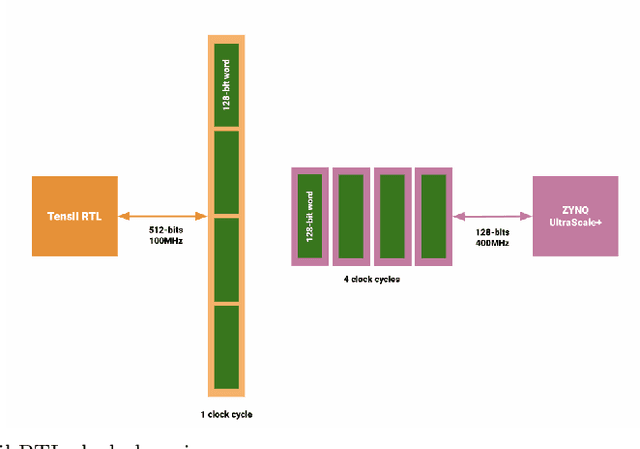
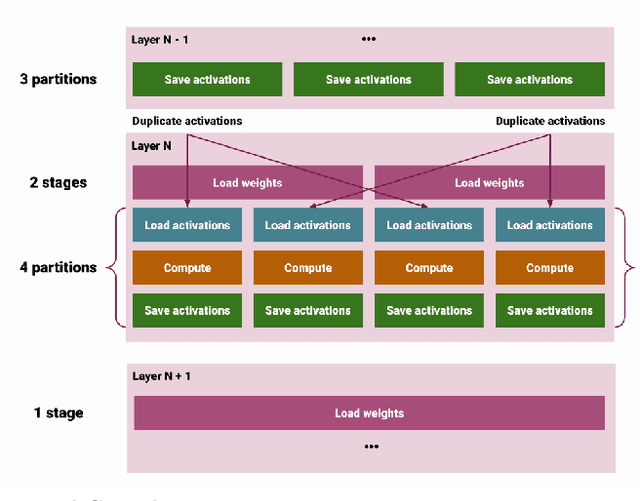
Reconfigurable architectures like Field Programmable Gate Arrays (FPGAs) have been used for accelerating computations in several domains because of their unique combination of flexibility, performance, and power efficiency. However, FPGAs have not been widely used for high-performance computing, primarily because of their programming complexity and difficulties in optimizing performance. We optimize Tensil AI's open-source inference accelerator for maximum performance using ResNet20 trained on CIFAR in this paper in order to gain insight into the use of FPGAs for high-performance computing. In this paper, we show how improving hardware design, using Xilinx Ultra RAM, and using advanced compiler strategies can lead to improved inference performance. We also demonstrate that running the CIFAR test data set shows very little accuracy drop when rounding down from the original 32-bit floating point. The heterogeneous computing model in our platform allows us to achieve a frame rate of 293.58 frames per second (FPS) and a %90 accuracy on a ResNet20 trained using CIFAR. The experimental results show that the proposed accelerator achieves a throughput of 21.12 Giga-Operations Per Second (GOP/s) with a 5.21 W on-chip power consumption at 100 MHz. The comparison results with off-the-shelf devices and recent state-of-the-art implementations illustrate that the proposed accelerator has obvious advantages in terms of energy efficiency.