 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphic Circuits with Spiking Astrocytes for Increased Energy Efficiency, Fault Tolerance, and Memory Capacitance
Feb 27, 2025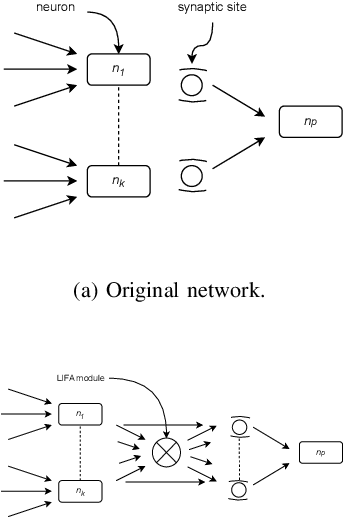
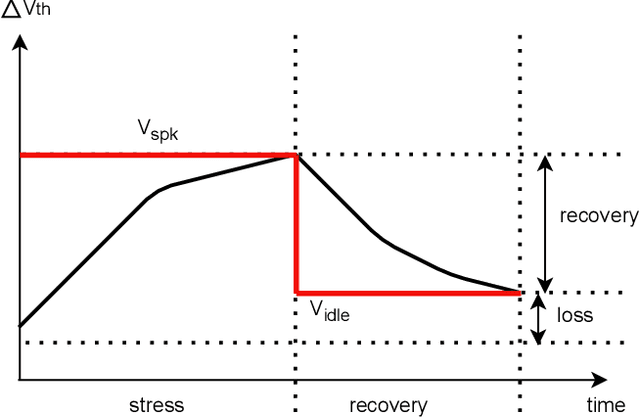
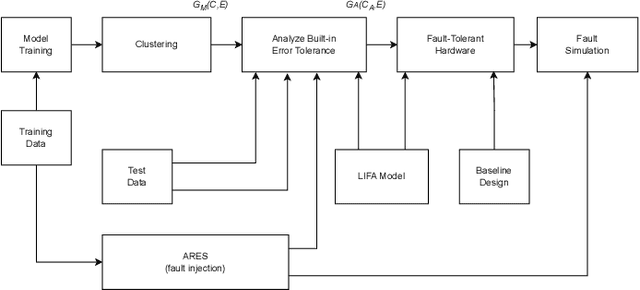
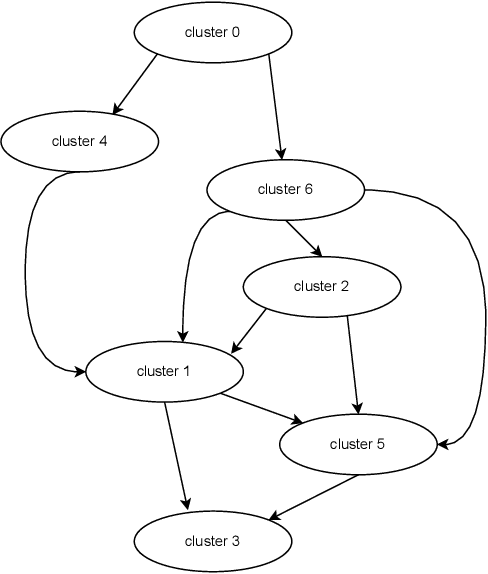
In the rapidly advancing field of neuromorphic computing, integrating biologically-inspired models like the Leaky Integrate-and-Fire Astrocyte (LIFA) into spiking neural networks (SNNs) enhances system robustness and performance. This paper introduces the LIFA model in SNNs, addressing energy efficiency, memory management, routing mechanisms, and fault tolerance. Our core architecture consists of neurons, synapses, and astrocyte circuits, with each astrocyte supporting multiple neurons for self-repair. This clustered model improves fault tolerance and operational efficiency, especially under adverse conditions. We developed a routing methodology to map the LIFA model onto a fault-tolerant, many-core design, optimizing network functionality and efficiency. Our model features a fault tolerance rate of 81.10\% and a resilience improvement rate of 18.90\%, significantly surpassing other implementations. The results validate our approach in memory management, highlighting its potential as a robust solution for advanced neuromorphic computing applications. The integration of astrocytes represents a significant advancement, setting the stage for more resilient and adaptable neuromorphic systems.
