 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Task Axes: Zero-Shot Semantic Skill Generalization via Task-Axis Controllers and Visual Foundation Models
May 16, 2025Transferring skills between different objects remains one of the core challenges of open-world robot manipulation. Generalization needs to take into account the high-level structural differences between distinct objects while still maintaining similar low-level interaction control. In this paper, we propose an example-based zero-shot approach to skill transfer. Rather than treating skills as atomic, we decompose skills into a prioritized list of grounded task-axis (GTA) controllers. Each GTAC defines an adaptable controller, such as a position or force controller, along an axis. Importantly, the GTACs are grounded in object key points and axes, e.g., the relative position of a screw head or the axis of its shaft. Zero-shot transfer is thus achieved by finding semantically-similar grounding features on novel target objects. We achieve this example-based grounding of the skills through the use of foundation models, such as SD-DINO, that can detect semantically similar keypoints of objects. We evaluate our framework on real-robot experiments, including screwing, pouring, and spatula scraping tasks, and demonstrate robust and versatile controller transfer for each.
Leveraging Simulation-Based Model Preconditions for Fast Action Parameter Optimization with Multiple Models
Mar 17, 2024Optimizing robotic action parameters is a significant challenge for manipulation tasks that demand high levels of precision and generalization. Using a model-based approach, the robot must quickly reason about the outcomes of different actions using a predictive model to find a set of parameters that will have the desired effect. The model may need to capture the behaviors of rigid and deformable objects, as well as objects of various shapes and sizes. Predictive models often need to trade-off speed for prediction accuracy and generalization. This paper proposes a framework that leverages the strengths of multiple predictive models, including analytical, learned, and simulation-based models, to enhance the efficiency and accuracy of action parameter optimization. Our approach uses Model Deviation Estimators (MDEs) to determine the most suitable predictive model for any given state-action parameters, allowing the robot to select models to make fast and precise predictions. We extend the MDE framework by not only learning sim-to-real MDEs, but also sim-to-sim MDEs. Our experiments show that these sim-to-sim MDEs provide significantly faster parameter optimization as well as a basis for efficiently learning sim-to-real MDEs through finetuning. The ease of collecting sim-to-sim training data also allows the robot to learn MDEs based directly on visual inputs and local material properties.
Estimating Material Properties of Interacting Objects Using Sum-GP-UCB
Oct 18, 2023Robots need to estimate the material and dynamic properties of objects from observations in order to simulate them accurately. We present a Bayesian optimization approach to identifying the material property parameters of objects based on a set of observations. Our focus is on estimating these properties based on observations of scenes with different sets of interacting objects. We propose an approach that exploits the structure of the reward function by modeling the reward for each observation separately and using only the parameters of the objects in that scene as inputs. The resulting lower-dimensional models generalize better over the parameter space, which in turn results in a faster optimization. To speed up the optimization process further, and reduce the number of simulation runs needed to find good parameter values, we also propose partial evaluations of the reward function, wherein the selected parameters are only evaluated on a subset of real world evaluations. The approach was successfully evaluated on a set of scenes with a wide range of object interactions, and we showed that our method can effectively perform incremental learning without resetting the rewards of the gathered observations.
Generative Adversarial Networks with Conditional Neural Movement Primitives for An Interactive Generative Drawing Tool
Dec 21, 2021

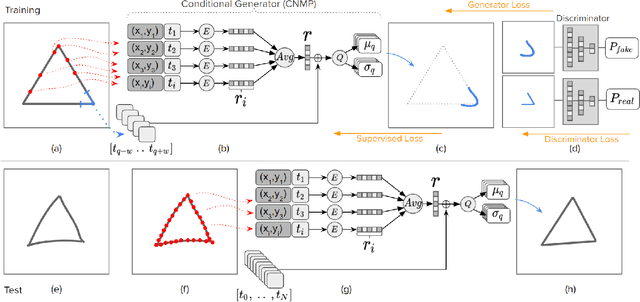
Sketches are abstract representations of visual perception and visuospatial construction. In this work, we proposed a new framework, Generative Adversarial Networks with Conditional Neural Movement Primitives (GAN-CNMP), that incorporates a novel adversarial loss on CNMP to increase sketch smoothness and consistency. Through the experiments, we show that our model can be trained with few unlabeled samples, can construct distributions automatically in the latent space, and produces better results than the base model in terms of shape consistency and smoothness.
