 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Weighted Learning Progress Guided Interleaved Multi-Task Learning
Apr 01, 2025Humans can continuously acquire new skills and knowledge by exploiting existing ones for improved learning, without forgetting them. Similarly, 'continual learning' in machine learning aims to learn new information while preserving the previously acquired knowledge. Existing research often overlooks the nature of human learning, where tasks are interleaved due to human choice or environmental constraints. So, almost never do humans master one task before switching to the next. To investigate to what extent human-like learning can benefit the learner, we propose a method that interleaves tasks based on their 'learning progress' and energy consumption. From a machine learning perspective, our approach can be seen as a multi-task learning system that balances learning performance with energy constraints while mimicking ecologically realistic human task learning. To assess the validity of our approach, we consider a robot learning setting in simulation, where the robot learns the effect of its actions in different contexts. The conducted experiments show that our proposed method achieves better performance than sequential task learning and reduces energy consumption for learning the tasks.
TransAdapter: Vision Transformer for Feature-Centric Unsupervised Domain Adaptation
Dec 05, 2024



Unsupervised Domain Adaptation (UDA) aims to utilize labeled data from a source domain to solve tasks in an unlabeled target domain, often hindered by significant domain gaps. Traditional CNN-based methods struggle to fully capture complex domain relationships, motivating the shift to vision transformers like the Swin Transformer, which excel in modeling both local and global dependencies. In this work, we propose a novel UDA approach leveraging the Swin Transformer with three key modules. A Graph Domain Discriminator enhances domain alignment by capturing inter-pixel correlations through graph convolutions and entropy-based attention differentiation. An Adaptive Double Attention module combines Windows and Shifted Windows attention with dynamic reweighting to align long-range and local features effectively. Finally, a Cross-Feature Transform modifies Swin Transformer blocks to improve generalization across domains. Extensive benchmarks confirm the state-of-the-art performance of our versatile method, which requires no task-specific alignment modules, establishing its adaptability to diverse applications.
Sample Efficient Robot Learning in Supervised Effect Prediction Tasks
Dec 03, 2024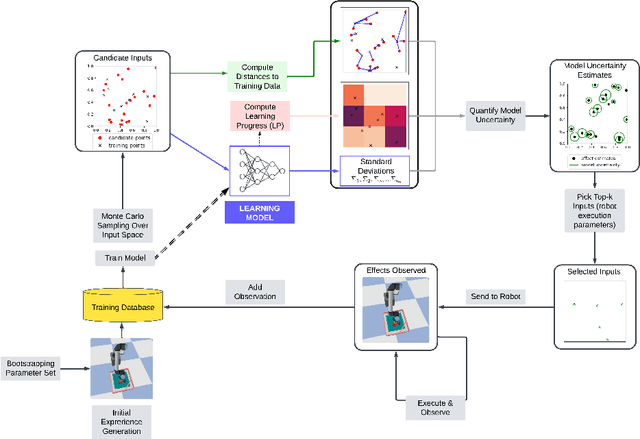
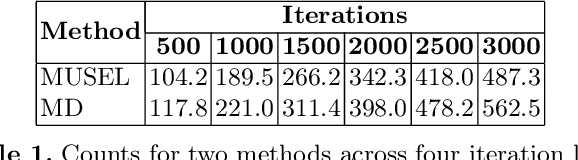

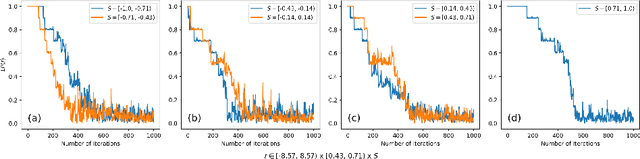
In self-supervised robot learning, robots actively explore their environments and generate data by acting on entities in the environment. Therefore, an exploration policy is desired that ensures sample efficiency to minimize robot execution costs while still providing accurate learning. For this purpose, the robotic community has adopted Intrinsic Motivation (IM)-based approaches such as Learning Progress (LP). On the machine learning front, Active Learning (AL) has been used successfully, especially for classification tasks. In this work, we develop a novel AL framework geared towards robotics regression tasks, such as action-effect prediction and, more generally, for world model learning, which we call MUSEL - Model Uncertainty for Sample Efficient Learning. MUSEL aims to extract model uncertainty from the total uncertainty estimate given by a suitable learning engine by making use of earning progress and input diversity and use it to improve sample efficiency beyond the state-of-the-art action-effect prediction methods. We demonstrate the feasibility of our model by using a Stochastic Variational Gaussian Process (SVGP) as the learning engine and testing the system on a set of robotic experiments in simulation. The efficacy of MUSEL is demonstrated by comparing its performance to standard methods used in robot action-effect learning. In a robotic tabletop environment in which a robot manipulator is tasked with learning the effect of its actions, the experiments show that MUSEL facilitates higher accuracy in learning action effects while ensuring sample efficiency.