Battery State of Health Estimation Using LLM Framework
Jan 30, 2025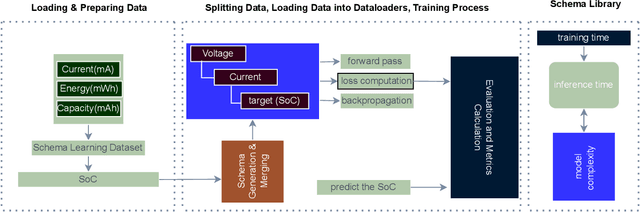
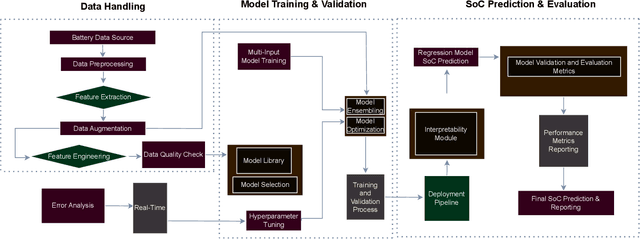
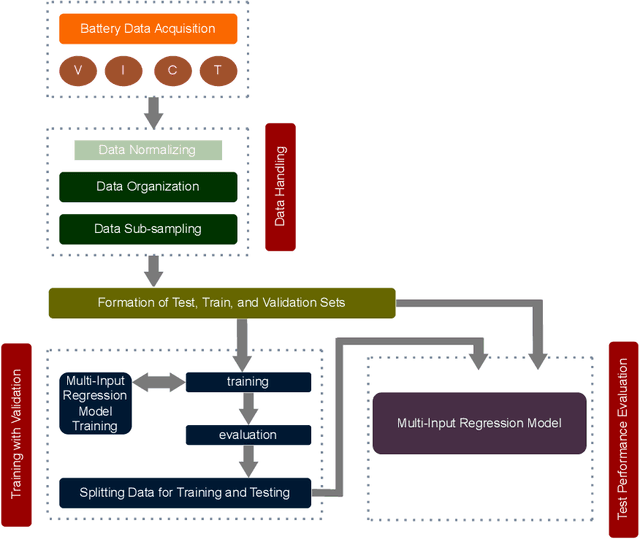
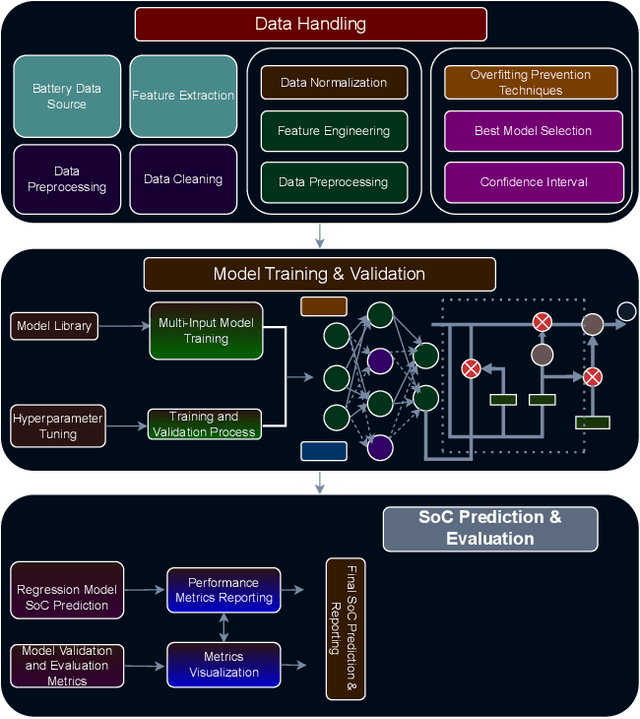
Battery health monitoring is critical for the efficient and reliable operation of electric vehicles (EVs). This study introduces a transformer-based framework for estimating the State of Health (SoH) and predicting the Remaining Useful Life (RUL) of lithium titanate (LTO) battery cells by utilizing both cycle-based and instantaneous discharge data. Testing on eight LTO cells under various cycling conditions over 500 cycles, we demonstrate the impact of charge durations on energy storage trends and apply Differential Voltage Analysis (DVA) to monitor capacity changes (dQ/dV) across voltage ranges. Our LLM model achieves superior performance, with a Mean Absolute Error (MAE) as low as 0.87\% and varied latency metrics that support efficient processing, demonstrating its strong potential for real-time integration into EVs. The framework effectively identifies early signs of degradation through anomaly detection in high-resolution data, facilitating predictive maintenance to prevent sudden battery failures and enhance energy efficiency.
