 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictability-Based Curiosity-Guided Action Symbol Discovery
May 23, 2025Discovering symbolic representations for skills is essential for abstract reasoning and efficient planning in robotics. Previous neuro-symbolic robotic studies mostly focused on discovering perceptual symbolic categories given a pre-defined action repertoire and generating plans with given action symbols. A truly developmental robotic system, on the other hand, should be able to discover all the abstractions required for the planning system with minimal human intervention. In this study, we propose a novel system that is designed to discover symbolic action primitives along with perceptual symbols autonomously. Our system is based on an encoder-decoder structure that takes object and action information as input and predicts the generated effect. To efficiently explore the vast continuous action parameter space, we introduce a Curiosity-Based exploration module that selects the most informative actions -- the ones that maximize the entropy in the predicted effect distribution. The discovered symbolic action primitives are then used to make plans using a symbolic tree search strategy in single- and double-object manipulation tasks. We compare our model with two baselines that use different exploration strategies in different experiments. The results show that our approach can learn a diverse set of symbolic action primitives, which are effective for generating plans in order to achieve given manipulation goals.
Symbolic Manipulation Planning with Discovered Object and Relational Predicates
Jan 02, 2024



Discovering the symbols and rules that can be used in long-horizon planning from a robot's unsupervised exploration of its environment and continuous sensorimotor experience is a challenging task. The previous studies proposed learning symbols from single or paired object interactions and planning with these symbols. In this work, we propose a system that learns rules with discovered object and relational symbols that encode an arbitrary number of objects and the relations between them, converts those rules to Planning Domain Description Language (PDDL), and generates plans that involve affordances of the arbitrary number of objects to achieve tasks. We validated our system with box-shaped objects in different sizes and showed that the system can develop a symbolic knowledge of pick-up, carry, and place operations, taking into account object compounds in different configurations, such as boxes would be carried together with a larger box that they are placed on. We also compared our method with the state-of-the-art methods and showed that planning with the operators defined over relational symbols gives better planning performance compared to the baselines.
Discovering Predictive Relational Object Symbols with Symbolic Attentive Layers
Sep 02, 2023In this paper, we propose and realize a new deep learning architecture for discovering symbolic representations for objects and their relations based on the self-supervised continuous interaction of a manipulator robot with multiple objects on a tabletop environment. The key feature of the model is that it can handle a changing number number of objects naturally and map the object-object relations into symbolic domain explicitly. In the model, we employ a self-attention layer that computes discrete attention weights from object features, which are treated as relational symbols between objects. These relational symbols are then used to aggregate the learned object symbols and predict the effects of executed actions on each object. The result is a pipeline that allows the formation of object symbols and relational symbols from a dataset of object features, actions, and effects in an end-to-end manner. We compare the performance of our proposed architecture with state-of-the-art symbol discovery methods in a simulated tabletop environment where the robot needs to discover symbols related to the relative positions of objects to predict the observed effect successfully. Our experiments show that the proposed architecture performs better than other baselines in effect prediction while forming not only object symbols but also relational symbols. Furthermore, we analyze the learned symbols and relational patterns between objects to learn about how the model interprets the environment. Our analysis shows that the learned symbols relate to the relative positions of objects, object types, and their horizontal alignment on the table, which reflect the regularities in the environment.
Developmental Scaffolding with Large Language Models
Sep 02, 2023



Exploratoration and self-observation are key mechanisms of infant sensorimotor development. These processes are further guided by parental scaffolding accelerating skill and knowledge acquisition. In developmental robotics, this approach has been adopted often by having a human acting as the source of scaffolding. In this study, we investigate whether Large Language Models (LLMs) can act as a scaffolding agent for a robotic system that aims to learn to predict the effects of its actions. To this end, an object manipulation setup is considered where one object can be picked and placed on top of or in the vicinity of another object. The adopted LLM is asked to guide the action selection process through algorithmically generated state descriptions and action selection alternatives in natural language. The simulation experiments that include cubes in this setup show that LLM-guided (GPT3.5-guided) learning yields significantly faster discovery of novel structures compared to random exploration. However, we observed that GPT3.5 fails to effectively guide the robot in generating structures with different affordances such as cubes and spheres. Overall, we conclude that even without fine-tuning, LLMs may serve as a moderate scaffolding agent for improving robot learning, however, they still lack affordance understanding which limits the applicability of the current LLMs in robotic scaffolding tasks.