Context-Based Echo State Networks with Prediction Confidence for Human-Robot Shared Control
Nov 30, 2024



In this paper, we propose a novel lightweight learning from demonstration (LfD) model based on reservoir computing that can learn and generate multiple movement trajectories with prediction intervals, which we call as Context-based Echo State Network with prediction confidence (CESN+). CESN+ can generate movement trajectories that may go beyond the initial LfD training based on a desired set of conditions while providing confidence on its generated output. To assess the abilities of CESN+, we first evaluate its performance against Conditional Neural Movement Primitives (CNMP), a comparable framework that uses a conditional neural process to generate movement primitives. Our findings indicate that CESN+ not only outperforms CNMP but is also faster to train and demonstrates impressive performance in generating trajectories for extrapolation cases. In human-robot shared control applications, the confidence of the machine generated trajectory is a key indicator of how to arbitrate control sharing. To show the usability of the CESN+ for human-robot adaptive shared control, we have designed a proof-of-concept human-robot shared control task and tested its efficacy in adapting the sharing weight between the human and the robot by comparing it to a fixed-weight control scheme. The simulation experiments show that with CESN+ based adaptive sharing the total human load in shared control can be significantly reduced. Overall, the developed CESN+ model is a strong lightweight LfD system with desirable properties such fast training and ability to extrapolate to the new task parameters while producing robust prediction intervals for its output.
Modulating Reservoir Dynamics via Reinforcement Learning for Efficient Robot Skill Synthesis
Nov 17, 2024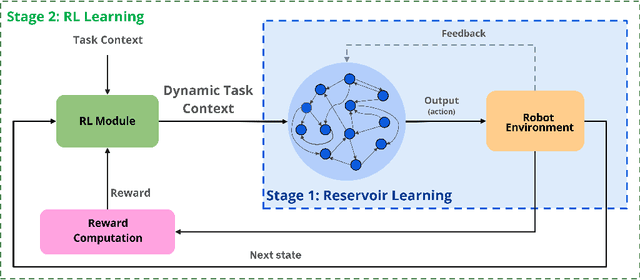


A random recurrent neural network, called a reservoir, can be used to learn robot movements conditioned on context inputs that encode task goals. The Learning is achieved by mapping the random dynamics of the reservoir modulated by context to desired trajectories via linear regression. This makes the reservoir computing (RC) approach computationally efficient as no iterative gradient descent learning is needed. In this work, we propose a novel RC-based Learning from Demonstration (LfD) framework that not only learns to generate the demonstrated movements but also allows online modulation of the reservoir dynamics to generate movement trajectories that are not covered by the initial demonstration set. This is made possible by using a Reinforcement Learning (RL) module that learns a policy to output context as its actions based on the robot state. Considering that the context dimension is typically low, learning with the RL module is very efficient. We show the validity of the proposed model with systematic experiments on a 2 degrees-of-freedom (DOF) simulated robot that is taught to reach targets, encoded as context, with and without obstacle avoidance constraint. The initial data set includes a set of reaching demonstrations which are learned by the reservoir system. To enable reaching out-of-distribution targets, the RL module is engaged in learning a policy to generate dynamic contexts so that the generated trajectory achieves the desired goal without any learning in the reservoir system. Overall, the proposed model uses an initial learned motor primitive set to efficiently generate diverse motor behaviors guided by the designed reward function. Thus the model can be used as a flexible and effective LfD system where the action repertoire can be extended without new data collection.