DeepSym: Deep Symbol Generation and Rule Learning from Unsupervised Continuous Robot Interaction for Planning
Dec 04, 2020Autonomous discovery of discrete symbols and rules from continuous interaction experience is a crucial building block of robot AI, but remains a challenging problem. Solving it will overcome the limitations in scalability, flexibility, and robustness of manually-designed symbols and rules, and will constitute a substantial advance towards autonomous robots that can learn and reason at abstract levels in open-ended environments. Towards this goal, we propose a novel and general method that finds action-grounded, discrete object and effect categories and builds probabilistic rules over them that can be used in complex action planning. Our robot interacts with single and multiple objects using a given action repertoire and observes the effects created in the environment. In order to form action-grounded object, effect, and relational categories, we employ a binarized bottleneck layer of a predictive, deep encoder-decoder network that takes as input the image of the scene and the action applied, and generates the resulting object displacements in the scene (action effects) in pixel coordinates. The binary latent vector represents a learned, action-driven categorization of objects. To distill the knowledge represented by the neural network into rules useful for symbolic reasoning, we train a decision tree to reproduce its decoder function. From its branches we extract probabilistic rules and represent them in PPDDL, allowing off-the-shelf planners to operate on the robot's sensorimotor experience. Our system is verified in a physics-based 3d simulation environment where a robot arm-hand system learned symbols that can be interpreted as 'rollable', 'insertable', 'larger-than' from its push and stack actions; and generated effective plans to achieve goals such as building towers from given cubes, balls, and cups using off-the-shelf probabilistic planners.
Adaptive Conditional Neural Movement Primitives via Representation Sharing Between Supervised and Reinforcement Learning
Mar 25, 2020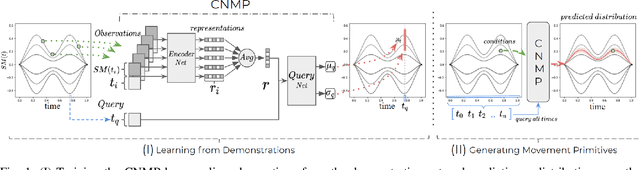
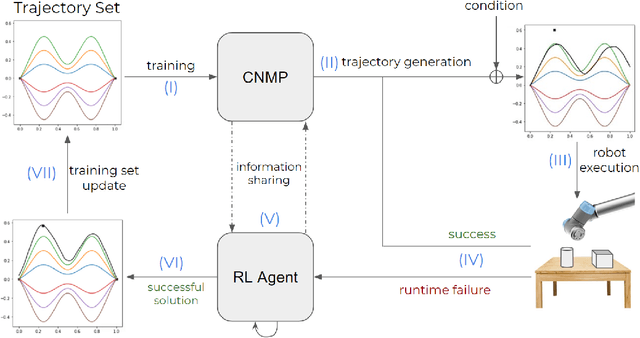
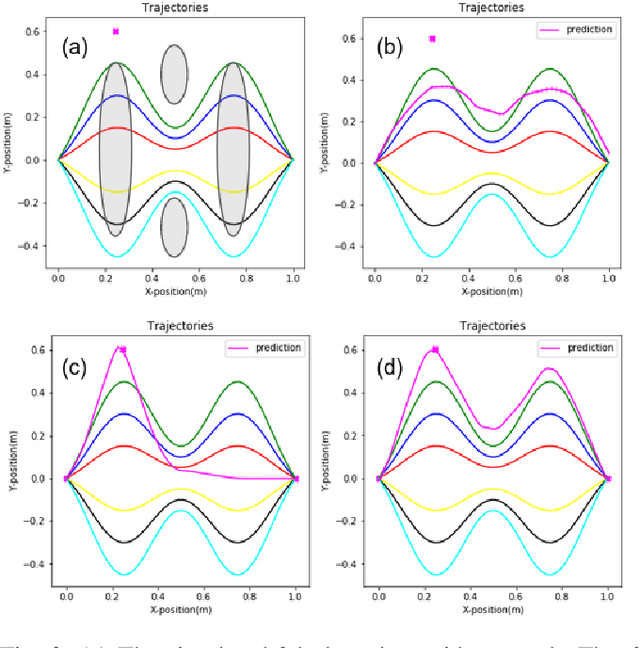
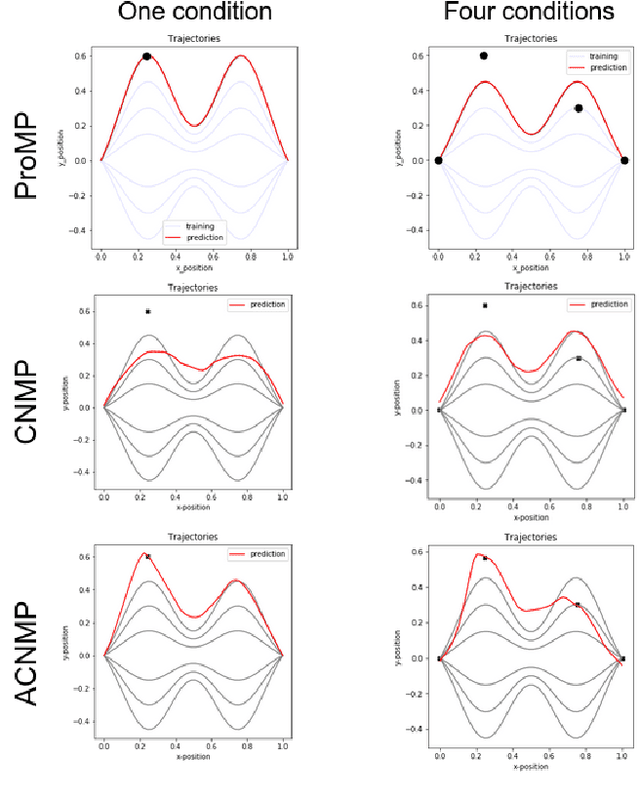
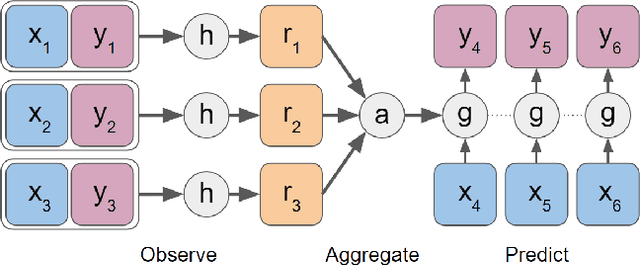
Learning by Demonstration provides a sample efficient way to equip robots with complex sensorimotor skills in supervised manner. Several movement primitive representations can be used for flexible motor representation and learning. A recent state-of-the art approach is Conditional Neural Movement Primitives (CNMP) that can learn non-linear relations between environment parameters and complex multi-modal trajectories from a few expert demonstrations by forming powerful latent space representations. In this study, to improve the applicability of CNMP to changing