HPCNeuroNet: A Neuromorphic Approach Merging SNN Temporal Dynamics with Transformer Attention for FPGA-based Particle Physics
Dec 23, 2024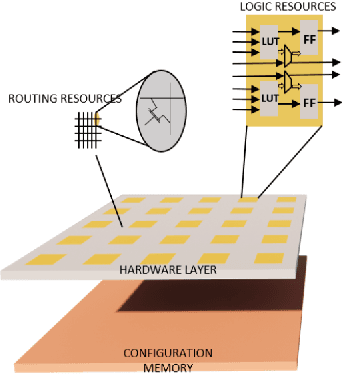

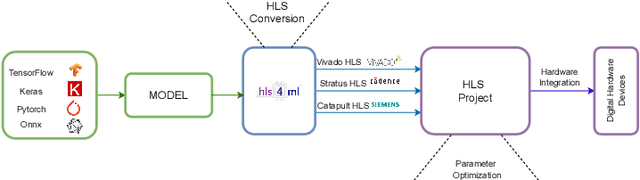
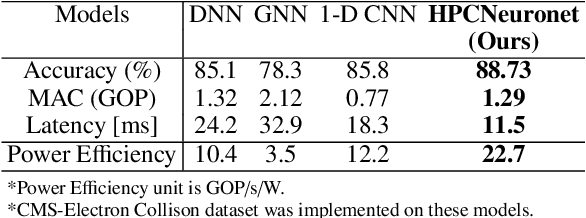
This paper presents the innovative HPCNeuroNet model, a pioneering fusion of Spiking Neural Networks (SNNs), Transformers, and high-performance computing tailored for particle physics, particularly in particle identification from detector responses. Our approach leverages SNNs' intrinsic temporal dynamics and Transformers' robust attention mechanisms to enhance performance when discerning intricate particle interactions. At the heart of HPCNeuroNet lies the integration of the sequential dynamism inherent in SNNs with the context-aware attention capabilities of Transformers, enabling the model to precisely decode and interpret complex detector data. HPCNeuroNet is realized through the HLS4ML framework and optimized for deployment in FPGA environments. The model accuracy and scalability are also enhanced by this architectural choice. Benchmarked against machine learning models, HPCNeuroNet showcases better performance metrics, underlining its transformative potential in high-energy physics. We demonstrate that the combination of SNNs, Transformers, and FPGA-based high-performance computing in particle physics signifies a significant step forward and provides a strong foundation for future research.
Multimodal LLM for Intelligent Transportation Systems
Dec 16, 2024



In the evolving landscape of transportation systems, integrating Large Language Models (LLMs) offers a promising frontier for advancing intelligent decision-making across various applications. This paper introduces a novel 3-dimensional framework that encapsulates the intersection of applications, machine learning methodologies, and hardware devices, particularly emphasizing the role of LLMs. Instead of using multiple machine learning algorithms, our framework uses a single, data-centric LLM architecture that can analyze time series, images, and videos. We explore how LLMs can enhance data interpretation and decision-making in transportation. We apply this LLM framework to different sensor datasets, including time-series data and visual data from sources like Oxford Radar RobotCar, D-Behavior (D-Set), nuScenes by Motional, and Comma2k19. The goal is to streamline data processing workflows, reduce the complexity of deploying multiple models, and make intelligent transportation systems more efficient and accurate. The study was conducted using state-of-the-art hardware, leveraging the computational power of AMD RTX 3060 GPUs and Intel i9-12900 processors. The experimental results demonstrate that our framework achieves an average accuracy of 91.33\% across these datasets, with the highest accuracy observed in time-series data (92.7\%), showcasing the model's proficiency in handling sequential information essential for tasks such as motion planning and predictive maintenance. Through our exploration, we demonstrate the versatility and efficacy of LLMs in handling multimodal data within the transportation sector, ultimately providing insights into their application in real-world scenarios. Our findings align with the broader conference themes, highlighting the transformative potential of LLMs in advancing transportation technologies.
