 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-Object Symbols for Manipulation with Attentive Deep Effect Predictors
Paper and Code
Aug 01, 2022


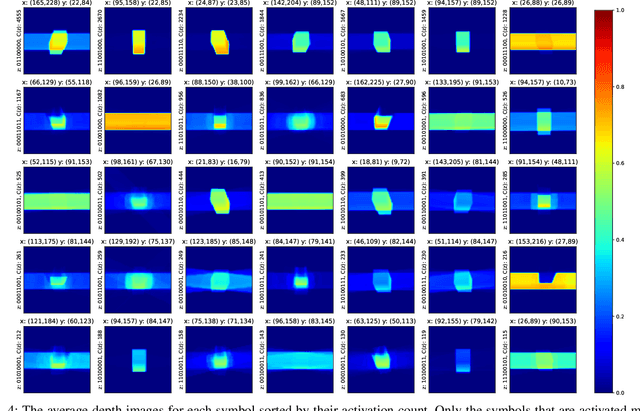
In this paper, we propose a concept learning architecture that enables a robot to build symbols through self-exploration by interacting with a varying number of objects. Our aim is to allow a robot to learn concepts without constraints, such as a fixed number of interacted objects or pre-defined symbolic structures. As such, the sought architecture should be able to build symbols for objects such as single objects that can be grasped, object stacks that cannot be grasped together, or other composite dynamic structures. Towards this end, we propose a novel architecture, a self-attentive predictive encoder-decoder network with binary activation layers. We show the validity of the proposed network through a robotic manipulation setup involving a varying number of rigid objects. The continuous sensorimotor experience of the robot is used by the proposed network to form effect predictors and symbolic structures that describe the interaction of the robot in a discrete way. We showed that the robot acquired reasoning capabilities to encode interaction dynamics of a varying number of objects in different configurations using the discovered symbols. For example, the robot could reason that (possible multiple numbers of) objects on top of another object would move together if the object below is moved by the robot. We also showed that the discovered symbols can be used for planning to reach goals by training a higher-level neural network that makes pure symbolic reasoning.