Learning secondary tool affordances of human partners using iCub robot's egocentric data
Jul 16, 2024



Objects, in particular tools, provide several action possibilities to the agents that can act on them, which are generally associated with the term of affordances. A tool is typically designed for a specific purpose, such as driving a nail in the case of a hammer, which we call as the primary affordance. A tool can also be used beyond its primary purpose, in which case we can associate this auxiliary use with the term secondary affordance. Previous work on affordance perception and learning has been mostly focused on primary affordances. Here, we address the less explored problem of learning the secondary tool affordances of human partners. To do this, we use the iCub robot to observe human partners with three cameras while they perform actions on twenty objects using four different tools. In our experiments, human partners utilize tools to perform actions that do not correspond to their primary affordances. For example, the iCub robot observes a human partner using a ruler for pushing, pulling, and moving objects instead of measuring their lengths. In this setting, we constructed a dataset by taking images of objects before and after each action is executed. We then model learning secondary affordances by training three neural networks (ResNet-18, ResNet-50, and ResNet-101) each on three tasks, using raw images showing the `initial' and `final' position of objects as input: (1) predicting the tool used to move an object, (2) predicting the tool used with an additional categorical input that encoded the action performed, and (3) joint prediction of both tool used and action performed. Our results indicate that deep learning architectures enable the iCub robot to predict secondary tool affordances, thereby paving the road for human-robot collaborative object manipulation involving complex affordances.
Affordance Blending Networks
Apr 24, 2024



Affordances, a concept rooted in ecological psychology and pioneered by James J. Gibson, have emerged as a fundamental framework for understanding the dynamic relationship between individuals and their environments. Expanding beyond traditional perceptual and cognitive paradigms, affordances represent the inherent effect and action possibilities that objects offer to the agents within a given context. As a theoretical lens, affordances bridge the gap between effect and action, providing a nuanced understanding of the connections between agents' actions on entities and the effect of these actions. In this study, we propose a model that unifies object, action and effect into a single latent representation in a common latent space that is shared between all affordances that we call the affordance space. Using this affordance space, our system is able to generate effect trajectories when action and object are given and is able to generate action trajectories when effect trajectories and objects are given. In the experiments, we showed that our model does not learn the behavior of each object but it learns the affordance relations shared by the objects that we call equivalences. In addition to simulated experiments, we showed that our model can be used for direct imitation in real world cases. We also propose affordances as a base for Cross Embodiment transfer to link the actions of different robots. Finally, we introduce selective loss as a solution that allows valid outputs to be generated for indeterministic model inputs.
