 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHPCNeuroNet: Advancing Neuromorphic Audio Signal Processing with Transformer-Enhanced Spiking Neural Networks
Paper and Code
Nov 21, 2023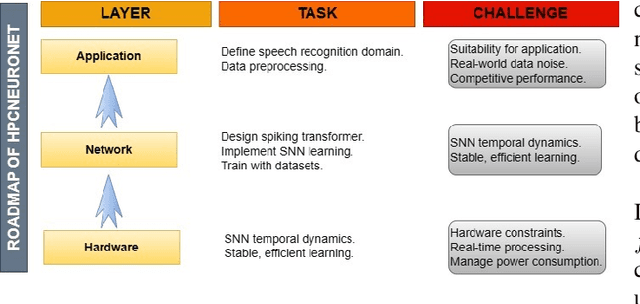
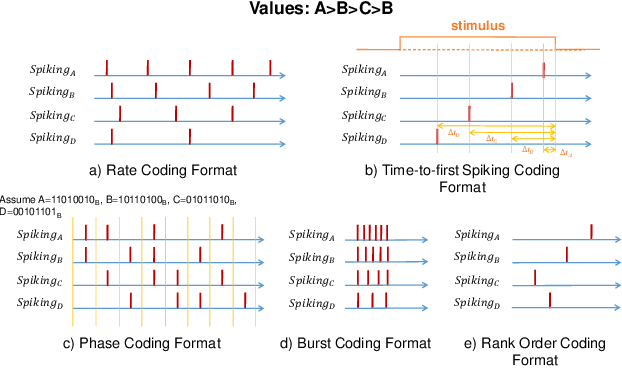
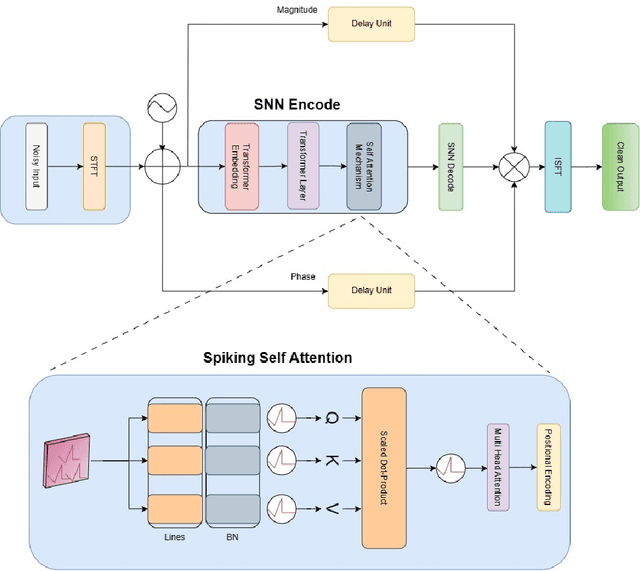
This paper presents a novel approach to neuromorphic audio processing by integrating the strengths of Spiking Neural Networks (SNNs), Transformers, and high-performance computing (HPC) into the HPCNeuroNet architecture. Utilizing the Intel N-DNS dataset, we demonstrate the system's capability to process diverse human vocal recordings across multiple languages and noise backgrounds. The core of our approach lies in the fusion of the temporal dynamics of SNNs with the attention mechanisms of Transformers, enabling the model to capture intricate audio patterns and relationships. Our architecture, HPCNeuroNet, employs the Short-Time Fourier Transform (STFT) for time-frequency representation, Transformer embeddings for dense vector generation, and SNN encoding/decoding mechanisms for spike train conversions. The system's performance is further enhanced by leveraging the computational capabilities of NVIDIA's GeForce RTX 3060 GPU and Intel's Core i9 12900H CPU. Additionally, we introduce a hardware implementation on the Xilinx VU37P HBM FPGA platform, optimizing for energy efficiency and real-time processing. The proposed accelerator achieves a throughput of 71.11 Giga-Operations Per Second (GOP/s) with a 3.55 W on-chip power consumption at 100 MHz. The comparison results with off-the-shelf devices and recent state-of-the-art implementations illustrate that the proposed accelerator has obvious advantages in terms of energy efficiency and design flexibility. Through design-space exploration, we provide insights into optimizing core capacities for audio tasks. Our findings underscore the transformative potential of integrating SNNs, Transformers, and HPC for neuromorphic audio processing, setting a new benchmark for future research and applications.