 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Meta-Testing with Conditional Neural Processes for Hybrid Meta-Reinforcement Learning
Jun 04, 2025We introduce Unsupervised Meta-Testing with Conditional Neural Processes (UMCNP), a novel hybrid few-shot meta-reinforcement learning (meta-RL) method that uniquely combines, yet distinctly separates, parameterized policy gradient-based (PPG) and task inference-based few-shot meta-RL. Tailored for settings where the reward signal is missing during meta-testing, our method increases sample efficiency without requiring additional samples in meta-training. UMCNP leverages the efficiency and scalability of Conditional Neural Processes (CNPs) to reduce the number of online interactions required in meta-testing. During meta-training, samples previously collected through PPG meta-RL are efficiently reused for learning task inference in an offline manner. UMCNP infers the latent representation of the transition dynamics model from a single test task rollout with unknown parameters. This approach allows us to generate rollouts for self-adaptation by interacting with the learned dynamics model. We demonstrate our method can adapt to an unseen test task using significantly fewer samples during meta-testing than the baselines in 2D-Point Agent and continuous control meta-RL benchmarks, namely, cartpole with unknown angle sensor bias, walker agent with randomized dynamics parameters.
* Published in IEEE Robotics and Automation Letters Volume: 9, Issue: 10, 8427 - 8434, October 2024. 8 pages, 7 figures
Energy Weighted Learning Progress Guided Interleaved Multi-Task Learning
Apr 01, 2025Humans can continuously acquire new skills and knowledge by exploiting existing ones for improved learning, without forgetting them. Similarly, 'continual learning' in machine learning aims to learn new information while preserving the previously acquired knowledge. Existing research often overlooks the nature of human learning, where tasks are interleaved due to human choice or environmental constraints. So, almost never do humans master one task before switching to the next. To investigate to what extent human-like learning can benefit the learner, we propose a method that interleaves tasks based on their 'learning progress' and energy consumption. From a machine learning perspective, our approach can be seen as a multi-task learning system that balances learning performance with energy constraints while mimicking ecologically realistic human task learning. To assess the validity of our approach, we consider a robot learning setting in simulation, where the robot learns the effect of its actions in different contexts. The conducted experiments show that our proposed method achieves better performance than sequential task learning and reduces energy consumption for learning the tasks.
Bidirectional Progressive Neural Networks with Episodic Return Progress for Emergent Task Sequencing and Robotic Skill Transfer
Mar 06, 2024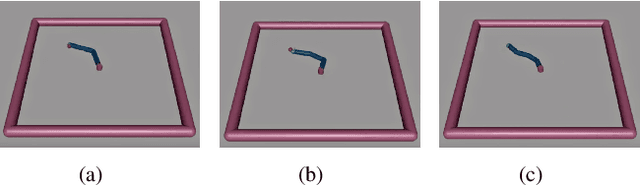
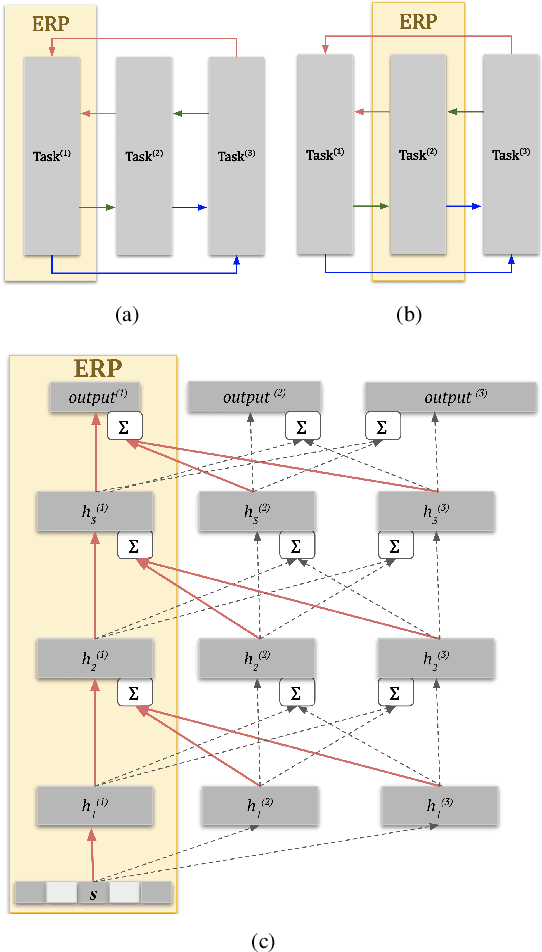
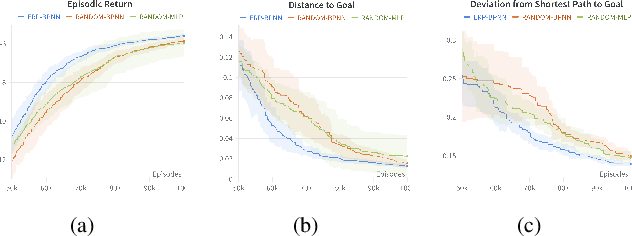