Bidirectional Progressive Neural Networks with Episodic Return Progress for Emergent Task Sequencing and Robotic Skill Transfer
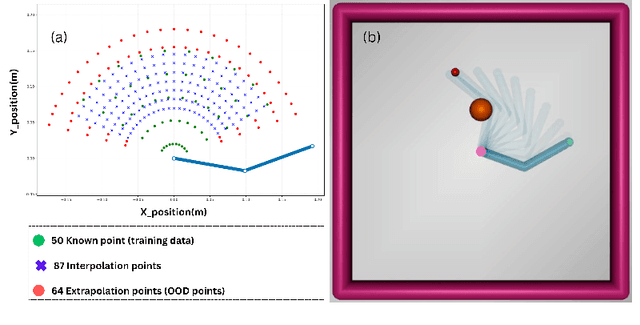
Mar 06, 2024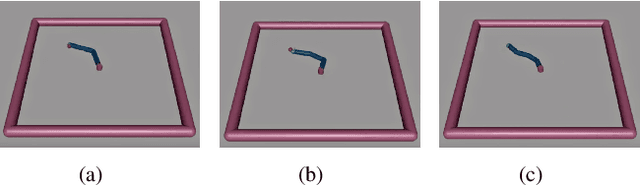
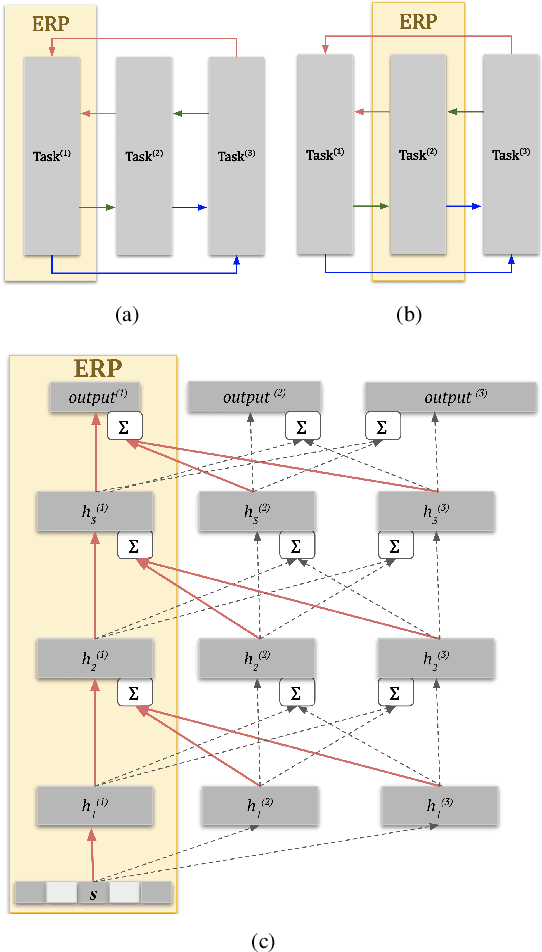
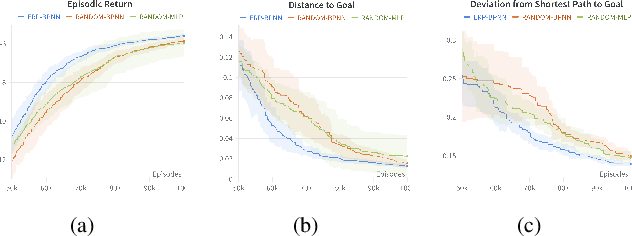

Human brain and behavior provide a rich venue that can inspire novel control and learning methods for robotics. In an attempt to exemplify such a development by inspiring how humans acquire knowledge and transfer skills among tasks, we introduce a novel multi-task reinforcement learning framework named Episodic Return Progress with Bidirectional Progressive Neural Networks (ERP-BPNN). The proposed ERP-BPNN model (1) learns in a human-like interleaved manner by (2) autonomous task switching based on a novel intrinsic motivation signal and, in contrast to existing methods, (3) allows bidirectional skill transfer among tasks. ERP-BPNN is a general architecture applicable to several multi-task learning settings; in this paper, we present the details of its neural architecture and show its ability to enable effective learning and skill transfer among morphologically different robots in a reaching task. The developed Bidirectional Progressive Neural Network (BPNN) architecture enables bidirectional skill transfer without requiring incremental training and seamlessly integrates with online task arbitration. The task arbitration mechanism developed is based on soft Episodic Return progress (ERP), a novel intrinsic motivation (IM) signal. To evaluate our method, we use quantifiable robotics metrics such as 'expected distance to goal' and 'path straightness' in addition to the usual reward-based measure of episodic return common in reinforcement learning. With simulation experiments, we show that ERP-BPNN achieves faster cumulative convergence and improves performance in all metrics considered among morphologically different robots compared to the baselines.
Symbolic Manipulation Planning with Discovered Object and Relational Predicates
Jan 02, 2024



Discovering the symbols and rules that can be used in long-horizon planning from a robot's unsupervised exploration of its environment and continuous sensorimotor experience is a challenging task. The previous studies proposed learning symbols from single or paired object interactions and planning with these symbols. In this work, we propose a system that learns rules with discovered object and relational symbols that encode an arbitrary number of objects and the relations between them, converts those rules to Planning Domain Description Language (PDDL), and generates plans that involve affordances of the arbitrary number of objects to achieve tasks. We validated our system with box-shaped objects in different sizes and showed that the system can develop a symbolic knowledge of pick-up, carry, and place operations, taking into account object compounds in different configurations, such as boxes would be carried together with a larger box that they are placed on. We also compared our method with the state-of-the-art methods and showed that planning with the operators defined over relational symbols gives better planning performance compared to the baselines.