NEUROSEC: FPGA-Based Neuromorphic Audio Security
Jan 22, 2024
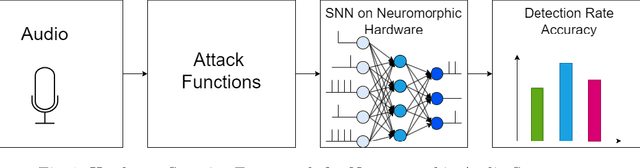
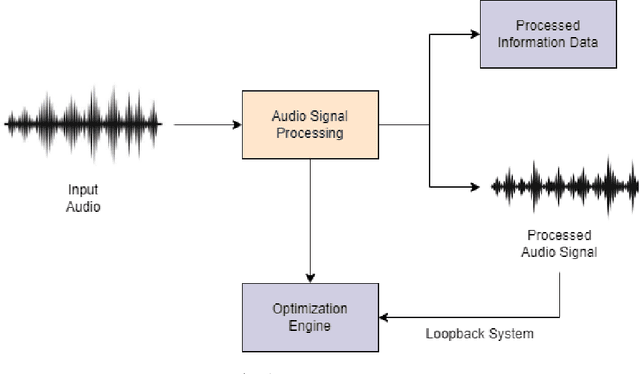
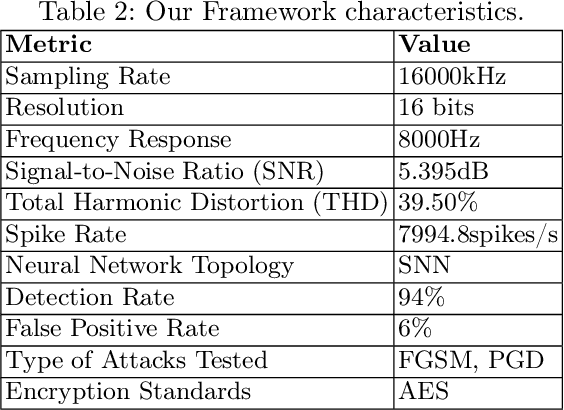
Neuromorphic systems, inspired by the complexity and functionality of the human brain, have gained interest in academic and industrial attention due to their unparalleled potential across a wide range of applications. While their capabilities herald innovation, it is imperative to underscore that these computational paradigms, analogous to their traditional counterparts, are not impervious to security threats. Although the exploration of neuromorphic methodologies for image and video processing has been rigorously pursued, the realm of neuromorphic audio processing remains in its early stages. Our results highlight the robustness and precision of our FPGA-based neuromorphic system. Specifically, our system showcases a commendable balance between desired signal and background noise, efficient spike rate encoding, and unparalleled resilience against adversarial attacks such as FGSM and PGD. A standout feature of our framework is its detection rate of 94%, which, when compared to other methodologies, underscores its greater capability in identifying and mitigating threats within 5.39 dB, a commendable SNR ratio. Furthermore, neuromorphic computing and hardware security serve many sensor domains in mission-critical and privacy-preserving applications.