Human brain and behavior provide a rich venue that can inspire novel control and learning methods for robotics. In an attempt to exemplify such a development by inspiring how humans acquire knowledge and transfer skills among tasks, we introduce a novel multi-task reinforcement learning framework named Episodic Return Progress with Bidirectional Progressive Neural Networks (ERP-BPNN). The proposed ERP-BPNN model (1) learns in a human-like interleaved manner by (2) autonomous task switching based on a novel intrinsic motivation signal and, in contrast to existing methods, (3) allows bidirectional skill transfer among tasks. ERP-BPNN is a general architecture applicable to several multi-task learning settings; in this paper, we present the details of its neural architecture and show its ability to enable effective learning and skill transfer among morphologically different robots in a reaching task. The developed Bidirectional Progressive Neural Network (BPNN) architecture enables bidirectional skill transfer without requiring incremental training and seamlessly integrates with online task arbitration. The task arbitration mechanism developed is based on soft Episodic Return progress (ERP), a novel intrinsic motivation (IM) signal. To evaluate our method, we use quantifiable robotics metrics such as 'expected distance to goal' and 'path straightness' in addition to the usual reward-based measure of episodic return common in reinforcement learning. With simulation experiments, we show that ERP-BPNN achieves faster cumulative convergence and improves performance in all metrics considered among morphologically different robots compared to the baselines.
A Reinforcement Learning Based Controller to Minimize Forces on the Crutches of a Lower-Limb Exoskeleton
Jan 31, 2024Metabolic energy consumption of a powered lower-limb exoskeleton user mainly comes from the upper body effort since the lower body is considered to be passive. However, the upper body effort of the users is largely ignored in the literature when designing motion controllers. In this work, we use deep reinforcement learning to develop a locomotion controller that minimizes ground reaction forces (GRF) on crutches. The rationale for minimizing GRF is to reduce the upper body effort of the user. Accordingly, we design a model and a learning framework for a human-exoskeleton system with crutches. We formulate a reward function to encourage the forward displacement of a human-exoskeleton system while satisfying the predetermined constraints of a physical robot. We evaluate our new framework using Proximal Policy Optimization, a state-of-the-art deep reinforcement learning (RL) method, on the MuJoCo physics simulator with different hyperparameters and network architectures over multiple trials. We empirically show that our learning model can generate joint torques based on the joint angle, velocities, and the GRF on the feet and crutch tips. The resulting exoskeleton model can directly generate joint torques from states in line with the RL framework. Finally, we empirically show that policy trained using our method can generate a gait with a 35% reduction in GRF with respect to the baseline.