Correspondence learning between morphologically different robots through task demonstrations
Oct 20, 2023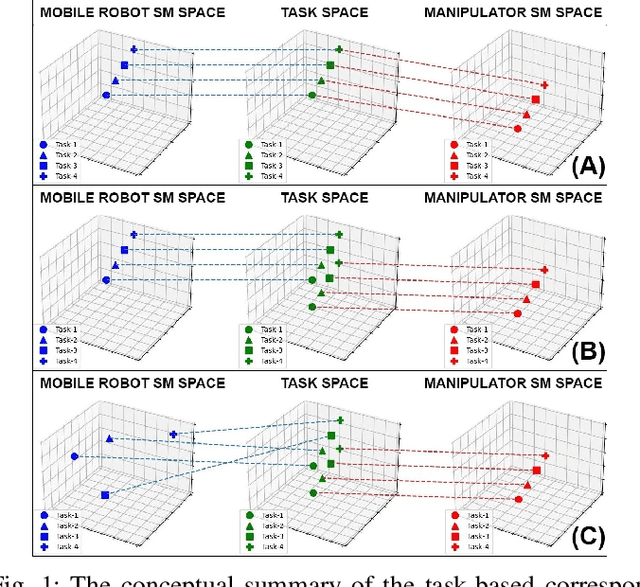
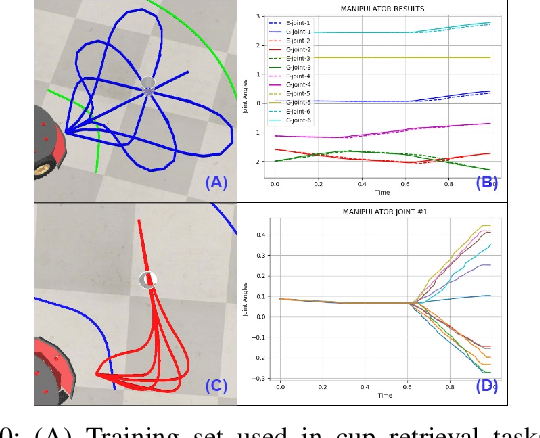
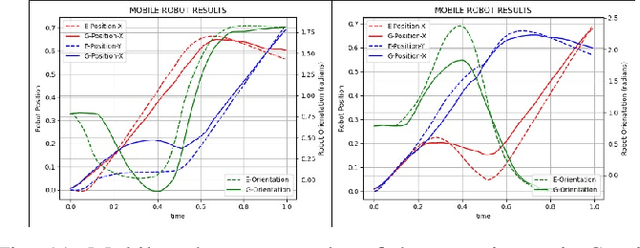
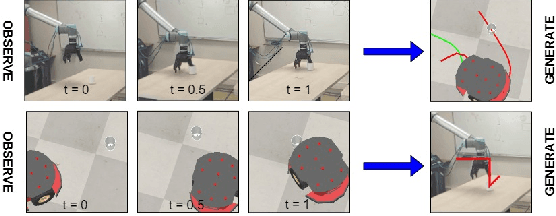
We observe a large variety of robots in terms of their bodies, sensors, and actuators. Given the commonalities in the skill sets, teaching each skill to each different robot independently is inefficient and not scalable when the large variety in the robotic landscape is considered. If we can learn the correspondences between the sensorimotor spaces of different robots, we can expect a skill that is learned in one robot can be more directly and easily transferred to the other robots. In this paper, we propose a method to learn correspondences between robots that have significant differences in their morphologies: a fixed-based manipulator robot with joint control and a differential drive mobile robot. For this, both robots are first given demonstrations that achieve the same tasks. A common latent representation is formed while learning the corresponding policies. After this initial learning stage, the observation of a new task execution by one robot becomes sufficient to generate a latent space representation pertaining to the other robot to achieve the same task. We verified our system in a set of experiments where the correspondence between two simulated robots is learned (1) when the robots need to follow the same paths to achieve the same task, (2) when the robots need to follow different trajectories to achieve the same task, and (3) when complexities of the required sensorimotor trajectories are different for the robots considered. We also provide a proof-of-the-concept realization of correspondence learning between a real manipulator robot and a simulated mobile robot.