HPCNeuroNet: Advancing Neuromorphic Audio Signal Processing with Transformer-Enhanced Spiking Neural Networks
Nov 21, 2023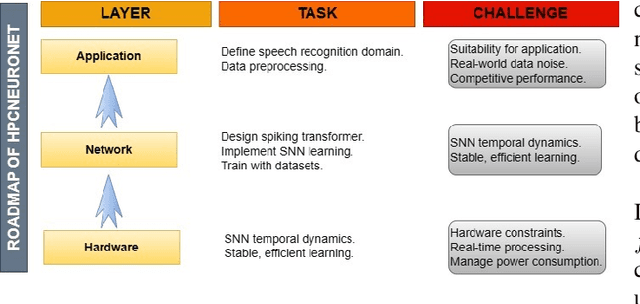
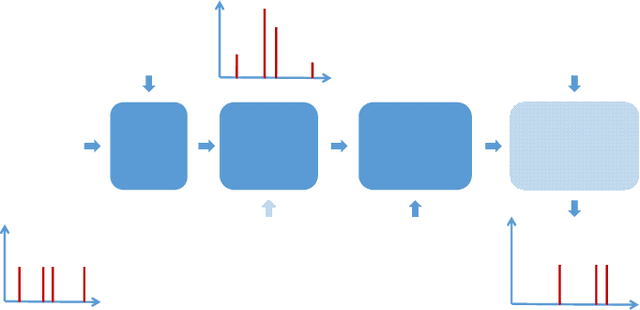
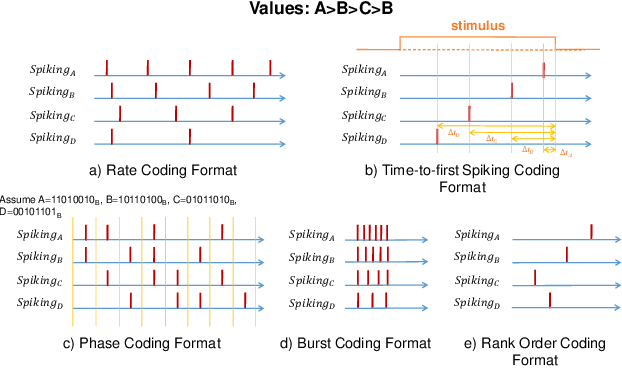
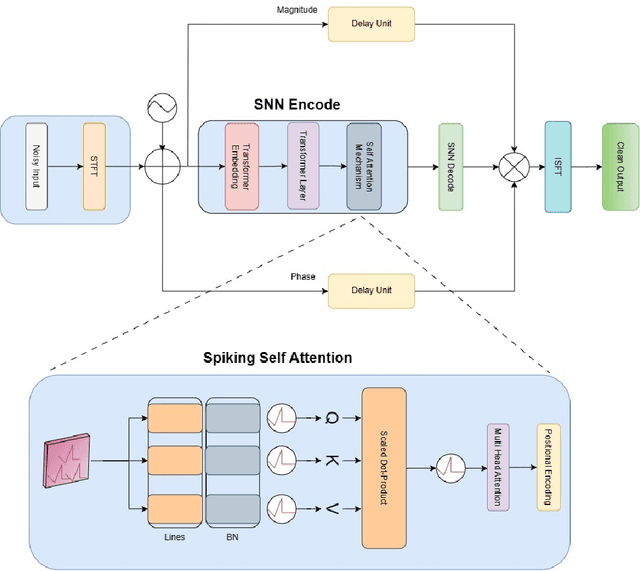
This paper presents a novel approach to neuromorphic audio processing by integrating the strengths of Spiking Neural Networks (SNNs), Transformers, and high-performance computing (HPC) into the HPCNeuroNet architecture. Utilizing the Intel N-DNS dataset, we demonstrate the system's capability to process diverse human vocal recordings across multiple languages and noise backgrounds. The core of our approach lies in the fusion of the temporal dynamics of SNNs with the attention mechanisms of Transformers, enabling the model to capture intricate audio patterns and relationships. Our architecture, HPCNeuroNet, employs the Short-Time Fourier Transform (STFT) for time-frequency representation, Transformer embeddings for dense vector generation, and SNN encoding/decoding mechanisms for spike train conversions. The system's performance is further enhanced by leveraging the computational capabilities of NVIDIA's GeForce RTX 3060 GPU and Intel's Core i9 12900H CPU. Additionally, we introduce a hardware implementation on the Xilinx VU37P HBM FPGA platform, optimizing for energy efficiency and real-time processing. The proposed accelerator achieves a throughput of 71.11 Giga-Operations Per Second (GOP/s) with a 3.55 W on-chip power consumption at 100 MHz. The comparison results with off-the-shelf devices and recent state-of-the-art implementations illustrate that the proposed accelerator has obvious advantages in terms of energy efficiency and design flexibility. Through design-space exploration, we provide insights into optimizing core capacities for audio tasks. Our findings underscore the transformative potential of integrating SNNs, Transformers, and HPC for neuromorphic audio processing, setting a new benchmark for future research and applications.