Diffusion Policies for Out-of-Distribution Generalization in Offline Reinforcement Learning
Jul 10, 2023Offline Reinforcement Learning (RL) methods leverage previous experiences to learn better policies than the behavior policy used for experience collection. In contrast to behavior cloning, which assumes the data is collected from expert demonstrations, offline RL can work with non-expert data and multimodal behavior policies. However, offline RL algorithms face challenges in handling distribution shifts and effectively representing policies due to the lack of online interaction during training. Prior work on offline RL uses conditional diffusion models to obtain expressive policies to represent multimodal behavior in the dataset. Nevertheless, they are not tailored toward alleviating the out-of-distribution state generalization. We introduce a novel method incorporating state reconstruction feature learning in the recent class of diffusion policies to address the out-of-distribution generalization problem. State reconstruction loss promotes more descriptive representation learning of states to alleviate the distribution shift incurred by the out-of-distribution states. We design a 2D Multimodal Contextual Bandit environment to demonstrate and evaluate our proposed model. We assess the performance of our model not only in this new environment but also on several D4RL benchmark tasks, achieving state-of-the-art results.
Meta-World Conditional Neural Processes
Feb 20, 2023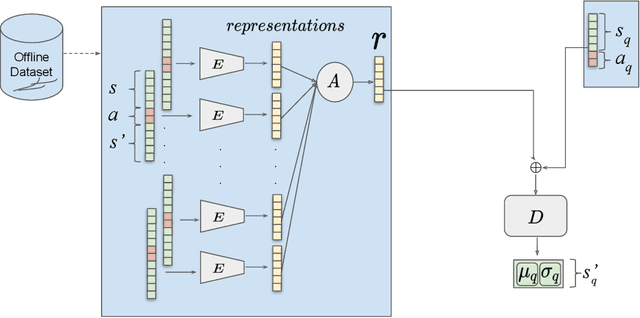
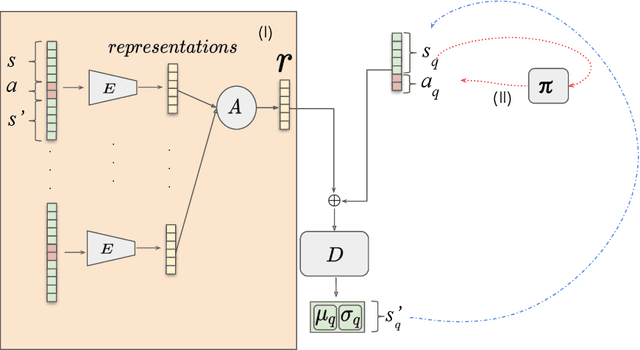
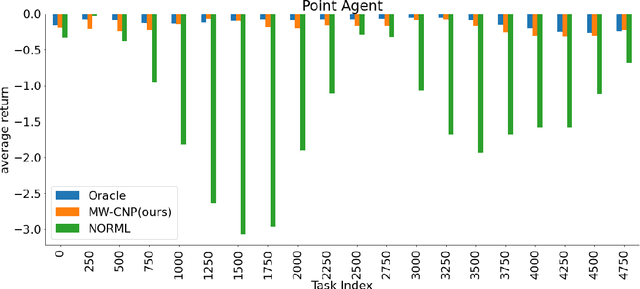
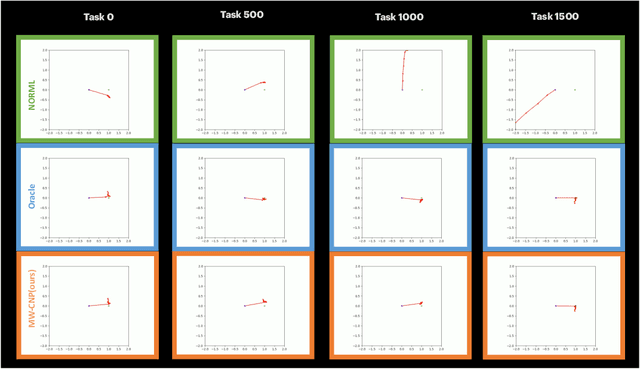
We propose Meta-World Conditional Neural Processes (MW-CNP), a conditional world model generator that leverages sample efficiency and scalability of Conditional Neural Processes to enable an agent to sample from its own "hallucination". We intend to reduce the agent's interaction with the target environment at test time as much as possible. To reduce the number of samples required at test time, we first obtain a latent representation of the transition dynamics from a single rollout from the test environment with hidden parameters. Then, we obtain rollouts for few-shot learning by interacting with the "hallucination" generated by the meta-world model. Using the world model representation from MW-CNP, the meta-RL agent can adapt to an unseen target environment with significantly fewer samples collected from the target environment compared to the baselines. We emphasize that the agent does not have access to the task parameters throughout training and testing, and MW-CNP is trained on offline interaction data logged during meta-training.