tasks and/or environments, we couple it with a reinforcement learning agent that exploits the formed representations by the original CNMP network, and learns to generate synthetic demonstrations for further learning. This enables the CNMP network to generalize to new environments by adapting its internal representations. In the current implementation, the reinforcement learning agent is triggered when a failure in task execution is detected, and the CNMP is trained with the newly discovered demonstration (trajectory), which shares essential characteristics with the original demonstrations due to the representation sharing. As a result, the overall system increases its capacity and handle situations in scenarios where the initial CNMP network can not produce a useful trajectory. To show the validity of our proposed model, we compare our approach with original CNMP work and other movement primitives approaches. Furthermore, we presents the experimental results from the implementation of the proposed model on real robotics setups, which indicate the applicability of our approach as an effective adaptive learning by demonstration system.
Belief Regulated Dual Propagation Nets for Learning Action Effects on Articulated Multi-Part Objects
Sep 18, 2019

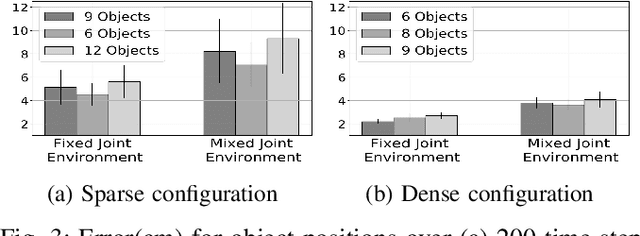
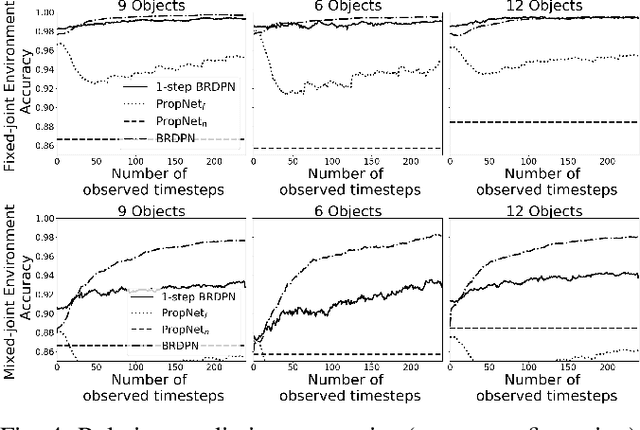
In recent years, graph neural networks have been successfully applied for learning the dynamics of complex and partially observable physical systems. However, their use in therobotics domain is, to date, still limited. In this paper, we introduce Belief Regulated Dual Propagation Networks (BRDPN), a general purpose learnable physics engine, which enables a robot to predict the effects of its actions in scenes containing groups of articulated multi-part objects. Specifically, our framework extends the recently proposed propagation networks (PropNets) and consists of two complementary components, a physics predictor and a belief regulator. While the former predicts the future states of the object(s) manipulated by the robot, the latter constantly corrects the robots knowledge regarding the objects and their relations. Our results showed that after trained in a simulator, the robot could reliably predict the consequences of its actions in object trajectory level and exploit its own interaction experience to correct its belief about the state of the world, enabling better predictions in partially observable environments. Furthermore, the trained model was transferred to the real world and its capabilities were verified in correctly predicting trajectories of pushed interacting objects whose joint relations were initially unknown. We compared our BRDPN against the original PropNets and showed that BRDPN can perform consistently well even if the relations between the objects are not explicitly given but instead predicted from observations.