Learning Multi-Object Symbols for Manipulation with Attentive Deep Effect Predictors
Aug 01, 2022


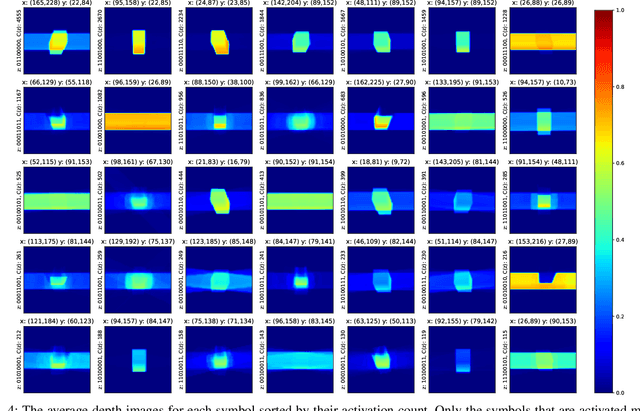
In this paper, we propose a concept learning architecture that enables a robot to build symbols through self-exploration by interacting with a varying number of objects. Our aim is to allow a robot to learn concepts without constraints, such as a fixed number of interacted objects or pre-defined symbolic structures. As such, the sought architecture should be able to build symbols for objects such as single objects that can be grasped, object stacks that cannot be grasped together, or other composite dynamic structures. Towards this end, we propose a novel architecture, a self-attentive predictive encoder-decoder network with binary activation layers. We show the validity of the proposed network through a robotic manipulation setup involving a varying number of rigid objects. The continuous sensorimotor experience of the robot is used by the proposed network to form effect predictors and symbolic structures that describe the interaction of the robot in a discrete way. We showed that the robot acquired reasoning capabilities to encode interaction dynamics of a varying number of objects in different configurations using the discovered symbols. For example, the robot could reason that (possible multiple numbers of) objects on top of another object would move together if the object below is moved by the robot. We also showed that the discovered symbols can be used for planning to reach goals by training a higher-level neural network that makes pure symbolic reasoning.
Graph2Pix: A Graph-Based Image to Image Translation Framework
Aug 22, 2021
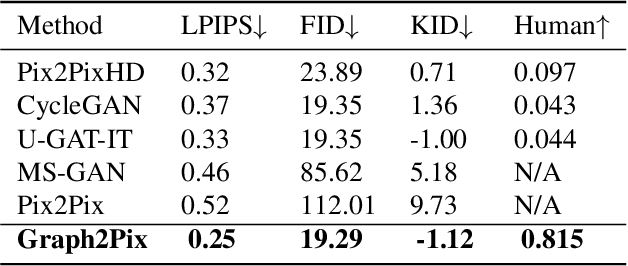
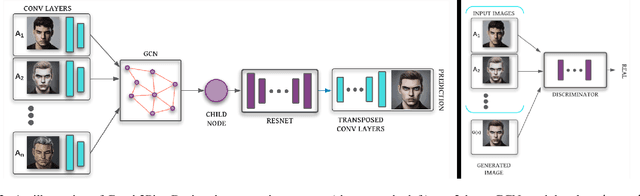
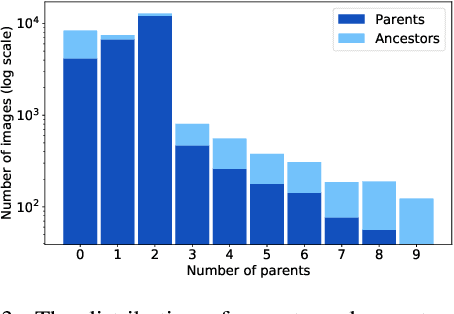
In this paper, we propose a graph-based image-to-image translation framework for generating images. We use rich data collected from the popular creativity platform Artbreeder (http://artbreeder.com), where users interpolate multiple GAN-generated images to create artworks. This unique approach of creating new images leads to a tree-like structure where one can track historical data about the creation of a particular image. Inspired by this structure, we propose a novel graph-to-image translation model called Graph2Pix, which takes a graph and corresponding images as input and generates a single image as output. Our experiments show that Graph2Pix is able to outperform several image-to-image translation frameworks on benchmark metrics, including LPIPS (with a 25% improvement) and human perception studies (n=60), where users preferred the images generated by our method 81.5% of the time. Our source code and dataset are publicly available at https://github.com/catlab-team/graph2pix.