Generative Adversarial Networks with Conditional Neural Movement Primitives for An Interactive Generative Drawing Tool
Dec 21, 2021

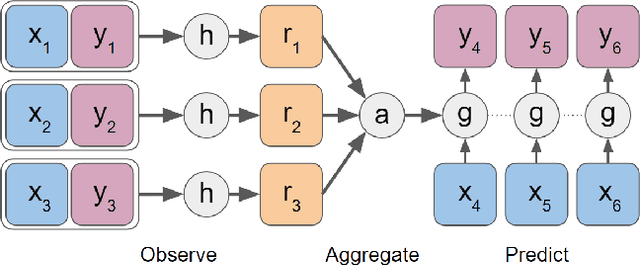
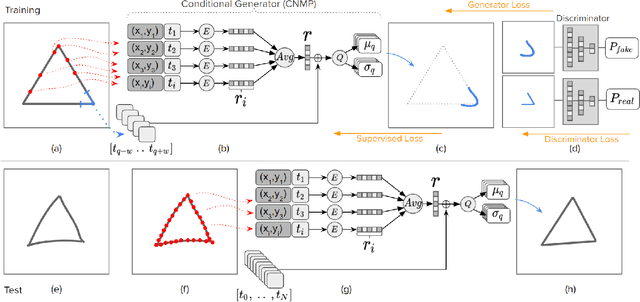
Sketches are abstract representations of visual perception and visuospatial construction. In this work, we proposed a new framework, Generative Adversarial Networks with Conditional Neural Movement Primitives (GAN-CNMP), that incorporates a novel adversarial loss on CNMP to increase sketch smoothness and consistency. Through the experiments, we show that our model can be trained with few unlabeled samples, can construct distributions automatically in the latent space, and produces better results than the base model in terms of shape consistency and smoothness.
Generalization in Transfer Learning
Sep 03, 2019



Agents trained with deep reinforcement learning algorithms are capable of performing highly complex tasks including locomotion in continuous environments. In order to attain a human-level performance, the next step of research should be to investigate the ability to transfer the learning acquired in one task to a different set of tasks. Concerns on generalization and overfitting in deep reinforcement learning are not usually addressed in current transfer learning research. This issue results in underperforming benchmarks and inaccurate algorithm comparisons due to rudimentary assessments. In this study, we primarily propose regularization techniques in deep reinforcement learning for continuous control through the application of sample elimination and early stopping. First, the importance of the inclusion of training iteration to the hyperparameters in deep transfer learning problems will be emphasized. Because source task performance is not indicative of the generalization capacity of the algorithm, we start by proposing various transfer learning evaluation methods that acknowledge the training iteration as a hyperparameter. In line with this, we introduce an additional step of resorting to earlier snapshots of policy parameters depending on the target task due to overfitting to the source task. Then, in order to generate robust policies,we discard the samples that lead to overfitting via strict clipping. Furthermore, we increase the generalization capacity in widely used transfer learning benchmarks by using entropy bonus, different critic methods and curriculum learning in an adversarial setup. Finally, we evaluate the robustness of these techniques and algorithms on simulated robots in target environments where the morphology of the robot, gravity and tangential friction of the environment are altered from the source environment.