High-level Features for Resource Economy and Fast Learning in Skill Transfer
Jun 18, 2021Abstraction is an important aspect of intelligence which enables agents to construct robust representations for effective decision making. In the last decade, deep networks are proven to be effective due to their ability to form increasingly complex abstractions. However, these abstractions are distributed over many neurons, making the re-use of a learned skill costly. Previous work either enforced formation of abstractions creating a designer bias, or used a large number of neural units without investigating how to obtain high-level features that may more effectively capture the source task. For avoiding designer bias and unsparing resource use, we propose to exploit neural response dynamics to form compact representations to use in skill transfer. For this, we consider two competing methods based on (1) maximum information compression principle and (2) the notion that abstract events tend to generate slowly changing signals, and apply them to the neural signals generated during task execution. To be concrete, in our simulation experiments, we either apply principal component analysis (PCA) or slow feature analysis (SFA) on the signals collected from the last hidden layer of a deep network while it performs a source task, and use these features for skill transfer in a new target task. We compare the generalization performance of these alternatives with the baselines of skill transfer with full layer output and no-transfer settings. Our results show that SFA units are the most successful for skill transfer. SFA as well as PCA, incur less resources compared to usual skill transfer, whereby many units formed show a localized response reflecting end-effector-obstacle-goal relations. Finally, SFA units with lowest eigenvalues resembles symbolic representations that highly correlate with high-level features such as joint angles which might be thought of precursors for fully symbolic systems.
DeepSym: Deep Symbol Generation and Rule Learning from Unsupervised Continuous Robot Interaction for Planning
Dec 04, 2020Autonomous discovery of discrete symbols and rules from continuous interaction experience is a crucial building block of robot AI, but remains a challenging problem. Solving it will overcome the limitations in scalability, flexibility, and robustness of manually-designed symbols and rules, and will constitute a substantial advance towards autonomous robots that can learn and reason at abstract levels in open-ended environments. Towards this goal, we propose a novel and general method that finds action-grounded, discrete object and effect categories and builds probabilistic rules over them that can be used in complex action planning. Our robot interacts with single and multiple objects using a given action repertoire and observes the effects created in the environment. In order to form action-grounded object, effect, and relational categories, we employ a binarized bottleneck layer of a predictive, deep encoder-decoder network that takes as input the image of the scene and the action applied, and generates the resulting object displacements in the scene (action effects) in pixel coordinates. The binary latent vector represents a learned, action-driven categorization of objects. To distill the knowledge represented by the neural network into rules useful for symbolic reasoning, we train a decision tree to reproduce its decoder function. From its branches we extract probabilistic rules and represent them in PPDDL, allowing off-the-shelf planners to operate on the robot's sensorimotor experience. Our system is verified in a physics-based 3d simulation environment where a robot arm-hand system learned symbols that can be interpreted as 'rollable', 'insertable', 'larger-than' from its push and stack actions; and generated effective plans to achieve goals such as building towers from given cubes, balls, and cups using off-the-shelf probabilistic planners.